

I. 서 론
최근 음성인식 성능이 많이 향상되었지만, 훈련 환경과 테스트 환경의 불일치는 여전히 음성인식 성능 저하의 주요한 요인이다. 이러한 환경 불일치 문제를 해결하기 위해서 많은 연구가 진행되었는데, 특징 영역 및 모델 영역에서의 보상 방식들로 크게 분류할 수 있다.[1] 이 중 특징영역에서의 보상 방식은 비교적 계산량이 적고, 음성인식 엔진에 독립적으로 사용할 수 있다는 장점을 가진다. 본 논문에서는 다양한 특징 보상 방식 중 음성인식 분야에서 가장 널리 사용되고 있는 CMN과 CMVN 방식을 이용한다.[1] CMN은 음성 켑스트럼에서 장구간 켑스트럼 평균을 빼주는 경우, 미지의 채널 특성이 제거되는 성질을 이용한다. 하지만 켑스트럼의 평균에는 채널 특성 이외에 음성 자체의 켑스트럼 평균도 포함되어 있고, 입력 발화가 포함하는 어휘에 따라 켑스트럼의 평균이 달라진다. 또한 켑스트럼의 분산 역시 발화의 길이가 짧을수록 추정치의 편차가 커져서 추정치의 신뢰도가 떨어지게 된다.
본 논문에서는 이러한 문제를 완화시키기 위해서 평균 추정 개선용으로 극점 필터링[2]을, 분산 정규화 대신 스케일 정규화[3]를 적용한다. 극점 필터링은 선형예측 켑스트럼 계수(Linear Predictive Cepstral Coefficient, LPCC)에 CMN을 적용 시, 채널 성분 추정의 정확도 향상을 위해 제안되었고, 본 논문에서는 이를 MFCC에 적용하고 CMVN을 포함한 다른 정규화 방식에도 도입한다. 스케일 정규화 방식은 화자인식의 특징 정규화를 위해 제안되었는데, 본 논문에서는 이를 잡음 환경 음성인식의 특징 정규화에 도입하여, 짧은 발화에서 발생하는 분산 추정 문제를 해결하고자 한다.
II. 극점 필터링된 켑스트럼 정규화
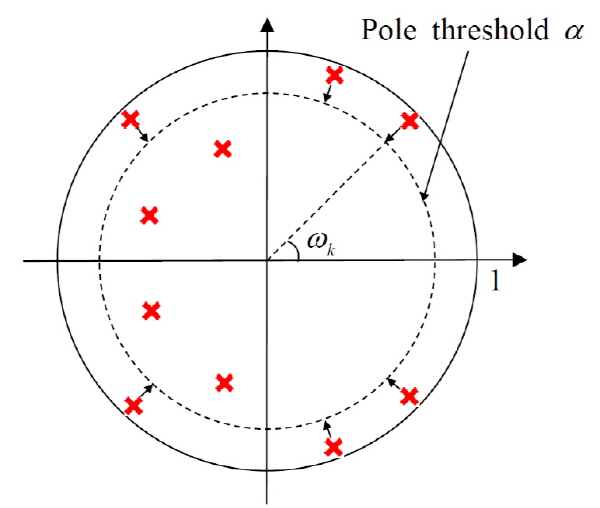
LPCC에서 CMN으로 채널 특성을 추정할 때, 극점 필터링은 켑스트럼 평균에 포함된 음성 성분을 감쇠시킴으로써 채널 특성 추정의 정확도를 향상시키는 것으로 알려져 있다.[2] 음성에 대한 전극(all-pole) 모델에서의 극점을 Fig. 1과 같이 극좌표로 나타냈을 때, 단위원에 근접한 협대역 극점은 현저한 포먼트(formant)를 나타내는 음성 성분의 주요 특성이다. 발화의 길이가 짧은 경우, 발화에 포함된 음소의 종류가 적기 때문에 켑스트럼 평균에 대해 특정 모음의 영향이 커지는 문제가 발생한다. 극점 필터링은 협대역 극점의 대역폭을 확장시킴으로써 해당 극점의 주파수 대역의 스펙트럼을 평활화하여 채널 특성 추정 시 음성 성분의 영향을 감쇠시킨다. 극점 필터링의 구체적인 구현 방식은 2가지가 있는데, 먼저 Fig. 1에서 보는 바와 같이 1보다 작은 임계값 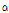 보다 크기가 큰 극점들에 대해서만 주파수는 유지하면서 그 크기를
보다 크기가 큰 극점들에 대해서만 주파수는 유지하면서 그 크기를  로 변경시켜서 해당 극점의 대역폭을 넓게 보정하는 방식이 있다.[2] 극점 필터링의 또 다른 구현 방법으로는 모든 극점의 대역폭을 일률적으로 넓히는 방법으로, 모든 극점에 대해서 주파수는 유지하면서 그 크기에 1보다 작은
로 변경시켜서 해당 극점의 대역폭을 넓게 보정하는 방식이 있다.[2] 극점 필터링의 또 다른 구현 방법으로는 모든 극점의 대역폭을 일률적으로 넓히는 방법으로, 모든 극점에 대해서 주파수는 유지하면서 그 크기에 1보다 작은  를 곱해서 모든 극점의 대역폭을 넓게 보정한다(
를 곱해서 모든 극점의 대역폭을 넓게 보정한다( ).[2]
).[2] 차 LPCC는 극점
차 LPCC는 극점 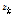 를 이용하여 다음과 같이 구할 수 있고,[4]
를 이용하여 다음과 같이 구할 수 있고,[4]
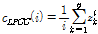 , (1)
, (1)
극점 필터링된 극점 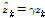 를 Eq.(1)의
를 Eq.(1)의 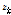 에 대입하면 극점 필터링된 결과는
에 대입하면 극점 필터링된 결과는
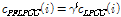 (2)
(2)
이 된다. 이 방법은 계산량 면에서 매우 유리하고, 더욱이 동일한 아이디어를 LPCC가 아닌 다른 켑스트럼 계수들에도 적용할 수 있다는 장점을 지닌다. 일반적으로 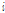 번째 켑스트럼 계수에
번째 켑스트럼 계수에 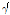 를 곱해주는 것은 켑스트럼 리프터(lifter) 기술의 일종으로서, 고차 켑스트럼을 더 많이 감쇠시켜 스펙트럼을 평활화시키는 효과를 얻는다.
를 곱해주는 것은 켑스트럼 리프터(lifter) 기술의 일종으로서, 고차 켑스트럼을 더 많이 감쇠시켜 스펙트럼을 평활화시키는 효과를 얻는다.
따라서 본 논문에서는 두 번째 극점 필터링 방법을 음성인식에 가장 널리 사용되는 MFCC 특징에 적용한다. 또한 CMN 이외에 CMVN에도 극점 필터링을 함께 도입하여 이들 각각을 Pole-Filtered CMN (PFCMN) 및 Pole-Filtered CMVN(PFCMVN)이라고 명명한다. 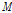 개의 프레임으로 구성된 발화의 특징벡터 열
개의 프레임으로 구성된 발화의 특징벡터 열 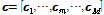 에서
에서 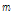 번째 프레임의 특징벡터에 해당하는
번째 프레임의 특징벡터에 해당하는 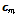 의
의 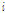 번째 성분의 값을
번째 성분의 값을 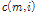 라고 나타낼 때, PFCMN과 PFCMVN은 각각 아래 Eqs.(3)과 (4)와 같다.
라고 나타낼 때, PFCMN과 PFCMVN은 각각 아래 Eqs.(3)과 (4)와 같다.
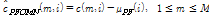 , (3)
, (3)
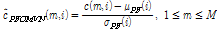 , (4)
, (4)
여기서 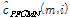 과
과  은 각각 PFCMN과 PFCMVN 결과로 얻어진
은 각각 PFCMN과 PFCMVN 결과로 얻어진 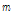 번째 프레임 특징벡터의
번째 프레임 특징벡터의 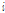 번째 성분이다. 그리고,
번째 성분이다. 그리고, 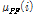 와
와 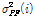 는 각각 원래 특징벡터의
는 각각 원래 특징벡터의 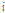 번째 성분에 극점 필터링을 수행했을 때의 평균과 분산이고, 각각
번째 성분에 극점 필터링을 수행했을 때의 평균과 분산이고, 각각
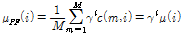 , (5)
, (5)
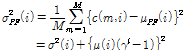 (6)
(6)
이다. 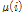 와
와 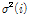 는 각각 특징벡터의
는 각각 특징벡터의 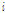 번째 성분에 해당하는 평균과 분산이다.
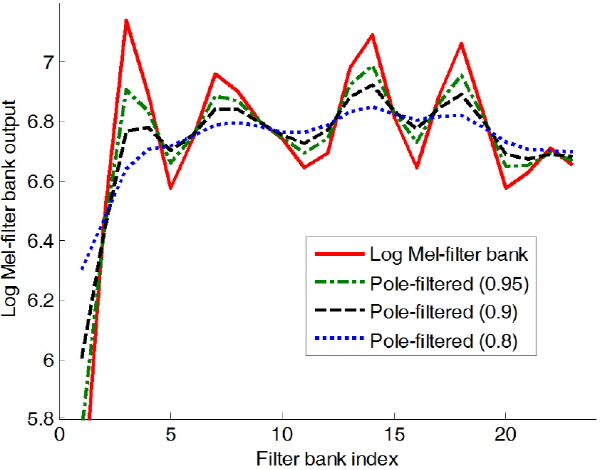
번째 성분에 해당하는 평균과 분산이다. 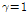 일 경우, Eqs.(3)과 (4)는 기존의 CMN 및 CMVN의 식과 동일해진다. Fig. 2는 MFCC 특징벡터의 평균에 해당하는 로그 멜-필터뱅크 출력과 이를 극점 필터링한 결과를 나타낸 것인데,
일 경우, Eqs.(3)과 (4)는 기존의 CMN 및 CMVN의 식과 동일해진다. Fig. 2는 MFCC 특징벡터의 평균에 해당하는 로그 멜-필터뱅크 출력과 이를 극점 필터링한 결과를 나타낸 것인데,  가 작아질수록 극점에 해당하는 대역폭이 넓어지는 것을 관찰할 수 있다.
가 작아질수록 극점에 해당하는 대역폭이 넓어지는 것을 관찰할 수 있다.
III. 스케일 정규화
CMVN은 켑스트럼 특징의 동적 범위(dynamic range)를 정규화하기 위해 특징 차원별 분산 값을 1로 만들어주는 정규화 방법을 사용한다. 그러나 잡음 환경에 따라 켑스트럼 특징의 분포 특성이 많이 달라지기 때문에, 분산 정규화를 하더라도 피크-투-피크(peak-to-peak) 범위가 동일해지는 것은 아니다. 특히 입력 발화의 길이가 짧을 경우 분산 추정의 신뢰도가 떨어지기 때문에 더더욱 피크-투-피크 범위 관점에서의 정규화 능력은 떨어지게 된다. Alam et al.[3]은 분산 정규화 대신에 피크-투-피크 범위를 직접적으로 정규화하는 스케일 정규화 방식을 제안하여 화자인식 실험에 적용였으며, 켑스트럼 특징의 평균과 스케일을 함께 정규화하는 방식을 Cepstral Mean and Scale Normalization(CMSN)이라 명명하였다. CMSN의 수식은 다음과 같다.
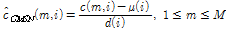 , (7)
, (7)
여기서 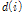 는 특징벡터의
는 특징벡터의 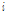 번째 성분의 피크-투- 피크 범위를 나타내며,
번째 성분의 피크-투- 피크 범위를 나타내며,
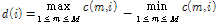 (8)
(8)
이다. CMSN이 잡음 환경 음성인식의 특징 정규화 용도로 사용된 예는 있으나,[5] 사실 잡음 환경 음성인식에서 분산 정규화와 스케일 정규화 중 어느 쪽이 더 효과적인지를 직접적으로 비교한 연구는 지금까지 없었던 것으로 파악된다. 따라서 본 논문에서는 잡음 환경 음성인식 실험을 통해 CMVN과 CMSN의 성능을 비교하였다. 또한 극점 필터링은 CMSN에도 적용 가능하므로, 본 논문에서는 Eq.(7)에서 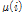 대신 Eq.(5)의
대신 Eq.(5)의 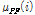 를 이용하는 방식을 제안하며, 이를 Pole-Filtered CMSN(PFCMSN)이라 명명하기로 한다.
를 이용하는 방식을 제안하며, 이를 Pole-Filtered CMSN(PFCMSN)이라 명명하기로 한다.
IV. 성능 평가
다양한 특징 정규화 방식들의 성능을 평가하기 위해 잡음과 채널 왜곡의 영향이 반영된 Aurora 2 평가 환경을 사용하였다.[6] Aurora 2 DB는 미국인 화자가 발성한 1 ~ 7자리의 연속 숫자로 구성된 Texas Instruments(TI) digit DB에 실제 환경의 잡음을 신호대잡음비 별로 더하고, 이를 International Telecommunication Union(ITU)에서 정의한 두개의 채널을 통과시킨 데이터이다. 특징 벡터는 12차 MFCC와 로그 에너지에 대한 각각의 델타, 델타-델타 파라미터를 포함하여 총 39차 특징을 사용하였다. 음향 모델로는 단어 단위의 은닉 마르코프 모델로 16개 상태의 left-to-right모델을 사용하였고, 각 상태당 가우스 혼합의 수는 3개이다. 음향 모델 훈련은 Aurora 2 DB에 정의된 clean–condition과 multi-condition DB를 사용하여 두 가지 모드로 훈련하였다.
| ||||
Fig. 3. Speech recognition rates of feature normaliza-tion using pole-filtering methods according to |
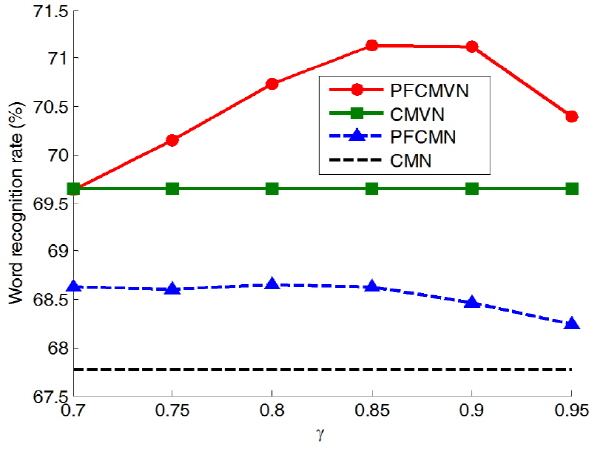
 .
.Fig. 3은 clean-condition 훈련 환경에서 극점 필터링을 적용했을 때,  에 따른 음성인식률을 나타낸 것이다. PFCMN과 PFCMVN은 각각
에 따른 음성인식률을 나타낸 것이다. PFCMN과 PFCMVN은 각각 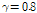 과
과 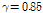 에서 최적의 인식률을 보이고, 기존의 CMN과 CMVN에 비해서 나은 성능을 보였다. Table 1과 Table 2는 각각 clean-condition 및 multi-condition 훈련환경에서 다양한 특징 정규화 방식들의 성능을 비교한 결과이다. PFCMN과 PFCMVN은 기존의 CMN과 CMVN에 비해서 약간의 성능 향상을 나타내고, CMSN은 기존 CMVN에 비해서 비교적 큰 폭의 성능 향상을 보였다. 특히 CMSN을 극점 필터링과 결합한 PFCMSN은 기존의 CMVN에 비해서 clean-condition 및 multi-condition 훈련환경에서 각각 24.9 %와 10.3 %의 오류 감소율을 얻었다.
에서 최적의 인식률을 보이고, 기존의 CMN과 CMVN에 비해서 나은 성능을 보였다. Table 1과 Table 2는 각각 clean-condition 및 multi-condition 훈련환경에서 다양한 특징 정규화 방식들의 성능을 비교한 결과이다. PFCMN과 PFCMVN은 기존의 CMN과 CMVN에 비해서 약간의 성능 향상을 나타내고, CMSN은 기존 CMVN에 비해서 비교적 큰 폭의 성능 향상을 보였다. 특히 CMSN을 극점 필터링과 결합한 PFCMSN은 기존의 CMVN에 비해서 clean-condition 및 multi-condition 훈련환경에서 각각 24.9 %와 10.3 %의 오류 감소율을 얻었다.
 )
) )
)