

I. 서 론
II. 제안하는 방법
2.1 동기
2.2 CNN을 위한 특징 추출 방법
2.3 CNN Architecture
III. 실 험
3.1 데이터베이스
3.2 실험 설정
3.3 실험 결과
IV. 토 의
V. 결 론
I. 서 론
멸종위기 종을 보호하고 자연 생태계를 보전하기 위해 해당 지역의 서식 종과 개체수를 파악하는 일이 매우 중요하다. 하지만 이러한 일을 수행할 수 있는 전문가가 적고 오랜 시간이 필요하기 때문에 적절한 시기에 적합한 조사를 수행하기 어렵다. 이러한 문제를 해결하기 위해 전문가를 대신하여 음향 신호를 분석하여 종을 식별하고 개체수를 파악할 수 있는 인공지능 시스템에 관한 연구가 진행되고 있다.
기존 연구에서 동물 울음소리 인식을 위한 특징 추출 알고리즘으로 MFCCs(Mel Frequency Cepstral Coefficients), RCGCC(Robust Compressive Gammachirp filterbank Cepstral Coefficients), SPCCs(Subspace Projection Cepstral Coefficients) 등이 있다. MFCC는 음성신호의 주파수 파워 스펙트로그램으로부터 특징을 추출하는데, 잡음과 같은 환경 변화에 민감하다.[1] RCGCC는 MFCC와 마찬가지로 스펙트로그램에서 특징을 추출하는데, 잡음 제거 과정이 추가되어 MFCC보다 환경 변화에 강인하다.[2] 하지만 SNR(Signal to Noise Ratio)이 낮은 경우에는 RCGCC의 성능을 장담하기 어렵다. SPCC는 신호에 대한 부공간으로 투영함으로써 잡음에 강인하다.[3] 이러한 특징을 바탕으로 인식을 수행하기 위해, SVM(Support Vector Machine),[4] GMM(Gaussian Mixture Model)[5]과 같은 인식기가 사용됐다.
최근에는 딥러닝 기반 알고리즘이 음성인식 알고리즘에 적용되고 있다. G. Hinton et al.은 DBN–DNN(Deep Belief Network-Deep Neural Network)와 같은 딥러닝 기반의 알고리즘을 음성인식에 적용했다.[6] 또한, 동물 울음소리 인식에서는 음의 높이, 에너지, 주기, 박자와 같은 특징과 더불어 MFCC와 같은 특징을 추출하여 DNN을 학습시킨 연구 결과가 있다.[7,8] 이와 같은 심층신경망을 학습하기 위해서는 대량의 학습데이터가 필요하지만, 동물 울음소리를 자연 환경에서 직접 수집하는 상황에서 대량의 데이터를 수집하는데 어려움이 있다. 수많은 변수를 학습해야 하는 심층신경망에서 학습데이터의 부족은 곧 과학습으로 이어져, 학습데이터 이외의 데이터에서 인식 성능을 보장할 수 없다. 한편, CNN(Convolutional Neural Network)은 영상 필터를 영상 전체가 공유하기 때문에 학습해야할 변수가 적고, 과적합을 방지할 수 있다. 이러한 장점에 근거하여 본 논문에서는 convolutional layer의 출력 크기를 동일시하기 위해 입력 신호의 크기를 정형화하는 과정이 필요하다. 이러한 정형화 과정에서 2차원 신호의 공분산 행렬을 이용하면 높은 인식 성능을 보인다는 연구 결과가 있다.[9] 이를 바탕으로 본 논문에서는 CNN에 1차원 신호인 동물 울음소리를 적용하기 위해 2차원 신호인 이미지로 변환하는 과정을 제안하고, CNN의 convolutional layer와 fully-connected layer 수를 변경해가며 인식 성능을 비교했다.
이후 논문은 II장 제안하는 방법, III장 실험, IV장 토의, V장 결론으로 구성된다.
II. 제안하는 방법
2.1 동기
CNN을 학습시키기 위해서는 입력의 크기가 모두 같아야한다. 그러나 동물 울음소리의 경우 그 길이가 모두 달라 입력을 정형화하는 과정이 필요하다. 이미 이미지 인식에서 데이터의 분포를 의미하는 공분산 행렬을 이용하여 벡터 공간에 투영할 경우, 높은 인식 성능을 보인다는 연구결과가 있다.[9] 하지만 공분산 행렬은 분포에 대한 정보를 나타낼 뿐, 시간에 대한 변화를 내포하지는 않는다. 이러한 문제점을 보완하기 위해 본 논문에서는 동물 울음소리의 스펙트로그램에서 모듈로그램(modulogram)을 추가적으로 추출하여 공분산 행렬과 같이 입력으로 사용하는 방법을 생각했다.
2.2 CNN을 위한 특징 추출 방법
Fig. 1은 동물 울음소리를 2차원 데이터로 변환하는 과정을 보여준다. 먼저 1차원 동물 울음소리에 STFT(Short Time Fourier Transform)을 적용하여 스펙트로그램으로 변환한다. 이때 프레임 길이는 2048 point로 설정하였고, 50 % 중첩하여 다음 프레임을 설정했다. 추출한 스펙트로그램에 64개의 Gammatone filterbank를 적용하여 부분대역 전력을 추출했다. 이때 첫 번째 2차원 특징으로 부분대역 전력에 대한 공분산 행렬을 사용했다.

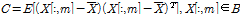 . (1)
. (1)
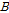 는 Gammatone filter를 적용하여 획득한 부분대역 전력의 집합이다.
는 Gammatone filter를 적용하여 획득한 부분대역 전력의 집합이다. 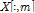 과
과 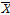 는 각각 부분대역 전력의 m번째 열의 값과 부분대역 전력의 기댓값을 의미한다.
는 각각 부분대역 전력의 m번째 열의 값과 부분대역 전력의 기댓값을 의미한다. 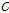 는 부분대역 전력의 공분산 행렬이다. 공분산 행렬은 부분대역 전력에 따른 에너지 분포도를 의미하지만 시간에 대한 변화도를 반영할 수 없다. 이를 보완하기 위해, 각 부분대역의 전력 변화를 분석하기 위해 128 point의 FFT를 적용하여 모듈로그램을 두 번째 특징으로 사용했다.
는 부분대역 전력의 공분산 행렬이다. 공분산 행렬은 부분대역 전력에 따른 에너지 분포도를 의미하지만 시간에 대한 변화도를 반영할 수 없다. 이를 보완하기 위해, 각 부분대역의 전력 변화를 분석하기 위해 128 point의 FFT를 적용하여 모듈로그램을 두 번째 특징으로 사용했다.
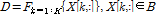 . (2)
. (2)
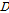 는 부분대역 전력의 모듈로그램을 의미한다. K는 주파수 구간의 수이고, k는 해당 주파수 인덱스를 뜻한다. 이 두 특징이 CNN으로 입력되기 위해 두 특징을 채널로 연결하여 64 × 64 × 2의 데이터를 구축했다.
는 부분대역 전력의 모듈로그램을 의미한다. K는 주파수 구간의 수이고, k는 해당 주파수 인덱스를 뜻한다. 이 두 특징이 CNN으로 입력되기 위해 두 특징을 채널로 연결하여 64 × 64 × 2의 데이터를 구축했다.
2.3 CNN Architecture
Fig. 2는 공분산 행렬과 모듈로그램 기반 울음소리 인식을 위한 CNN의 구조를 보여준다. 그림에서 보듯이, CNN의 구조는 convolutional layer 5개와 fully-connected layer 2개를 사용하는 AlexNet으로 구성했다.[10] convolutional filter의 크기는 3 × 3으로 모두 동일하게 적용했고, stride는 1로 했다. 데이터의 크기가 줄어드는 것을 방지하기 위하여 데이터에 zero-pad-ding을 했다. 첫 번째, 두 번째 그리고 마지막 convolu-tional layer 뒤에는 max-pooling layer를 사용했다. max-pooling filter의 크기는 2 × 2이고, stride는 2로 하여 max-pooling layer의 출력을 가로 세로 모두 입력의 절반이 된다. 첫 번째 convolutional layer와 max-pooling layer는 64 × 64 × 2 크기의 데이터를 입력을 받아 32 × 32 × 32 크기의 데이터를 출력한다. 두 번째 convolutional layer와 max-pooling layer는 32 × 32 × 32 크기의 데이터를 입력받아 16 × 16 × 64 크기의 데이터를 출력한다. 세 번째 convolutional layer는 max-pooling layer와 연결되지 않고, 16 × 16 × 128 크기의 데이터를 출력한다. 네 번째 convolutional layer는 세 번째 convolutional layer와 마찬가지로 max-pooling layer와 연결되지 않고, 입력과 동일한 크기인 16 × 16 × 128 크기의 데이터를 출력한다. 다섯 번째 convolutional layer와 max-pooling layer는 16 × 16 × 128의 크기의 데이터를 입력 받아 8 × 8 × 128 크기의 데이터를 출력한다. 마지막 max-pooling layer에서 출력된 데이터는 fully-connected layer와 연결된다. 8 × 8 × 128 크기의 데이터를 fully-connected layer의 입력으로 받아 625 크기의 데이터를 출력한다. 두 번째 fully-connected layer는 625 크기의 데이터를 입력 받아 같은 크기의 데이터를 output layer로 출력한다. output layer는 fully-conneted layer의 출력을 입력 받아 softmax로 9개 클래스 값을 출력한다.

Fully-connected layer가 CNN의 성능에 미치는 영향을 살펴보기 위해, convolutional layer는 고정하고 fully-connected layer의 수를 바꿔가며 동일한 실험을 반복했다. fully-connected layer의 수를 2개, 1개, 사용하지 않았을 때를 나눠 실험했다. fully-connected layer의 수가 1개일 때는 두 번째 fully-connected layer를 제거했다. fully-connected layer를 사용하지 않았을 때는 첫 번째와 두 번째 fully-connected layer를 모두 제거했고, output layer의 입력을 8 × 8 × 128로 했다.
다음으로 convolutional layer 수에 따른 CNN의 성능을 비교하기 위해 convolutional layer를 3개로 변경하여 실험했다. 이때 앞에서 언급한 CNN 구조에서 세 번째와 네 번째 convolutional layer를 제거했다. 이 경우에 fully-connected layer는 1개일 때와 사용하지 않았을 때를 성능을 테스트했고, 구조는 convolutional layer가 5개일 때와 동일하게 했다.
III. 실 험
3.1 데이터베이스
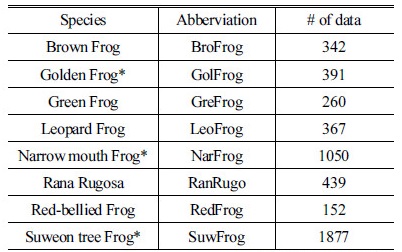
국내에 서식하고 있는 양서류 8종의 울음소리를 전문가의 도움으로 수집하여 데이터베이스를 구성했다(44.1 kHz, 단일 채널, 16 bit-resolution). 양서류 8종에는 금개구리(Golden Frog), 맹꽁이(Narrow mouth Frog), 수원청개구리(Suweon tree Frog)와 같은 멸종 위기 종을 포함한다. Table 1은 8종의 구체적인 개체 목록과 데이터의 수를 보여준다.
3.2 실험 설정
실험을 위해 데이터베이스를 총 5개로 나누었고, 이중 4개를 트레이닝 셋으로 사용하고 나머지 1개를 테스트 셋으로 사용하는 5-fold cross validation을 사용하였다. 데이터베이스를 나눌 때 5개의 세트별 클래스의 비율을 모두 동일하게 했다.
Fully-connected layer의 과적합을 피하기 위해 dropout을 0.5로 설정했다. 네트워크 학습에서 vanishing gradient 문제를 피하기 위해 ReLU 함수를 활성화 함수로 사용했고,[11] batch size는 100으로 했다.
CNN 성능을 비교하기 위해 음향분석에서 많이 쓰이는 MFCC, RCGCC, SPCC로 특징을 추출하고 SVM, GMM, DBN-DNN으로 특징을 분류하는 실험을 진행했다. MFCC의 멜 필터의 수는 40으로, RCGCC의 감마칩 필터는 80으로 설정했다. MFCC, RCGCC, SPCC 모두 델타와 가속도 계수를 이용하여 60차원의 특징 벡터를 얻었다. 각각의 특징 벡터들은 정규화하여 사용했다. SVM은 8개의 클래스를 구별하기 위해 8개의 분류함수를 훈련했다. GMM은 16개의 가우시안 혼합 모델을 사용헸다. DBN-DNN은 각각 200개의 노드로 이루어진 3개의 은닉층으로 구성했다. 최대 Epoch는 200, Batch size는 65로 설정했다.
3.3 실험 결과
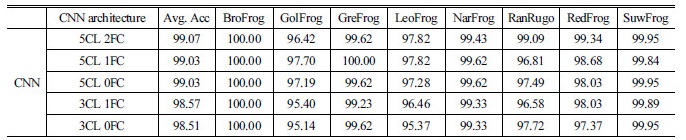
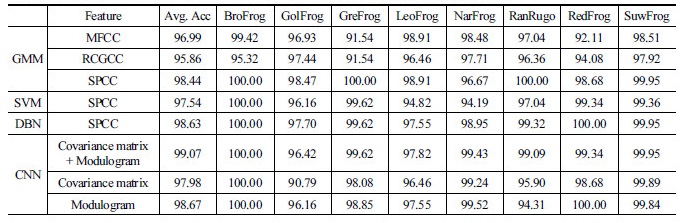
Table 2는 CNN의 구조를 변경하면서 진행한 실험의 결과를 정리한 것이다. CNN architecture에서 CL은 convolutional layer의 수를 의미하고, FC는 fully-connected layer의 수를 의미한다. Table 3은 기존의 음향 신호에 쓰이는 알고리즘으로 실험한 결과를 CNN과 비교한 것이다. CNN을 제외한 알고리즘에 대한 결과는 CNN과의 비교를 위해 정확도가 90 % 이상인 경우에만 정리했다.
Table 2에서 보면 CNN 구조에서 가장 높은 정확도를 보인 경우는 5개의 convolutional layer와 2개의 fully-connected layer를 사용하였을 때로 99.07 %의 정확도를 보였다. 그 다음으로는 convolutional layer를 5개 사용하고 fully-connected layer를 1개 사용한 경우와 fully-connected layer를 사용하지 않은 경우가 99.03 %의 정확도를 보였다. 3개의 convolutional layer를 사용하였을 경우 fully-connected layer가 1개일 때와 사용하지 않았을 때가 각각 98.57 %와 98.51 %였다.
Table 3에서 CNN을 제외하고 가장 높은 정확도를 보인 경우는 특징 추출 알고리즘으로 SPCC를 사용하고 분류 알고리즘을 DBN-DNN을 사용하였을 때가 98.63 %였다. 특징 추출 알고리즘으로 SPCC를 사용하고 특징 분류 알고리즘을 SVM을 사용하였을 때는 97.54 %였다. 특징 분류 알고리즘을 GMM으로 사용하였을 때 MFCC, RCGCC, SPCC의 정확도는 순서대로 96.99 %, 95.86 %, 98.44 %를 보였다. 공분산 행렬과 모듈로그램을 각각 따로 CNN의 입력으로 사용하였을 때에는 각각 97.98 %와 98.67 %의 정확도를 보였다. 두 특징을 동시에 사용하였을 때 정확도가 99.07 %로 특징을 따로 사용했을 때보다 높은 정확도를 보였다.
IV. 토 의
실험에서 여러 형태의 CNN과 알고리즘의 결과를 얻었다. 그 결과 5개의 convolutional layer로 이루어진 CNN이 99 % 이상의 정확도로 가장 높은 것을 알 수 있다. CNN을 제외하고 가장 높은 정확도를 보인 경우는 특징 추출 알고리즘으로 SPCC를 사용하고 특징 분류 알고리즘을 DBN-DNN을 사용하였을 때로 98.63 %의 정확도를 보였다. 3개의 convolutional layer를 사용하였을 경우에는 98.51 %~ 98.57 %의 정확도로 DBN-DNN을 사용하였을 때보다 약 0.1 % 낮은 정확도를 보였다. 이를 통하여 CNN을 사용하였을 때 기존의 음향분석에 쓰이는 알고리즘에 비해 비슷하거나 더 높은 성능을 보인다는 것을 도출할 수 있다.
5개의 convolutional layer로 이루어진 CNN의 경우 fully-connected layer가 2개일 때 99.07 %로 가장 높은 정확도를 보였다. fully-connected layer가 1개일 때와 없을 경우에는 모두 99.03 %의 정확도를 보였다. fully-connected layer가 2개일 때와 그렇지 않을 경우의 차이는 0.04 %로 큰 차이를 보이지 않았다. 3개의 convolutional layer로 이루어진 CNN의 경우에는 fully-connected layer가 있을 때 98.57 %, 없을 경우 98.51 % 였다. 이때 차이는 0.06 %로 마찬가지로 큰 차이를 보이지 않았다. 반면에 convolutional layer가 5개일 경우와 3개일 경우에는 0.46 %~ 0.56 %의 차이를 보였다. CNN의 성능은 fully-connected layer보다는 convolutional layer의 영향을 더 크게 받는다는 결론을 도출할 수 있다. 더 나아가, layer의 수가 증가할수록 학습해야하는 변수의 수가 기하급수적으로 증가하는 fully connected layer의 수에 상관없이 CNN의 성능이 비슷하다면, fully-connected layer가 없는 것이 과학습을 방지하고 연산과정을 최소화할 수 있다. 그렇기 때문에 동일한 convolutional layer 구조를 가진 CNN이 있을 때 fully-connected layer가 없는 CNN이 더 효율적이라는 결론을 얻을 수 있다.
V. 결 론
이 논문에서는 1차원 신호인 음향 신호를 정형화하기 위해 2차원 신호로 변환하는 방법을 제안하였고, CNN과 여러가지 알고리즘의 결과를 비교 분석했다. CNN의 성능을 비교하기 위해 기존에 음향분석에 쓰이는 특징 추출 알고리즘 MFCC, RCGCC, SPCC와 특징 분류 알고리즘 SVM, GMM, DBN-DNN을 동일한 데이터베이스를 이용하여 테스트했다. 그 결과, CNN이 기존의 알고리즘보다 더 높은 성능을 보인 것을 확인했다. 또한, 여러 가지 CNN의 구조를 실험을 통해 fully-connected layer보다 convolutional layer가 성능에 더 큰 영향을 미친다는 것을 확인했다. 추후 연구에서는 동물 종의 범위를 넓히고, 실제 환경을 반영하여 노이즈가 있는 상황에서의 실험을 진행할 예정이다.
