I. 서 론
II. 제안 알고리즘
2.1 노이즈 출력 간의 의존성과 목표 마스크 기반의 AuxIVA를 사용한 목표 음원 추출
2.2 ILRMA로의 확장
III. 실험 결과
IV. 결 론
I. 서 론
잡음 강인성은 음성 인식 분야에서 중요한 문제로 남아있는데, 이는 학습 환경과 시험 환경의 차이로 인해 음성 인식 시스템의 성능이 크게 떨어질 수 있기 때문이다. 이러한 차이를 보완하기 위해서 다양한 접근법들이 개발되어왔다.[1,2,3] 기존 방법들은 특정 상황에 대해서는 인식 성능을 향상시켰지만, 불규칙한 간섭이 포함되는 다양한 실제 환경에서도 인식 성능을 강인하게 유지하지는 못했다.[4] 다채널 마이크 신호가 있을 때, 잡음에 강인한 음성 인식을 위한 전처리로서 독립 성분 분석(Independent Component Analysis, ICA)에 기반한 다양한 방식들이 사용되고 있다. 이는 독립 성분 분석이 암묵 음원 분리(Blind Source Separation, BSS) 상황에서 좋은 성능을 내기 때문이다.[4,5,6,7,8,9,10] 반향을 포함한 혼합 신호는 주파수 축에서 독립 성분 분석(ICA)을 통해 통계적으로 독립인 음원들을 찾으며 분리할 수 있다. 하지만 이러한 ICA는 주파수축에서 출력 순서가 무작위로 뒤섞이는 문제가 있다. 이에 대한 해결책으로 제안된 독립 벡터 분석(Independent Vector Analysis, IVA)는 주파수 축에서 균일한 의존성을 주거나[11,12,13] 군집 단위로 의존성을 줌(Clique model)[14,15]으로써 사전 음원 정보를 모델링하여 효과적으로 음원 뒤섞임을 방지할 수 있다.
최적화 관점에서, 기대값-최대화 알고리즘의 확장으로서 빠르고 안정적인 업데이트가 가능한 보조 함수 기반 독립 벡터 분석(Auxiliary function-based IVA, AuxIVA) 기술이 발전하였다.[16,17] 게다가, 독립 단순 행렬 분석(Independent low-rank matrix analysis, ILRMA)은 각 음원별 스펙트로그램을 단순 행렬로 근사하여 주파수의 뒤섞임을 해결하는 동시에 좀 더 정확한 음원 모델을 학습할 수 있다. 이는 비음수 행렬 분해(Non-negative Matrix Factorization, NMF)[18,19]와 음원 간의 독립성[20,21]을 동시에 이용하여 이뤄진다. 최근에는 군집 분산 추정과 함께 inter-clique 의존 모델을 사용한 AuxIVA 또한 연구되었다. 이는 시간에 따라 다른 군집 분산을 사용하고, 합쳐진 군집의 지수를 달리하여 대부분의 기존 모델을 일반화하였다.[22]
하지만 어떤 채널의 출력 신호가 음성 인식에 사용돼야 하는지는 불분명한데, 일반적인 ICA에서 모든 채널에 대해 동일한 음원 모델이 사용되기 때문이다. 동일하게 음원이 모델링 되는 기존의 ICA/IVA에서 음성과 잡음 간의 음원 특성의 차이가 다뤄질 수 없기 때문에, 단일 채널 음원 분리에 의해 추정된 시간-주파수 분산을 기반으로 한 가우시안 모델이 사용되었다.[23] 반면에, 음성 인식 기술의 전처리는 잡음 분리와 관계없이 목표 음성만 강화하면 된다. 이에 따라 목표 음원 추출 기술이 목표 화자에 방향적 널 게인을 형성하도록 잡음 채널을 제한하여 잡음 분리 필터를 계산할 필요없이 목표 음성 신호를 얻어낼 수 있는 출력 필터를 추정함으로써 발전하였다. 특히 독립 성분 추출(Independent Component Extraction, ICE) 및 독립 벡터 추출(Independent Vector Extraction, IVE)은 분리 신호들이 직교성을 갖도록 제한을 두며 목표 음원을 추출한다. 이는 파일럿 신호를 사용해 채널의 모호성을 해결하여 목표 음원을 안정적으로 추출한다.[24,25]
둘러싼 잡음이 존재하는 실제 환경에서 잡음에 강인한 음성인식을 하기 위한 전처리 단계로서, 본 논문은 보조 함수 기반의 독립 벡터 분석 기법(AuxIVA)을 기반으로 가중 공분산 행렬에서 가중치를 목표 음성에 대한 마스크를 활용해 크기를 조절하는 목표 음성 추출 방법을 제안한다. 마스크는 음성 향상을 위해 학습된 신경망으로부터 추정할 수 있다. 미리 학습된 신경망 대신에, 본 논문은 마스크를 목표 화자로부터의 직선 성분의 기여도를 찾기 위한 확산성으로부터 추정하는 방식을 소개한다. 이때, 확산성은 마이크 쌍 간의 공간적 일관성을 기반으로 한 직진성 대 확산성 파워 비율(Coherent-to-Diffuse Ratio, CDR)로부터 추정된다. 출력 중 목표 음원을 제외하고, 다차원 독립 성분 분석(Multi-dimensional ICA)을 통해 둘러싼 잡음에 대한 출력들은 서로 연관성을 가지도록 모델링 한다.[26] 또한, 각 음원들의 시간-주파수 구조에서 단순 행렬 근사의 장점을 얻기 위해 다차원 잡음 출력에 대한 비음수 행렬 분해(Non-negative Matrix Factorization, NMF)를 비음수 텐서 분해(Non-negative Tensor Factorization, NTF)로 변경하여 ILRMA 구조로 확장한다.[27]
II. 제안 알고리즘
2.1 노이즈 출력 간의 의존성과 목표 마스크 기반의 AuxIVA를 사용한 목표 음원 추출
둘러싼 배경 잡음이 있는 실세계 환경에서, 번째 주파수 빈과 번째 프레임에서 개의 혼합 음성 관측 는
로 표현될 수 있으며 여기서 와 는 각각 대응되는 시간-주파수 음성 성분 및 목표 화자에서 관측으로의 번째 주파수 빈에서의 전달 함수를 가리킨다. 는 에서 노이즈 성분을 나타낸다. AuxIVA를 적용하기 위해서 분리 모델
를 고려한다. 이때 는 분리된 시간-주파수 출력 성분으로 구성되는 벡터이고 는 번째 주파수 빈에서의 분리 행렬이다. 는 목표 음성 추정 값이며 다른 성분은 노이즈 추정 값을 나타낸다.
음원의 변화하는 특성을 잡아내기 위해 음원 모델로 아래와 같이 시간에 따라 변화하는 가우시안 분포를 고려할 수 있다.[17,23]
여기서 는 번째 음원, 번째 주파수 빈, 번째 프레임에서 시간에 따라 변하는 분산을 의미한다. 이때, 번째 주파수 빈에 대한 보조 함수 [16]는
로 주어질 수 있다. 이때 는 의 번째 행 벡터이고 는
로 계산되는 가중 분산 행렬이다. 여기서 와 는 각각 프레임의 개수와 안정적인 의 추정을 위한 작은 바닥 양수 값이다. 는 0과 1사이의 값을 가지는 에 대한 신뢰 가중치를 나타낸다. 기존의 AuxIVA달리, Eq. (5)는 이러한 신뢰 가중치 를 포함하도록 설계하였다. 는 일반적으로 단위 행렬로 초기화되기 때문에, 는 초기 수렴과정에서 와 유사하다고 볼 수 있다. 더불어 최대 우도 기반 추정에 따라서 References [17],[22]와 비슷하게 로 주어진다. 이 경우에, 본 논문에서는 초기의 수렴단계에서 에 목표 음성을 얻고자 와 에 대해서 각각 와 을 사용하기를 제안한다. 여기서 는 관측 신호에서 왜곡되지 않은 목표 음성 성분의 상대적인 평균 파워의 기여도를 나타내는 마스크를 의미한다. 마스크는 음성 향상을 위해서 학습된 별도의 신경망으로의 출력 값을 제곱하여 얻을 수 있다.[28] 미리 학습이 된 신경망을 활용하는 대신, 는
로도 얻을 수 있다. 𝜅와 𝛽는 각각 기울기와 치우침 정도를 나타내는 파라미터이다. 여기서 는 목표 화자로부터 완전한 직진 소리 성분의 기여 정도를 찾고자 추정한 모든 마이크 쌍 에 대한 확산성 수치 들의 중간값을 나타내며,[29,30] 이는 같이 재귀적으로 계산되는 마이크 쌍의 correlation,
에 의해서 추정된다. 이때 는 0과 1사이의 값으로 설정하는 스무딩 팩터를 나타낸다. 이러한 correlation 로부터 coherence,
를 추정하여 이로부터 Reference [30]과 동일하게 를 추정할 수 있다.
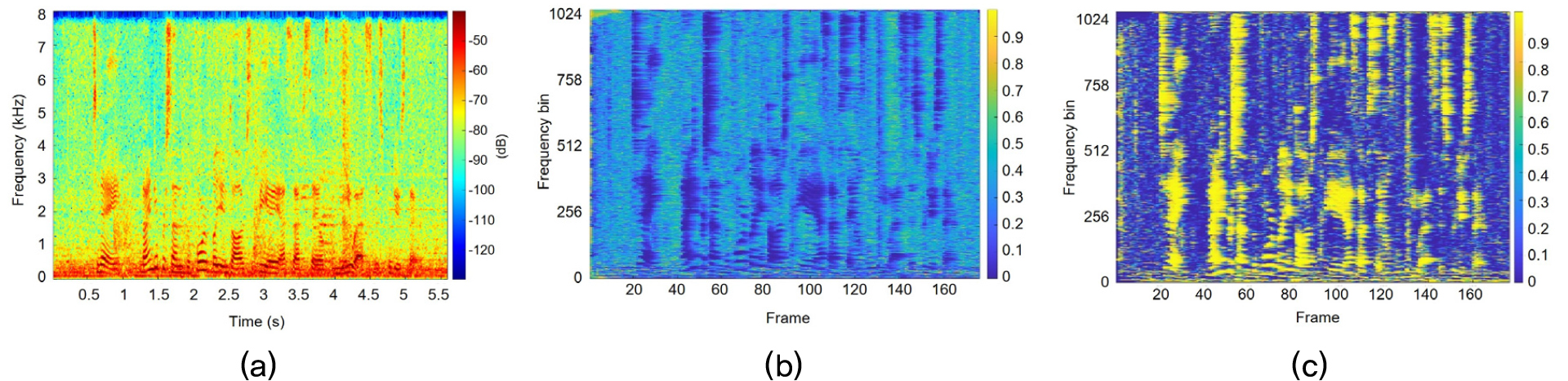
Fig. 1은 주어진 입력 신호에 대한 확산성 수치 추정 값과 이를 Eq. (6)을 거쳐서 얻어낸 목표 마스크를 나타낸 것이다. 이 확산성 기반의 목표 마스크는 입력 신호의 음성 성분을 효과적으로 추정하였음을 확인할 수 있다. 비록 목표 음성 분산의 추정은 위와 같이 이루어질 수 있으나, 각각의 개별적인 잡음들에 대한 분산 추정은 매우 까다롭다. 사실, 강인한 음성인식을 위한 전처리로서 유도하고자 하는 알고리즘은 개별적인 잡음원에 대한 분리를 필요로 하지 않는다. 본 논문에서는 둘러싼 배경 잡음 환경을 고려하기 때문에, 잡음 출력 은 서로 간에 의존성을 가질 수 있도록 하여도 무방하다. 그리고 이 분산들은 똑같다고 가정할 수 있고 이는 초기 수렴에서의 Eq. (3)의 음원 모델을 가지는 AuxIVA에 대해서 잡음에 대한 가중치는 아래와 같이 역 마스크 값으로 설정하고,
채널 별 분산 값은 잡음간 공유된 하나의 분산으로 가정하여 추정할 수 있다.
이러한 수식은 마치 IVA에서 주파수 성분 간에 그러하듯 잡음 출력 간의 의존성을 준다. 기존의 AuxIVA와 달리 Eq. (5)는 를 포함하기 때문에, 로 를 정규화 하여 이로 인해서 발생할 수 있는 의 과추정을 방지해줄 수 있다. 초기 수렴후에는, 는 더 나은 수렴을 위해 1로 바꿀 수 있다.
References [31],[32]에서, 는 각 주파수 빈 별로 인접 프레임의 출력 파워 간의 이동평균을 도입하여 음원 신호의 시간적 연속성을 향상시켜 추정의 정확도를 개선할 수 있다.
여기서 는 평균을 내고자 하는 프레임의 개수를 말한다. 한번 가 계산되면, 는 다른 벡터 를 고정한 채 순차적으로 를 아래와 같은 방식을 통해서 업데이트 된다. 업데이트 방식은 아래와 같다(References [16],[17],[22]와 유사함).
여기서 𝛿와 는 대각 성분 로딩을 위한 작은 양수 값과 번째 성분이 1에 해당에는 단위 벡터를 말한다.
2.2 ILRMA로의 확장
Eq. (3)의 음원 모델에 상호 주파수 의존성을 부과하기 위해 개별 음원의 스펙트로그램은 ILRMA에서 NMF를 사용해 주파수에 대한 기저 함수와 시간에 대한 활성 함수의 단순 행렬 분해로 모델링 될 수 있다.[20,21] 주파수에 대한 번째 기저함수 는 기본적인 구성 음성 성분을 의미하는 주파수 축으로의 벡터를 나타내며, 시간에 대한 활성함수 는 이러한 기저함수의 음성 성분이 언제 발생할지를 나타내는 벡터이다. 총 개의 기저함수가 음성을 구성한다고 가정할 때, 의 수식을 사용하여 의 업데이트를 와 의 업데이트로 대체할 수 있다. 이때 Eq. (3)에 대입하여 얻어지는 로그-우도 함수는 아래와 같다.
해당 함수를 각각 와 의 편미분을 통해 아래와 같은 방정식을 얻는다.
이에 따라서 목표 음성에 대한 기저 함수 와 활성 함수 의 곱셈 기반의 업데이트 식을 아래와 같이 얻을 수 있다.
이때, 로 Eq. (18)와 Eq. (19)의 를 구할 수 있다.
한편, 이전의 개별 잡음에 대한 분산이 모두 똑같이 로 주어진다는 가정은 이상적인 등방성 확산 잡음을 기반으로 하였다. 이러한 과도하게 엄밀한 가정을 완화하기 위해, 본 논문에서는 출력 성분들의 공통의 기저 함수 와 활성 함수 가 이득 함수 에 의해서 아래와 같이 가중치가 설정되도록 분해하여 잡음 출력 간의 의존성을 유지한다.
Eq. (15)과 유사하게 잡음 소스 모델에 대한 로그-우도 함수를 얻어 동일한 방식으로 잡음의 분산을 나타내는 NTF[27] 매개변수에 대해서
로 표현되는 업데이트 식을 가질 수 있다.
III. 실험 결과
제안 알고리즘의 음성 인식 성능은 CHiME-4 데이터셋을 기반으로 평가를 하였다.[33,34] 이는 6개의 마이크가 부착된 태블릿 PC를 통해서 실제 잡음 환경에서 녹음된 음성 데이터로, 총 4가지의 환경(café, street, bus, pedestrian)에서 네 명의 화자가 330개의 발화를 녹음하여 총 2640개의 실제 발화 데이터로 구성되어 있다. 추가적으로 무향실에서 녹음한 410개의 발화를 네 명의 화자가 발화하여 동일 환경에서 별도로 취득한 잡음 데이터를 더하여 시뮬레이션 데이터 6560개가 추가적으로 포함되어 있다. 구성한 음성 인식 시스템은 Reference [32]과 같다. Reference [32]에서와 같이, 마이크 입력 신호의 샘플링 주파수를 16 kHz로 설정하고, 1024 샘플 길이의 Hanning 윈도우를 256 샘플 간격으로 이동하여 국소 푸리에 변환(Short-Time Fourier Transform, STFT)을 수행했다.
Table 1에서, AuxIVA에 기반한 제안 알고리즘(Prop. AuxIVA)과 ILRMA에 기반한 제안 알고리즘(Prop. ILRMA)은 모델에 기반한 IVA(Model IVA)와 비교하였다. 평가 지표로는 단어 오류율(Word Error Rate, WER)을 사용했고, 목표 음원에 대한 마스크로는 Reference [28]을 따라 학습된 인공 신경망 기반 마스크 또는 CDR로 추정된 확산성 기반의 마스크를 사용하였다[29,30]. Reference [24]의 직교 제한(Orthogonal Constraint, OC)은 인식 성능을 향상시키기 위해 모델 기반 IVA에 적용했다(Model IVA + OC). 추가적으로 마스크를 쓰지 않고 기존에 효과적인 성능을 보여주었던 빔포밍 알고리즘인 복소 가우시안 혼합 모델(Complex Gaussian mixture model, CGMM)[35] 및 최소 파워 왜곡 방지 응답(Minimum-Power Distortionless Response, MPDR) 방법[36] 또한 비교하였다.
Table 1.
WERs (%) on the CHiME-4 dataset for the no processing for input data acquired at the fifth microphone and enhancement with batch processing by CGMM + MPDR, Model IVA, Model IVA + OC, Prop. AuxIVA, and Prop. ILRMA.
| Mask | Method | Dev. | Test | ||
| Simu. | Real | Simu. | Real | ||
| - | No processing | 5.57 | 6.47 | 6.85 | 11.98 |
| - | CGMM[35] + MPDR[36] | 3.86 | 3.24 | 6.09 | 5.66 |
| CDR[29] | Model IVA[23] | 4.49 | 5.91 | 6.50 | 9.78 |
| Model IVA[23] + OC[24] | 3.53 | 4.54 | 4.38 | 7.46 | |
| Prop. AuxIVA | 2.55 | 3.23 | 3.73 | 4.83 | |
| Prop. ILRMA | 2.61 | 3.15 | 3.71 | 4.65 | |
| NN[28] | Model IVA[23] | 3.59 | 5.03 | 4.72 | 9.15 |
| Model IVA[23] + OC[24] | 2.86 | 4.22 | 3.54 | 6.96 | |
| Prop. AuxIVA | 2.51 | 2.99 | 3.27 | 4.65 | |
| Prop. ILRMA | 2.62 | 3.08 | 3.24 | 4.51 | |
제안 알고리즘의 일괄 처리에서, 𝜀, 𝜅, 𝛽, 𝜏0와 𝛿는 각각 10-6, 20, 0.2, 1, 와 10-10으로 설정했다. 100회 전체 반복을 수행하되, 가 30회 반복 후 1로 변경 되었다. 마스크가 수렴에 도움이 되기 때문에, ILRMA에서 목표 음원과 잡음을 위한 기저의 개수를 50개로 설정했다. 이는 기존 ILRMA보다 훨씬 많이 설정한 값이다. CGMM 방법의 경우 총 10회의 수렴 반복을 수행하였다.
사용된 마스크에 상관없이, 그리고 Model IVA이 직교 제한이 있든 없든 간에 제안 알고리즘들이 더 좋은 음성 인식 성능을 보였다. 이는 Model IVA[23]에서 분산을 수정하여 모든 개별 채널에 고정된 분산을 쓰는 방식과 달리, 초반 수렴에서 마스크 정보를 활용하여 목표 음원을 목표 채널로 유도하고 동시에 잡음 출력 채널 간에는 의존도를 줄 수 있기 때문이다. 한편, 제안 알고리즘 중 Prop. ILRMA는 Prop. AuxIVA보다 약간 더 개선된 WERs를 보이는데, 이는 충분한 반복을 거치며 추정 변수가 많은 NMF 변수가 충분히 수렴하기 때문이다. 한편 신경망 기반의 마스크를 활용하였을 때에는 Prop. AuxIVA 방법이 비교적 좀 더 향상된 결과를 보였는데, 이는 더 정확한 마스크가 주어지면서 NMF를 통한 근사가 성능 향상에 크게 도움이 되지 않은 것으로 이해할 수 있다.
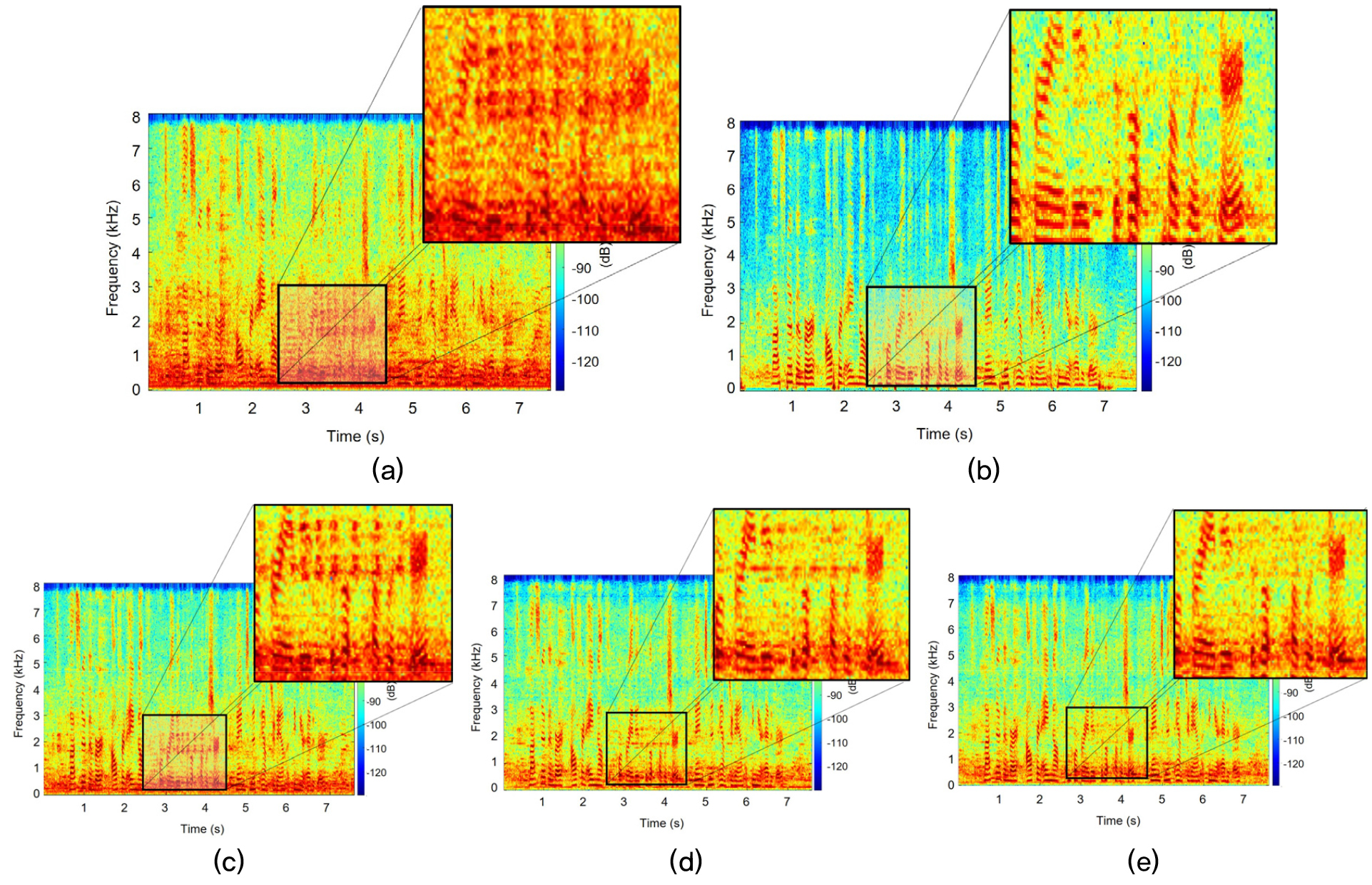
Fig. 2는 샘플 입력 스펙트로그램과 근거리 레퍼런스 신호, 그리고 입력 신호에 대해서 각각 CGMM + MPDR방법 및 CDR 마스크를 활용하여 제안 방법(Prop. AuxIVA, Prop. ILRMA)으로 향상시킨 출력 스펙트로그램을 표시한 것이다. Fig. 2(b)의 근거리 레퍼런스 신호와 비교하여 기존 Fig. 2(c)의 MPDR 빔포밍 방법과 비교하여 CDR 마스크를 활용한 제안 방법이 좀 더 효과적으로 잡음 성분을 억제하는 것을 확인할 수 있다.