

I. Introduction
II. Minimum Variance Distortionless Response (MVDR)
III. Proposed Method
3.1 Covariance matrices estimation
3.2 Variable forgetting factor
IV. Experiments
4.1 Experimental setup
4.2 Experimental result
V. Conclusion
I. Introduction
Microphone array (MA) based speech enhancement schemes are popularly used for various applications such as speech recognition and teleconferences[1]. For example, the linearly constrained minimum variance (LCMV) beam-forming has a criterion of minimizing total signal power while preserving the target signal and eliminating inter-ference signal[2]. Due to an additional constraint to the direction of interference signal, however, its noise reduction performance is poor. On the contrary, the MVDR beam-forming only has a criterion of preserving a filter gain to the direction of target signal while minimizing the total signal power. Although its interference reduction perfor-mance is poor, it is simple to control. This paper focuses on the method to enhance the performance of the MVDR beamforming.
To successfully accomplish the MA processing with MVDR beamforming, the DoA of target speech should be provided accurately and a covariance matrix must include only interference and noise components. Provided that precise DoA is given, it is helpful for estimating the covariance matrix. Furthermore, an additional correction process for the beamforming is not needed[3]. However, it is very difficult to accurately estimate DoA information in reverberant environment using audio signal only because of its difficulty in phase estimation. In a situation where it is very hard to separate interference components from the received signal, the received speech is directly used for calculating the covariance matrix, which results in perfor-mance degradation. In order to solve the problem, an audio- visual (A/V) sensor based approach has been recently proposed which has excellent capability of DoA estimation capability[4]. Since the system still needs to estimate the covariance matrix with the acquired signals, thus the improvement of beamforming performance was minimal. If the interference component is speech and the accurate DoA information is given, the covariance matrix for MVDR beamforming can be constructed efficiently.
This paper proposes a novel covariance matrix estimation method for MVDR beamforming. The main application area of the proposed scheme is a multi-user A/V communi-cation system. By accurately estimating DoA using an A/V sensor based approach, a reliable steering vector for the covariance matrix is created and the steering vector is a phase component of covariance matrix. Then, the magnitude component of covariance matrix in the current frame is recursively updated by taking a first-order recursive avera-ging with the previous obtaining covariance matrix and the acquired speech signals. The forgetting factor needed for the averaging process is adjusted depending on the estimated SIR. Unlike the LCMV beamforming approach, the proposed MVDR method handles the interference constraint within the minimization criterion of estimating the precise covariance matrix.
Experimental results show that the proposed beamforming successfully reduces both interference and noise components of which performance is much better than the conventional beamforming. Also, the proposed method shows better performance than conventional methods in reverberant environment.
This paper is organized as follows. Section 2 formulates the problem and explains the MVDR beamforming method. The proposed method for efficient beamforming is described in Section 3. Section 4 shows the experimental results as figures and tables and conclusion is described in Section 5.
II. Minimum Variance Distortionless Response (MVDR)
In a noisy acoustic environment where people have A/V communication, it is necessary to acquire target speech signal only using a beamforming. In this paper, it assumes that there are two speakers in a room. Given a target speech 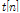 , an undesired interference speech
, an undesired interference speech 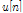 , and a diffused noise
, and a diffused noise 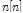 are captured by
are captured by 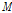 microphone array sensors, the received signals can be represented by
microphone array sensors, the received signals can be represented by
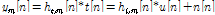
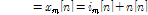 ,
,where 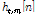 and
and 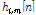 are transfer function of target and interference speech to each microphone, respectively.
are transfer function of target and interference speech to each microphone, respectively. 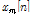 and
and 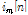 are captured target and interference speech and,
are captured target and interference speech and, 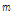 is microphone index. It assumes that the speeches and diffused noise are uncorrelated. In the frequency domain, the received signals can be rewritten as
is microphone index. It assumes that the speeches and diffused noise are uncorrelated. In the frequency domain, the received signals can be rewritten as
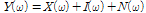 ,
,and 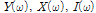 and
and 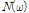 are the
are the 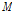 -length vector which consists of acquired component in each microphone, respectively.
-length vector which consists of acquired component in each microphone, respectively.
For simplicity, frequency index 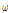 is omitted from now on. Using the far-field assumption, the signal acquired by each sensor is represented by the phase shifted version of the first sensor signal as follows:
is omitted from now on. Using the far-field assumption, the signal acquired by each sensor is represented by the phase shifted version of the first sensor signal as follows:
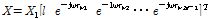 ,
,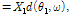
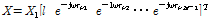 ,
,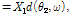
where 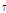 is a time delay component and
is a time delay component and 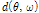 is a steering vector to the angle of direction of arrival (DoA).
is a steering vector to the angle of direction of arrival (DoA). 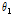 is the DoA of desired speech and
is the DoA of desired speech and 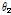 is that of interference speech.
is that of interference speech.
Given an optimum weight vector, the output of the optimum beamforming or enhanced target speech is obtained by following equation
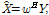
where 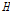 is Hermitian (complex conjugate) transpose and
is Hermitian (complex conjugate) transpose and 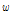 is optimum weight vector.
is optimum weight vector.
The optimum weight vector 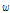 of MVDR beamforming is determined by solving the criterion of minimizing the output power while preserving the target speech signal such as[2]:
of MVDR beamforming is determined by solving the criterion of minimizing the output power while preserving the target speech signal such as[2]:
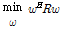 subject to
subject to 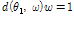
where 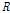 is the covariance matrix of acquired signal. The optimum solution is given by [2]
is the covariance matrix of acquired signal. The optimum solution is given by [2]
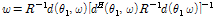 .
.Assuming that the DoA of target speech, 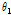 , is given, how to obtain the covariance matrix
, is given, how to obtain the covariance matrix 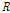 is very important. Note that the covariance matrix
is very important. Note that the covariance matrix 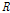 must include interference and noise components only. Since it is difficult to extract interference component only, the conventional MVDR beamforming directly utilizes the acquired signal. After substituting
must include interference and noise components only. Since it is difficult to extract interference component only, the conventional MVDR beamforming directly utilizes the acquired signal. After substituting 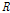 with
with 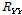 , the covariance matrix is computed by taking a recursive averaging with a fixed value of forgetting factor [5] :
, the covariance matrix is computed by taking a recursive averaging with a fixed value of forgetting factor [5] :
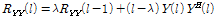 ,
,where 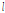 and
and 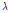 indicates the frame index and a forgetting factor, respectively. The phase of the covariance matrix
indicates the frame index and a forgetting factor, respectively. The phase of the covariance matrix 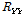 consists of the phase terms in target and interference speech signal. Note that the mixed phase is not corresponded to phase of interference speech. Therefore, beamforming performance is significantly deteriorated.
consists of the phase terms in target and interference speech signal. Note that the mixed phase is not corresponded to phase of interference speech. Therefore, beamforming performance is significantly deteriorated.
III. Proposed Method
In this section, an estimation accuracy of covariance matrix is improved by including only the components of interference signal and diffused noise.
It can be realized by accurately obtaining DoA information using an audio-visual sensor based approach [6]. In addition, the performance enhances further by introducing a variable forgetting factor in Eq. (8).
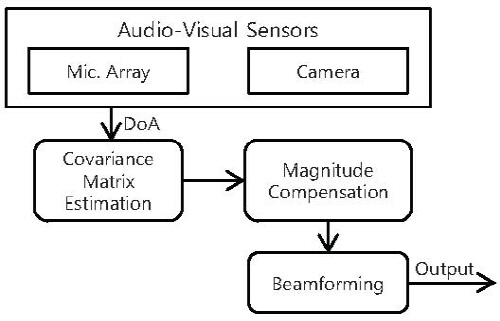
A system block diagram of the proposed approach is shown in Fig. 1. In this system, precise DoA information is obtained by a depth camera and MA. Note that the DoA information of target/interference speech is estimated by employing a head detecting/tracking algorithm [6]. Then, the covariance matrix can be estimated by using the obtained DoA information. For the precise covariance matrix, the magnitude compensation method is utilized. In the covariance matrix, phase information is derived from the visual sensors and magnitude information is controlled by the variable forgetting factor.
3.1 Covariance matrices estimation
As is assumed above, speech signal and diffused noise are uncorrelated so that the covariance matrix of the received signal can be separated into three types of covariance matrices :
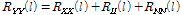 ,
,where 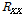 ,
, 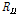 , and
, and 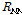 indicate target, interference speech, and noise covariance matrices. Since the desired covariance matrix should include only interference and noise components,
indicate target, interference speech, and noise covariance matrices. Since the desired covariance matrix should include only interference and noise components, 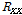 term must be removed. In other words, the desired covariance matrix
term must be removed. In other words, the desired covariance matrix 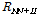 includes only the interference and noise terms [5]
includes only the interference and noise terms [5]
 ,
,
where K is the number of snapshot and 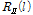 is derived by taking a product between scalar value
is derived by taking a product between scalar value 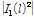 and steering vector
and steering vector 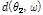 , and a recursive averaging with a fixed forgetting factor
, and a recursive averaging with a fixed forgetting factor 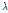 .
. 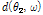 can be constructed by the DoA obtained by audio-visual sensors and the unknown magnitude of interference signal
can be constructed by the DoA obtained by audio-visual sensors and the unknown magnitude of interference signal 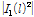 is estimated by modifying the known magnitude of output signal
is estimated by modifying the known magnitude of output signal 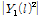 .
.
In the proposed method, the estimated value of interference covariance matrix 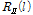 is expressed as follows:
is expressed as follows:
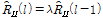
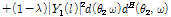 .
.The noise covariance matrix 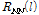 is also expressed as follows:
is also expressed as follows:
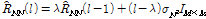 ,
,where 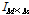 is an identity matrix and the power of noise term,
is an identity matrix and the power of noise term, 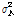 , is updated in non-speech frames using a simple voice activity detection (VAD) algorithm.
, is updated in non-speech frames using a simple voice activity detection (VAD) algorithm.
3.2 Variable forgetting factor
To estimate the interference covariance matrix 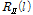 given in Eq. (11), the forgetting factor,
given in Eq. (11), the forgetting factor, 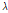 , needs to be determined. The forgetting factor compensates the inaccurate magnitude value
, needs to be determined. The forgetting factor compensates the inaccurate magnitude value 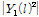 of estimated covariance matrix. The update rate needs to be controlled dynamically to improve the accuracy. For example, if the magnitude of interference speech is much stronger than that of target speech, it is appropriate to use a small forgetting factor in order to rapidly track the interference speech. In this paper, a variable forgetting factor is introduced which varies depending on signal-to-interference ratio (SIR):
of estimated covariance matrix. The update rate needs to be controlled dynamically to improve the accuracy. For example, if the magnitude of interference speech is much stronger than that of target speech, it is appropriate to use a small forgetting factor in order to rapidly track the interference speech. In this paper, a variable forgetting factor is introduced which varies depending on signal-to-interference ratio (SIR):
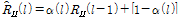
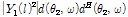 ,
,where
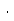
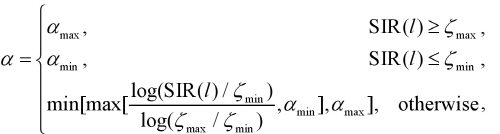
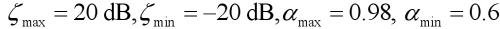
In Eq.(14), the variable forgetting factor is varied from 0.98 to 0.6 depending on the SIR value. if the variable forgetting factor varies rapidly, the performance may be degraded. Therefore, upper and lower bounds of SIR value are introduced and the maximum and minimum values of the forgetting factor (0.98, 0.6) are empirically determined. Therefore, the variable forgetting factor is decreased in order to update the magnitude, if the power of the interference speech is high. Since the DoA information of target and interference speech is given already, SIR can be approxi-mated by power ratio between 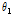 and
and 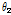 of steered response power (SRP). Note that the impact of
of steered response power (SRP). Note that the impact of 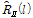 and
and 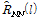 to the desired covariance matrix
to the desired covariance matrix 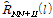 is different. Therefore, an additional weighting term to each component may be desirable somehow. In tne reference 7, a generali-zed form of cost function was introduced to the multichannel Wiener Filter where
is different. Therefore, an additional weighting term to each component may be desirable somehow. In tne reference 7, a generali-zed form of cost function was introduced to the multichannel Wiener Filter where 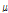 is a tradeoff parameter between the noise reduction and the speech distortion. In this paper, a desired covariance matrix is finally expressed as
is a tradeoff parameter between the noise reduction and the speech distortion. In this paper, a desired covariance matrix is finally expressed as
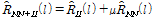 ,
,where 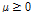 is the tradeoff parameter between interference reduction and noise reduction. If
is the tradeoff parameter between interference reduction and noise reduction. If  , noise is more reduced by decreasing interference reduction and vice versa.
, noise is more reduced by decreasing interference reduction and vice versa. 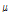 is empirically determined to maximize SINR improvement in this paper. In this paper,
is empirically determined to maximize SINR improvement in this paper. In this paper, 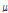 is empirically selected as 6.
is empirically selected as 6.
IV. Experiments
4.1 Experimental setup
Experiments are conducted to measure the effect of interference reduction and diffused noise reduction. 16 kHz sampled male and female speech are used as the target and interference speech and 512-point of FFT size is chosen. Diffused noise is created using white noise. Signal is mixed to have 5 dB signal-to-interference ratio (SIR) and white noise has 20 dB signal-to-noise ratio (SNR). A linear array has four microphones which are uniformly spaced with an interval of 4 - cm and it is located at the center of the room. The target/interference speech is fixed at the 0°/60° and located 1.5 m/2.5 m from the microphones in the room of which size is 6 m width, 6 m length, and 3 m height. The linear microphone array and speech have 1.7 m height. Fig. 2 depicts the simulation environment.
The first experiment is conducted in an artificial anechoic room. That is, there are only target, interference speech and diffused noise without reverberation. The second experiment is conducted in reverberant environment. By utilizing the image method[8], room impulse response (RIR) is artificially created with 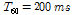 and the RIR has 1000 taps.
and the RIR has 1000 taps.
4.2 Experimental result
Four performance evaluation methods such as noise reduction (NR), interference reduction (IR), speech distortion (SD), and signal-to-interference-plus-noise ratio improvement (SINRI) are measured to evaluate the performance [9].
Table 1 shows experimental result of conventional MVDR, LCMV, and other methods which are the method of covariance matrix estimation (Cov. Estimation), covariance matrix estimation with a variable forgetting factor (Cov. Estimation + Varable for. Fac.), and the proposed method which is covariance matrix estimation with a variable forgetting factor and weighting factor in anechoic environment. MVDR and LCMV is referred from the reference 2. Also, third method creates the covariance matrix using the DoA information and fourth method creates it with variable forgetting factor. Finally, proposed method is additionally introduced the controlling weight factor. It can be seen that performance improves if the accurately estimated covariance matrix is used. Adopting a variable forgetting factor can attenuate the noise component and distortion without strong attenuation of the speech component though there is a little IR degradation. A controlling weight factor given in Eq. (15) also enhances beamforming performance.
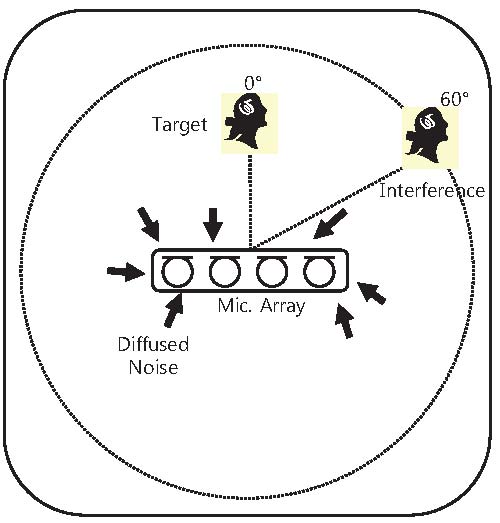
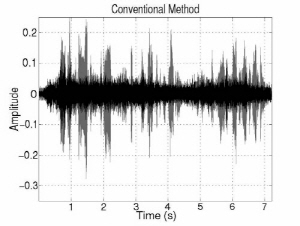
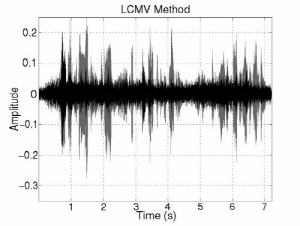
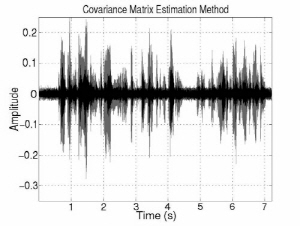
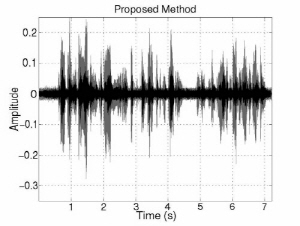
Fig. 3 shows the interference and noise reduction of conventional and proposed beamformings in the anechoic environment. The gray signals indicate the original inter-ference and noise components and the black signals indicate the reduced interference and noise components. The interference and noise components are substantially decreased by introducing the DoA information. In addition, noise component is more decreased in proposed method. Overall, noise and interference are decreased around 3 dB and 31 dB individually and speech is much less distorted than conventional methods in the first experiment. In terms of SINR improvement, there is around 18 dB gain. That is, the proposed MVDR method is much better performance than the LCMV one in terms of NR, SD, and SINR. The LCMV method has better performance than the proposed one in terms of IR because of the constraint on rejecting the interference speech. However, since the LCMV has a weak point of boosting the noise in low frequency region, the SINR improvement is small. On the other hand, the proposed MVDR beamforming simultaneously reduces interference and noise signal with less distortion. In addition, the ratio of interference/noise reduction is controllable by adjusting the weight factor.
|
|
(a) MVDR method | (b) LCMV method |
|
|
(c) Covariance matrix estimation | (d) Proposed method |
Fig. 3. Interference and noise reduction of conventional and proposed beamforming in anechoic environment. | |
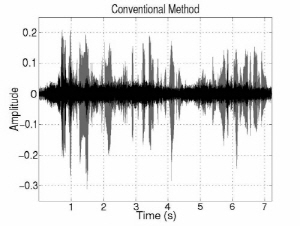
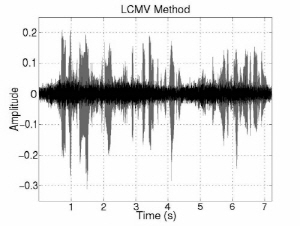
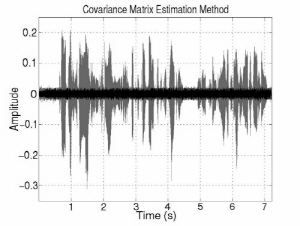
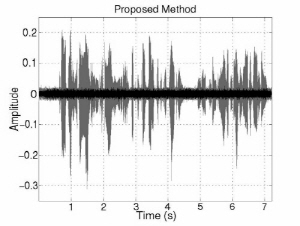
Fig. 4 indicates a beampattern (2.1 kHz) of conventional MVDR, LCMV, and the proposed method in anechoic and reverberant environment. In order to attenuate interference speech while preserving the target speech, the beampattern should have a characteristic of unity/low magnitude value at 0°/60°. LCMV can construct a null at 60° by using an additional criterion and the null does not exist in the beampattern of conventional MVDR so it can not reduce the interference speech as much as LCMV. However, since the proposed method estimates the covariance matrix accurately, its attenuation performance of the undesired interference speech is similar to LCMV. In addition, Fig. 4 shows that the proposed method attenuates even in reverberant environment. That is to say, look and null directions of beampatterns are not changed.
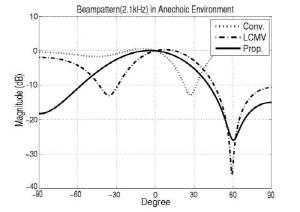
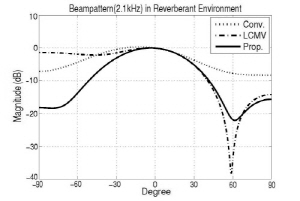
Table 2 shows experimental result of same beamforming methods in reverberant environment. Unlike anechoic environment, beamforming performance is considerably degraded because reverberation distorts phase information of target and interference speech. In comparison with Table 1, performance of all beamforming methods is degraded, especially interference reduction. Conventional MVDR and LCMV method also have a phenomenon of boosting the noise, however, the proposed method still reduces interference and noise signal. Overall, it can be analyzed that noise and interference are decreased around 3 dB and 6 dB individually. In the proposed method, the performance of NR and IR is increased and it can be considered as attenuation of the late reverberation of speech component. Therefore, the proposed method can attenuate both noise and interference signal even in reverberant environment.
Fig. 5 shows the interference and noise reduction of conventional and proposed beamforming in the reverberant environment. Similar to Fig. 3, the gray/black signals indicate the original/reduced interference and noise component, individually. Due to the reverberant, the interference and noise components are quite in case of the conventional MVDR and LCMV. However, the proposed method attenuates the interference and noise signal more than the conventional methods.
V. Conclusion
This paper has suggested an improved MVDR beam-forming with A/V sensors in anechoic/reverberant environ-ment. The proposed beamforming estimates a covariance matrix using DoA information and compensates inaccurate magnitude by a variable forgetting factor. The proposed method can be interpreted as a processing that handles the constraint of an interference component within a minimiza-tion criterion of estimating the precise covariance matrix. Using the proposed method, the beamforming system reduces both noise and interference signal not only in anechoic environment but also in reverberant environment. Though the performance is slightly degraded in reverberant environment, it still shows that the proposed method can be applied to real room environment.
