

I. 서 론
II. 연구방법
2.1 바이노럴 마이크로폰 종류
2.2 피험자
2.3 실험 음원
2.4 실험절차
2.5 심리음향지표 분석
III. 실험결과
3.1 바이노럴 마이크로폰 간 성능 비교 분석
3.2 바이노럴 마이크로폰 종류 및 착용자에 의한 결과 비교
IV. 토 의
4.1 바이노럴 마이크로폰 종류에 따른 차이
4.2 바이노럴 마이크로폰 착용자에 의한 차이
4.3 심리음향지표별 최소 식별차이와의 비교
4.4 한계점 및 향후 연구
V. 결 론
I. 서 론
ISO 12913-1에 따르면 사운드스케이프는 “상황 내에서 사람이나 사람들이 지각하거나 경험 및/또는 이해하는 음환경”으로 정의된다.[1] 사운드스케이프 접근법은 단순히 소음 저감을 목표로 하는 것이 아니라 인지 음환경을 총체적으로 이해하고 평가하는 접근 방식이다. 이를 위해 ISO 12913에서는 사운드스케이프 평가 시 인간의 청각, 음환경 및 상황과 관련된 종합적인 데이터를 수집하도록 한다. 특히 삼각검증법을 기반으로 주관 설문평가, 물리적 음향측정, 정성적 인터뷰 등을 통해 종합적으로 사운드스케이프 데이터를 수집하도록 명시하고 있다.[1,2,3]
ISO TS 12913-2에서는 모든 공간 음향 정보를 유지하면서 마치 청취자가 원래 음장에 있는 것처럼 소리를 녹음할 수 있는 바이노럴 측정을 수행 하도록 명시하고 있다. 바이노럴 측정은 두 개의 오디오 채널로 인간의 청음 과정을 녹음하는 방식이다. 바이노럴 측정 핵심 원리는 소리가 한쪽 귀에 더 빨리 또는 더 크게 도달하는 시간차와 강도 차이를 모방해 공간적 음향 인식을 만들어내는 것이다. 이 방법은 머리와 어깨에서 반사되거나 회절 되는 소리까지 녹음하여 실제 청각과 매우 유사한 스테레오 음향을 제공한다. 따라서 바이노럴 녹음은 실제 환경에서의 사운드스케이프 경험을 측정 및 재생할 수 있다. 또한 다른 녹음 방식보다 일관된 결과를 제공하기 때문에 사운드스케이프 표준에서 필수 요소로 명시하고 있다.[4]
현재 바이노럴 녹음에서 일관되고 비교 가능한 결과를 얻기 위해 주로 인공 머리 시뮬레이터가 사용된다. 바이노럴 마이크로폰은 인공머리 시뮬레이터에 비해 휴대성이 뛰어나지만 헤드 셰도잉 효과가 부족하다는 연구 결과도 있다.[5] 대부분의 연구는 바이노럴 마이크로폰 간의 방향성이나 소리의 방향 분별 정도를 비교하는 데 초점을 맞추고 있지만, 물리적 소음지표 및 심리음향 측정 결과에 대한 비교 연구는 부족한 실정이다.[6,7] 특히 바이노럴 마이크로폰의 경우 측정자에 따라 서로 다른 머리전달함수(Head Related Transfer Function, HRTF)가 적용될 수 있기 때문에 측정자에 따라 측정오차가 발생될 수 있다.
이에 따라 본 연구는 인공머리 시뮬레이터와 다른 형태의 바이노럴 마이크로폰으로 측정한 소리를 비교 분석하여, 사운드스케이프 평가에서 (1) 서로 다른 바이노럴 마이크로폰 간에 발생할 수 있는 측정 오차와 (2) 측정자 간에 발생할 수 있는 오차에 대해서 고찰하고자 한다.
II. 연구방법
2.1 바이노럴 마이크로폰 종류
본 연구에서는 사운드스케이프 연구에서 많이 사용되는 세 가지 바이노럴 마이크로폰 종류를 이용하여 측정한 음원 분석 결과를 비교 하였다.
(1) Artificial head simulator(HMS II.4, HEAD acoustics GmbH): 사람의 머리와 귀를 모사한 더미 헤드의 바이노럴 마이크로폰
(2) Headphone type(BHS II, HEADacoustics GmbH): 해드폰 형식으로 사람이 착용하고 사용하는 마이크로폰
(3) In-ear type(DPA 4560 CORE, DPA): 사람의 귀 안에 직접 착용하여 사용하는 바이노럴 마이크로폰
본 연구에서 비교한 세 가지 바이노럴 마이크로폰 사양은 Table 1과 같다.
Table 1.
Specifications of binaural microphones.



2.2 피험자
실험에 참여한 피험자는 총 20명으로 평균 연령은 24.3세(SD = 1.69)였으며, 남성 11명, 여성 9명이 참여하였다. 각 피험자의 신체 조건이 마이크로폰 입력 신호에 미치는 영향을 평가하기 위해 신체 데이터(키, 어깨너비, 머리둘레)를 측정하였다. 측정 결과, 피험자들의 평균 키는 169.15 cm (SD = 8.12), 어깨너비는 평균 46.45 cm (SD = 5.63), 머리 둘레는 평균 56.25 cm (SD = 2)로 나타났다.
2.3 실험 음원
본 실험에서 바이노럴 마이크로폰 간의 음원 분석 결과를 분석하기 위해 사운드스케이프 평가에 자주 활용되는 물소리(W), 사람소리(H), 도로교통 소음(T)을 녹음하였다. 음원 녹음은 NTi Audio MA220 마이크로폰과 TASCAM DR 40-X 레코더를 사용하여 충남대학교 인근에서 진행되었다. 또한, 주파수 대역에 따른 차이를 비교하기 위해 핑크노이즈(P)를 추가하여 총 네 가지 음원으로 구성하였다. Fig. 1 은 실험에 사용한 네 가지 음원들의 스펙토그램분석 결과를 보여준다. 물소리와 핑크노이즈는 일관적이고, 도로교통 소음과 사람소리는 변동성이 큰 것으로 나타났다. 모든 음원의 음압레벨은 HMS II.4 기준으로 음원별 녹음 시 측정한 LAeq로 조정하였다. 또한 샘플링 주파수는 44,100 Hz, 비트 심도는 24 bit로 모든 마이크로폰에서 동일하게 설정하여 측정을 진행하였다.
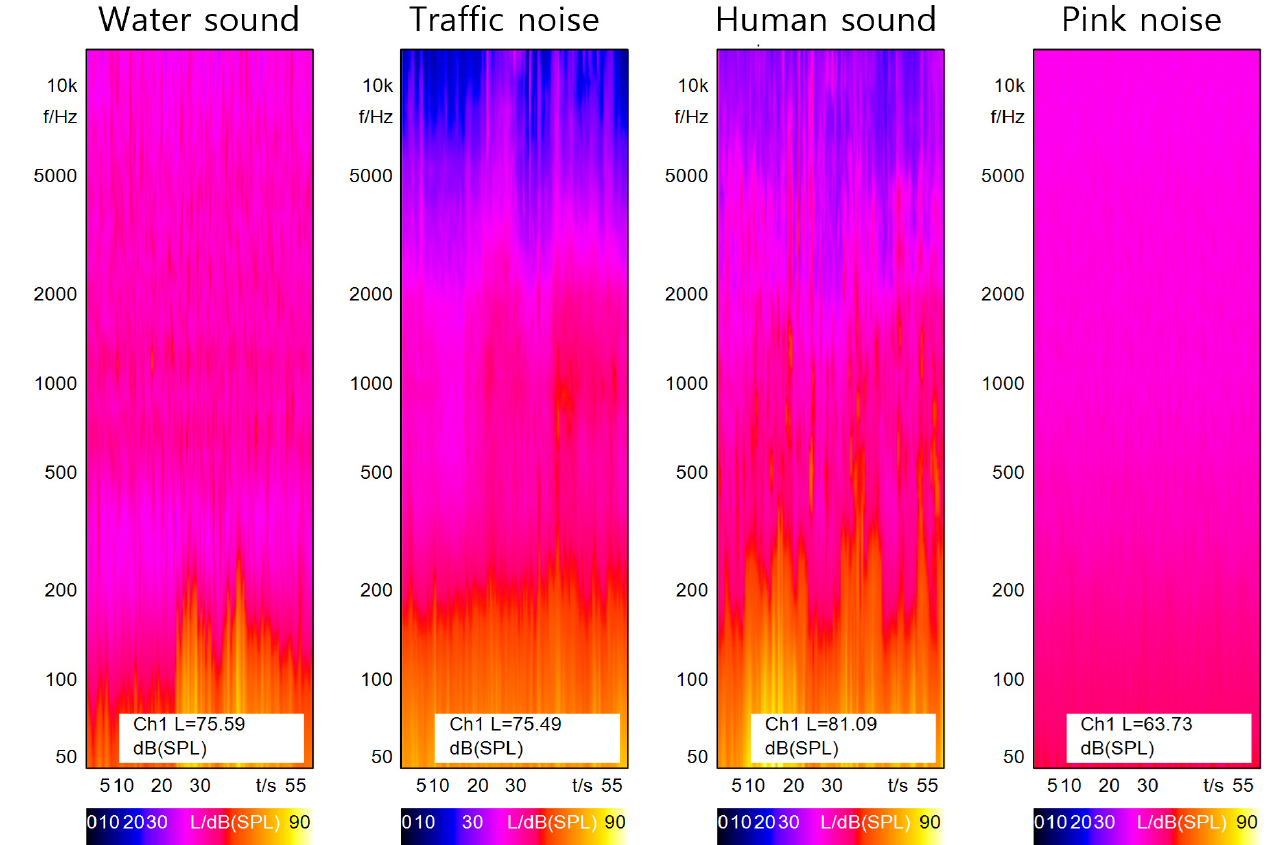
실험에 사용된 음원의 시간적 변동성과 주파수 대역별 구성을 분석하기 위해 LA10 - LA90 및 LCeq – LAeq를 계산했다. Table 2는 이 계산 값과 음향 파라미터에 대한 결과를 보여준다. 분석 결과, 도로교통 소음과 사람소리는 소리의 불규칙성과 변동성이 큰 반면, 물소리와 핑크노이즈는 지속적이고 일정한 소리패턴을 보였다. 또한, 주파수 대역별 분석에서는 핑크노이즈를 제외한 모든 소리에서 저주파 대역이 차지하는 비중이 높은 것으로 나타났다.
Table 2.
Temporal volatility, frequency band composition and psychoacoustic parameters of sound source.
2.4 실험절차
본 실험은 다양한 음원에 대해 각 바이노럴 마이크로폰으로 측정한 소리에 대해 비교하고, 마이크로폰 착용자에 따른 측정값을 비교하기 위하여 피험자들이 바이노럴 마이크로폰을 교차 착용하며 녹음을 진행하였다. 실험은 피험자가 서 있는 고정된 자세에서 진행되었다. 먼저 Headphone type을 착용한 상태에서 물소리, 도로교통 소음, 사람소리, 핑크노이즈 순서로 녹음을 진행한 후 In-ear type으로 교체해 동일한 절차를 반복하였다. 인공머리 시뮬레이터에 대한 평가는 따로 진행되었다.
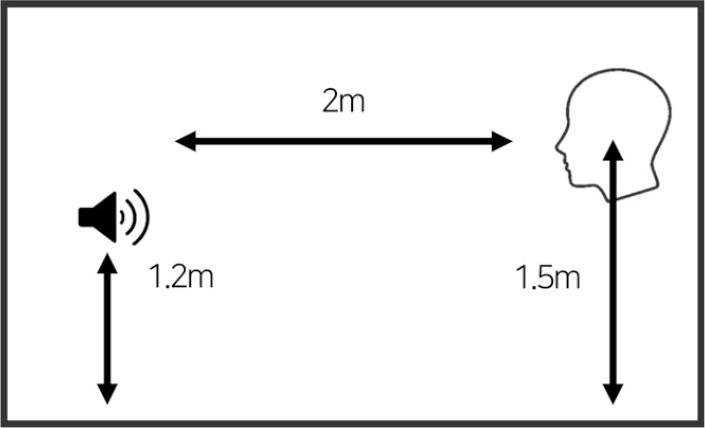
Fig. 2는 실험 시 피험자와 스피커의 위치를 나타낸 그림이다. 실험은 배경소음 16 dB, 잔향시간 0.2 s의 반무향실에서 진행되었으며, 음원은 Scarlett 2i2 오디오 인터페이스와 Genelec 8340 스피커를 이용하여 피험자와 2 m 거리에서 재생되었다. 인공머리 시뮬레이터의 귀 높이는 1.5 m 높이로 설정하였다. Headphone type과 In-ear type 바이노럴 마이크로폰의 높이는 피험자들에 따라 상이하였다.
2.5 심리음향지표 분석
심리음향학은 소리 자극과 인간 청각 감각 간의 관계를 연구하는 분야로, 그 중요성은 사운드스케이프 연구의 표준인 ISO 12913-1(2014)에서 강조된 바 있다.[1] 그러나 사운드스케이프 평가와 청감 간의 관계는 여전히 많은 연구가 필요하며, 사람마다 소리를 다르게 인식하기 때문에 그 결과를 일반화하기는 어렵다.[8] 이러한 이유로 심리음향 연구는 다양한 청취자의 주관적 반응을 이해하고, 이를 정량화하는 데 중요한 역할을 한다.[9]
주로 사용되는 심리음향지표로는 Loudness(N), Sharpness(S), Roughness(R), Fluctuation strength(F) 등이 있다. Loudness는 ‘소리의 음향적 특성 및 특정 청취 조건에 따라 달라지는 소리의 인지된 크기’를 의미하며, 음압레벨뿐만 아니라 소리의 주파수, 파형, 대역폭 및 지속 시간에도 영향을 받아 실제 음압레벨과는 다를 수 있다. 단위는 sone을 사용하며 1 sone 은 1 kHz 순음의 음압레벨 40 dB에 해당하는 음의 크기를 의미한다.[10] 본 연구에서는 Zwicker 모델을 기반으로 한 ISO 532-1을 사용해 계산했다.[11]
Sharpness는 소리의 고주파 함량을 측정하는 척도로, Loudness의 주파수 분포에 의해 결정된다. 단위는 acum을 사용하며, 1 acum은 1 kHz를 중심주파수로 하는 60 dB 순음의 청각 지각 량을 의미한다. 본 연구에서는 Loudness가 커질수록 높은 Sharpness를 생성하는 Aures 모델을 사용하여 Sharpness를 계산했다.[12]
Roughness는 20 Hz ~ 200 Hz 대역 소리의 변조를 평가하는 지표로 소리의 거칠기를 평가한다. 20 Hz ~ 200 Hz 사이의 변조가 포함된 소리는 거친 소리로 인식된다.[10] 본 연구에서는 ECMA-418-2 (2nd Edition)에 의해 계산되었다.
Fluctuation strength는 20 Hz 이하의 소리의 변조를 평가하는 지표로 20 Hz 이하에서 변조되는 소리는 시간이 지남에 따라 변동하는 것으로 인식된다.[10] 본 실험에서는 음향 분석 소프트웨어인 Artemis Suite (HEADacoustics GmbH)를 사용하여 음향 분석을 진행하였다.
III. 실험결과
3.1 바이노럴 마이크로폰 간 성능 비교 분석
Table 3은 두 바이노럴 마이크로폰, Headphone type과 In-ear type의 차이를 분석하기 위해 수행한 t-test 결과를 보여준다. 분석결과, 등분산성 가정을 만족했으나 정규성 가정이 충족되지 않아 비모수 통계인 Mann-Whitney U 검정 결과를 사용하였다. Mean difference는 In-ear type과 Headphone type의 바이노럴 마이크로폰으로 측정한 결과의 평균차이를 나타낸다. Fluctuation strength를 제외한 다른 모든 지표들에서 두 바이노럴 마이크로폰 간의 유의미한 평균차이가 발생했다.
Table 3.
Mann-Whitney U independent t-test between headphone type and In-ear type ***p < 0.001.
Tables 4, 5, 6, 7은 음원별로 인공 머리 시뮬레이터, Headphone type, In-ear type로 측정한 LAeq, Loudness(N), Sharpness(S), Roughness(R), Fluctuation strength(F)의 기술통계 결과를 나타낸다. Headphone type와 In-ear type으로 측정한 평균, 표준편차, 범위 크기 및 마이크로폰 간의 평균 차이를 기록하고, 인공 머리 시뮬레이터와의 비교를 진행하였다.
Table 4.
Noise and psychoacoustic parameters of Water sound among Artificial head (HMS), headphone type (BHS) and In-ear type (DPA). The numbers in parentheses represent standard deviations.
Table 5.
Noise and psychoacoustic parameters of traffic noise among artificial head, headphone type and In-ear type.
Table 6.
Noise and psychoacoustic parameters of human sound among artificial head, headphone type and In-ear type.
Table 7.
Noise and psychoacoustic parameters of pink noise among artificial head, headphone type and In-ear type.
전반적으로 Roughness와 Fluctuation strength에서는 큰 차이가 없었지만, 다른 지표들에서는 차이가 나타났다. 모든 음원에서 인공 머리 시뮬레이터가 가장 낮은 LAeq 값을 기록했다. Headphone type과는 1 dB 이하의 차이를 보인 반면, In-ear type은 평균 2.5 dB의 차이를 보였다.
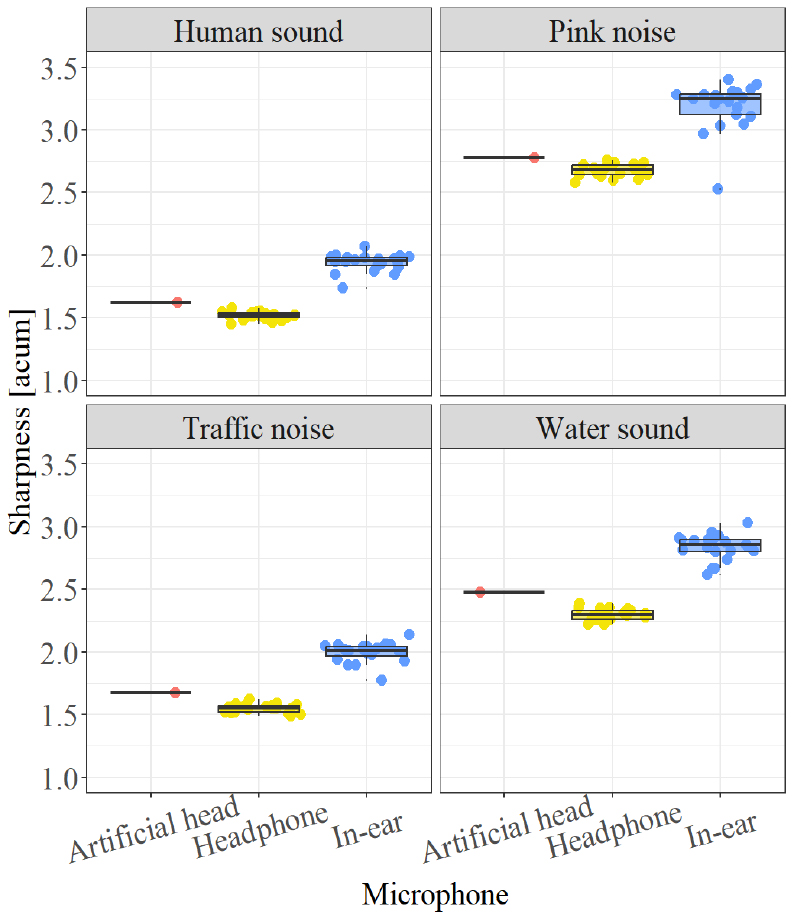
Loudness에서도 유사하게 Headphone type과는 1 sone 이하의 차이를 보였으나, In-ear type과는 평균 3.8 sone의 차이가 나타났다. Sharpness의 경우, 모든 음원에서 Headphone type이 가장 낮은 값을 보였다. 인공 머리 시뮬레이터와 Headphone type 간의 차이는 평균 0.13 acum이었고, In-ear type과의 차이는 평균 0.36 acum이었다.
또한 음원별로 LAeq, Loudness, Sharpness의 평균 차이를 비교하였다. Headphone type과 In-ear type 간 평균 차이는 사람 소리, 도로교통 소음, 물소리, 핑크 노이즈 순으로 작게 나타났다.
3.2 바이노럴 마이크로폰 종류 및 착용자에 의한 결과 비교
Figs. 3과 4는 음원별로 마이크로폰에 따른 LAeq와 Loudness를 비교한 결과를 나타낸다. 박스플롯을 이용하여 최댓값, 최솟값, 중앙값, 사분편차 등으로 표현하였다. 마이크로폰 간 비교를 위해 중앙값을 비교해 보면 Headphone type의 경우, LAeq과 Loudness에서 인공머리 시뮬레이터와 차이가 0.3 dB ~ 0.8 dB, 0.2 sone ~ 0.4 sone으로 나타났다. In-ear type의 경우에는 1.7 dB ~ 4.1 dB, 3.7 sone ~ 4.9 sone 정도로 Headphone type에 비해 큰 차이를 보였다.
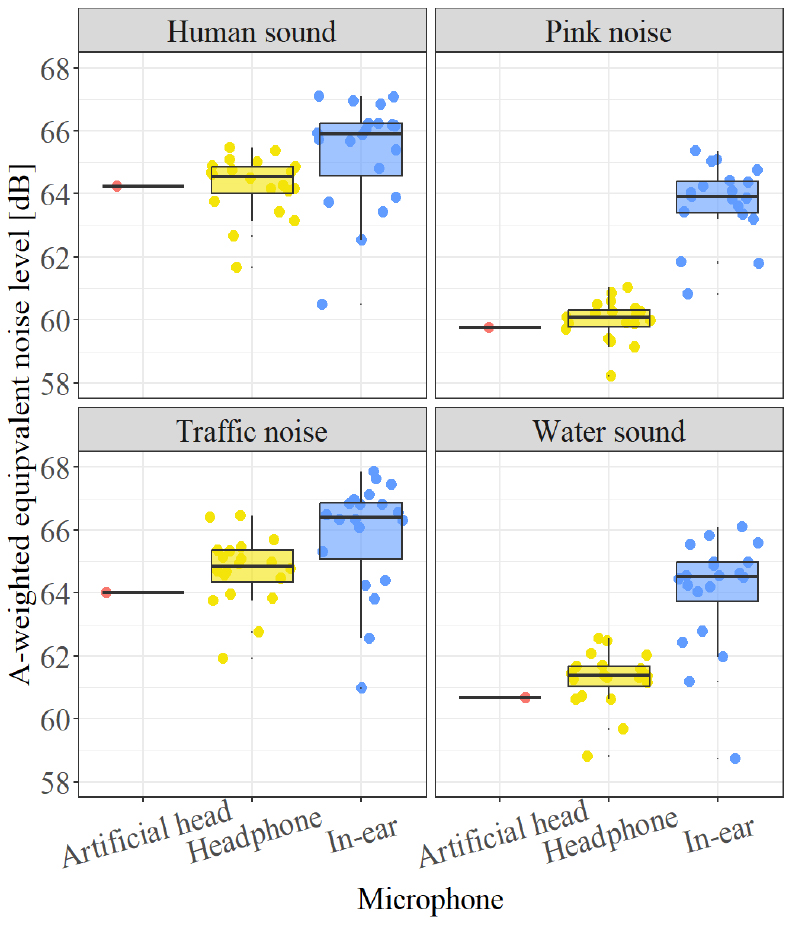
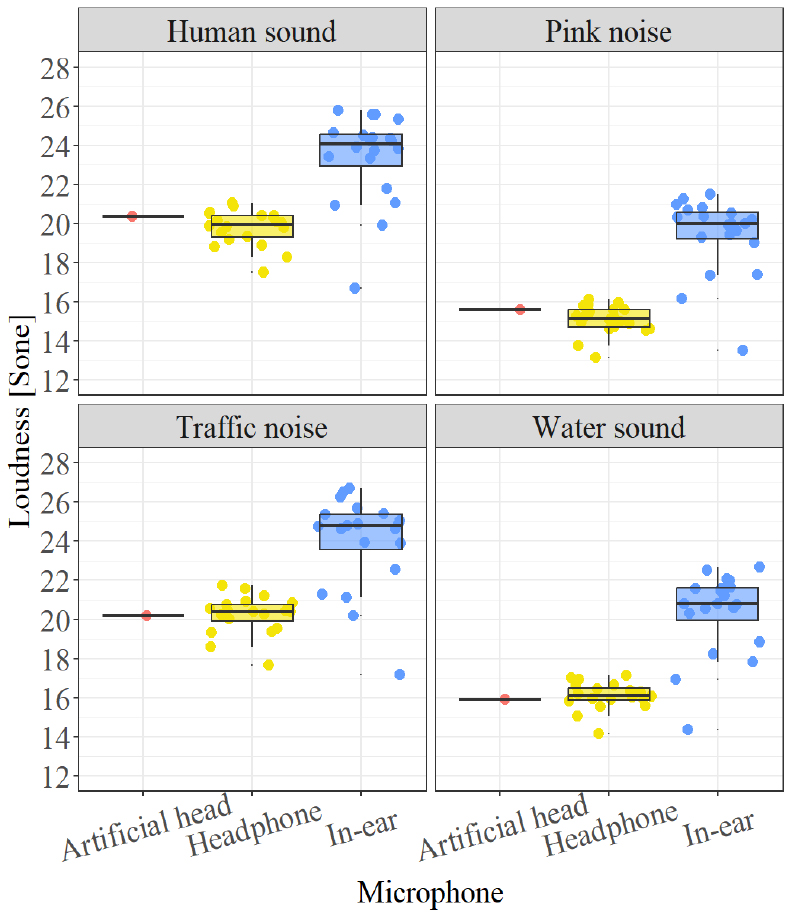
또한, 착용자 간에도 측정결과가 다르게 나타났다. Headphone type은 0.6 dB ~ 1 dB, 0.6 sone ~ 1.1 sone의 차이가 나타났고, In-ear type은 1.1 dB ~ 1.8 dB, 1.3 sone ~ 1.8 sone의 차이가 나타났다. Headphone type보다 In-ear type에서 착용자에 의한 차이가 크게 나타난 것을 확인할 수 있다. 착용자에 의한 차이는 1사분위수와 3사분위수 간의 차이를 나타낸다.
음원에 따라서도 측정결과가 다르게 나타나는 것을 확인할 수 있다. 사람소리와 도로교통 소음보다 핑크노이즈와 물소리에서 마이크로폰 간 차이가 크게 나타났다.
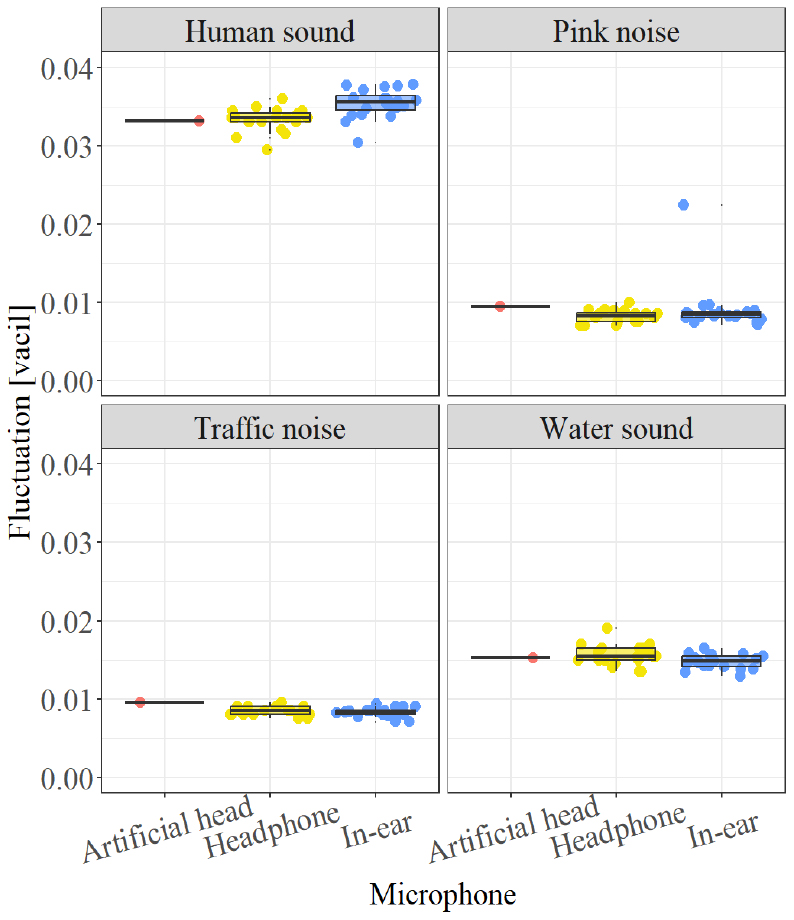
Figs. 5, 6, 7은 음원별로 마이크로폰에 따른 Sharpness, Roughness와 Fluctuation strength를 비교한 결과를 나타낸다. Sharpness의 경우, Headphone type은 0.1 acum ~ 0.2 acum 더 낮은 값, In-ear type은 0.3 acum ~ 0.5 acum 더 높은 값을 보였다. Roughness는 다른 지표들과 다르게 In-ear type이 Headphone type보다 인공 머리 시뮬레이터와 유사한 결과를 보였다. Headphone type이 인공 머리 시뮬레이터보다 0.02 asper ~ 0.1 asper 더 높게, In-ear type은 0.01 asper ~ 0.07 asper 더 낮게 나타났다. Fluctuation strength는 Headphone type과 In-ear type 모두 인공 머리 시뮬레이터와 0.01 미만의 차이로 유사한 결과를 보였다.
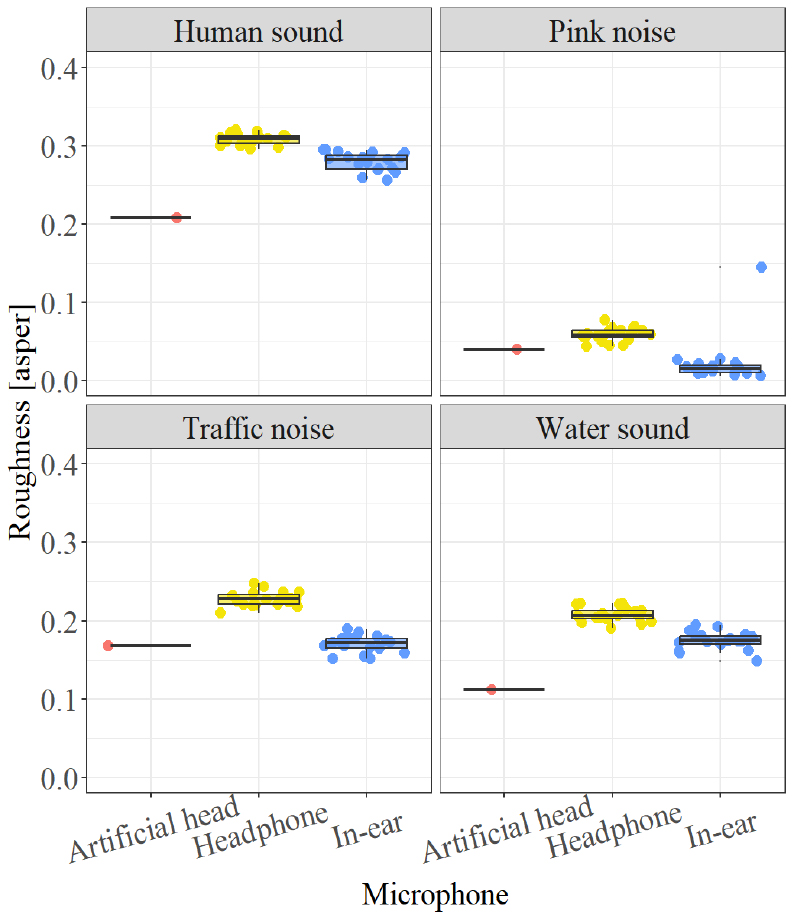
착용자 간의 차이는 여러 음원에 따라 Headphone type은 Sharpness의 경우 0.2 acum ~ 0.4 acum의 차이가 발생했으며, Roughness는 0.02 asper ~ 0.1 asper의 차이가 착용자 간에 나타났다. In-ear type은 Sharpness 0.3 acum ~ 0.4 acum, Roughness 0.00 ~ 0.07, Fluctuation strength의 차이가 나타났다. LAeq, Loudness와 마찬가지로 Headphone type보다 In-ear type에서 착용자에 의한 차이가 크게 나타났다.
LAeq와 모든 심리 음향 지표에서 In-ear type과 인공 머리 시뮬레이터 간의 차이는 Headphone type과 인공 머리 시뮬레이터 간의 차이보다 약 두 배정도로 크게 나타났다. 또한, 착용자에 의한 차이도 Headphone type보다 In-ear type이 더 크게 나타났다.
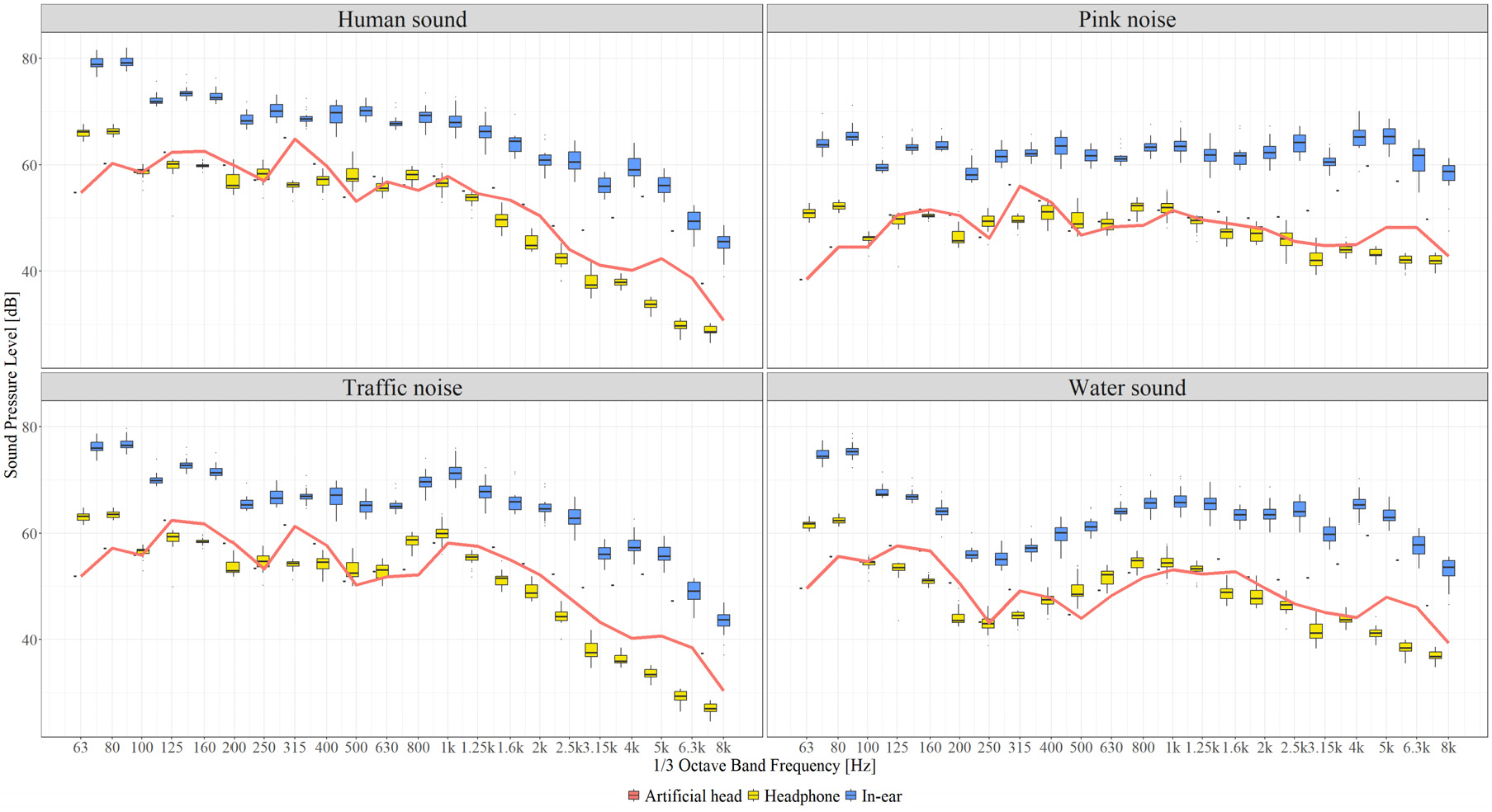
Fig. 8은 녹음한 소리의 1/3 옥타브 밴드 주파수 대역별 음압레벨(Sound pressure level, SPL) 값을 음원별로 구분하여 나타낸 그래프이다. Headphone type과 In-ear type을 비교한 결과, 모든 음원에서 In-ear type이 Headphone type 보다 높은 음압을 나타냈으며, 특히 고주파수 영역에서 그 차이가 두드러졌다. 2 kHz까지는 인공 머리 시뮬레이터와 Headphone type가 유사한 값을 보였으나, 2 kHz 이상의 고주파 대역의 곡선에서부터 차이가 발생하다 5 kHz에서 가장 큰 차이를 보였다. 각 피험자 간에도 40 Hz ~ 200 Hz 구간이 넓고 고르게 분포된 핑크노이즈와 물소리에서는 두 마이크로폰 간의 녹음 결과가 유사했으나, 주파수 특성이 다른 사람소리와 도로교통 소음에서는 차이가 두드러졌다.
IV. 토 의
4.1 바이노럴 마이크로폰 종류에 따른 차이
Cubick et al.[6]은 다양한 인공 머리 시뮬레이터와 바이노럴 마이크로폰 간의 외부화 정도를 비교했다. 실험결과, 마이크로폰이 귀관 외부에 위치한 인공 머리 시뮬레이터의 녹음 결과가 귀관 내부에서 녹음한 결과보다 더 낮은 점수를 보였다. 또한, Wersényi[15]은 다양한 Artificial head의 방향성 특성과 HRTF의 차이를 분석하였다. 연구 결과, 귀 모양이 HRTF의 방향성 특성과 소리의 위치 인식에 중요한 영향을 미친다는 결과가 나타났다. 본 연구에서도 사람의 귀 내부에서 녹음하는 In-ear type 마이크로폰과 귀 외부에서 녹음하는 Headphone 및 인공 머리 시뮬레이터 간의 차이가 나타났다. 특히, 본 연구에서 사용한 인공 머리 시뮬레이터는 귀관이 반영되지 않은 제품이기 때문에 이러한 차이가 더욱 두드러졌을 수 있다.
4.2 바이노럴 마이크로폰 착용자에 의한 차이
여러 측정자들이 녹음한 개별 양이 공간 임펄스 리스펀스(Binaural Room Impulse Response, BRIR)과 인공 머리 시뮬레이터로 녹음한 BRIR을 비교한 연구에서는 개별 BRIR이 개인화된 청취 경험을 제공하는 데 유리한 결과가 나타났다. 하지만, 일반 BRIR은 더 보편적인 데이터를 제공하여 여러 사람에게 적용할 수 있다는 결과가 도출되었다.[6] 또한, Minnaar et al.[16]은 인공 머리와 인간 머리에서의 바이노럴 녹음을 통해 소리의 위치 인식에 대해 연구했다. 연구 결과, 인공 머리로 녹음한 경우와 다른 사람 머리로 녹음한 경우, 개별로 녹음한 경우에 비해 떨어지는 결과가 나타났다. 본 연구에서는 주관적 평가를 진행하지 않았기 때문에 개인화된 청취 경험 여부를 확인할 수는 없었으나, 이전 연구와 마찬가지로 개인별 측정 데이터와 인공 머리 시뮬레이터로 측정한 데이터 간에 발생한 것을 확인하였다.
Table 8은 개인 간 차이가 발생한 이유를 탐색하기 위해 개인별 신체 측정데이터와 평가지표들 간의 상관관계 분석을 진행한 결과이다. 분석 결과, 모든 평가지표에서 p > 0.05 으로 나타나 측정자의 신체데이터와 소음 및 심리음향지표 간에 유의미한 상관관계는 발견되지 않았다. 본 연구에서는 키, 어깨너비와 머리 둘레의 신체 데이터만을 측정하였다. 하지만, HRTF를 예측하기 위해선 더 다양한 지표들이 필요하고 신체 측정 데이터와 HRTF의 관계는 단순한 선형 모델이 아니기 때문에[13] 상관관계가 나타나지 않은 것으로 추측된다. 향후 연구에서는 이러한 비선형 관계를 이해하고 개인화된 HRTF를 예측을 통해 적용된 음향 필터의 적용이 필요하다.
Table 8.
Correlation coefficients between body measurement data and LAeq, psychoacoustic parameters.
4.3 심리음향지표별 최소 식별차이와의 비교
Just Noticeable difference(JND)는 감각 자극의 강도가 변화할 때, 그 변화가 감지될 수 있는 최소한의 차이를 의미한다. You[17]에 의하면 냉장고 소음에 대한 심리음향지표의 JND는 Loudness 0.5 sone, Sharpness 0.08 acum, Roughness 0.04 asper, Flucuation strength 0.012 vacil로 보고되었다. 다만 이전 연구는 냉장고 소음만을 대상으로 JND를 제시한 반면, 본 연구에서 사용한 음원은 물소리, 사람소리, 도로교통 소음, 핑크노이즈로 구성되어 냉장고 소음과는 차이가 있다.
본 연구에서 마이크로폰 종류 간에 발생한 차이를 비교한 결과, Headphone type과 인공머리 시뮬레이터 간에 LAeq 0.3 dB ~ 0.8 dB, Loudness 0.2 sone ~ 0.4 sone, Sharpness 0.1 acum ~ 0.2 acum, 0.02 asper ~ 0.1 asper로 나타났으며, Fluctuation strength는 유사한 값을 보였다. 이는 이전 연구에서 제시한 냉장고 소음의 JND 이하의 값으로, Headphone type과 인공머리 시뮬레이터 간의 차이는 사람이 감지하지 못할 수준일 것으로 추측할 수 있다. 반면, In-ear type과 인공머리 시뮬레이터와의 차이는 LAeq 1.7 dB ~ 4.1 dB, Loudness 3.7 sone ~ 4.9 sone, Sharpness 0.3 acum ~ 0.5 acum, Roughness 0.01-0.07 asper로 나타나 이전 연구의 JND를 초과하는 수준이다. 이는 In-ear type과 인공머리 시뮬레이터 간의 차이는 사람이 감지할 수 있을 가능성이 있음을 의미한다.
또한, 바이노럴 마이크로폰 착용자에 의한 차이는 Headphone type에서 LAeq 0.6 dB ~ 1.0 dB, Loudness 0.6 sone ~ 1.1 sone, Sharpness 0.2 acum ~ 0.4 acum, Roughness 0.02 asper ~ 0.1 asper로 나타났고, In-ear type에서는 이보다 더 큰 차이를 보였다. 이는 이전 연구에서 평가한 JND보다 높은 결과로, 다른 사람이 녹음한 소리에 대해 사람이 그 변화를 감지할 수 있음을 의미한다. 향후 연구에서는 본 연구에서 사용한 다양한 음원에 대한 JND를 제시하고, 이를 기반으로 연구 결과에서 나타난 차이를 보다 정확히 비교할 필요가 있다.
4.4 한계점 및 향후 연구
Xu와 Kang[4]은 주관적 평가를 통해 모노럴과 바이노럴 녹음을 비교한 결과, 바이노럴 녹음이 전체 인상, 음향 편안함, 쾌적함 등에서 모노럴 녹음보다 더 나은 평가를 받았다. 또한 Hong et al.[14]은 스피커 배열 통해 다양한 소리 자극을 경험하고, 각 자극에 대해 인지소음레벨(Perceived Noise Level, PNL)과 음질(Overall Soundscape Quality, OSQ)을 평가했다. 그러나 이 연구들은 청취자의 개인적 경험과 감정에 따라 결과가 달라질 수 있는 주관적 평가에만 의존했다는 한계가 있다. 반면 본 연구는 다양한 바이노럴 마이크로폰으로 녹음한 소리에 대해 물리적인 음향 지표 분석만을 실시하였으며, 실제 청취자가 소리를 들었을 때의 차이를 반영하지는 못했다. 따라서 두 연구 결과를 종합해보면, 물리적 평가와 주관적 평가를 함께 진행하는 것이 보다 포괄적이고 정확한 결과를 도출하는 데 유리할 것이다. 향후 연구에서는 주관적 평가와 물리적 평가를 모두 포함해 청취자가 소리를 어떻게 인식하는지를 분석하고, 이를 물리적 음향 분석과 비교하는 것이 필요하다.
V. 결 론
본 논문은 사운드스케이프 평가 시 바이노럴 마이크로폰 간의 LAeq, 심리 음향 지표 차이를 비교 분석하였다. 이를 위해 현장에서 녹음한 3개의 음원(물소리, 사람소리, 도로교통 소음)과 핑크노이즈, 총 4개의 음원에 대해 평가를 진행하였으며, 총 20명의 대학생이 각 바이노럴 마이크로폰을 착용하고 실험을 수행하였다. 녹음된 소리들은 Artemis Suite 분석 프로그램을 사용하여 LAeq, 심리음향지표 등을 분석하였으며, 주요 결과는 다음과 같다.
1) 두 바이노럴 마이크로폰(Headphone type과 In-ear type)을 비교한 t-test 분석 결과, Fluctuation strength를 제외한 모든 지표에서 유의미한 차이가 나타났다. 이러한 결과는 바이노럴 녹음 시에 사용하는 마이크로폰 종류에 따라 심리음향지표가 다르게 측정될 수 있다는 것을 의미한다.
2) 인공 머리 시뮬레이터와 두 바이노럴 마이크로폰의 비교에서 Headphone type이 인공 머리 시뮬레이터와 더 유사한 결과를 보였으며, 특히 사람소리와 도로교통 소음에서 In-ear type과 다른 마이크로폰 간 차이가 크게 나타났다. 또한, 핑크노이즈와 물소리에서 Headphone type과 In-ear type의 차이가 크게 나타났다. 특히, Headphone type의 표준편차는 In-ear type보다 작았다. 이는 Headphone type과 인공 머리 시뮬레이터는 표준화된 귀 모양을 반영하지만, In-ear type은 측정자의 귀 모양을 반영하기 때문에 표준편차가 크게 나타난 것으로 보인다.
3) 피험자들의 신체 데이터와 평가지표들 간의 상관관계 분석 결과에서 유의미한 상관관계가 발생하지 않았다. 이는 HRTF와 신체 데이터 간의 복잡한 비선형 관계 때문으로 추정된다.
4) Headphone type과 인공머리 시뮬레이터 간의 차이가 JND 이하로 나타나 청취자가 변화를 감지하기 어려울 것으로 사료된다. 그러나 In-ear type과 인공머리 시뮬레이터 간의 차이는 JND를 초과해 청취자가 변화를 감지할 수 있는 수준으로 차이를 보였다. 또한, 바이노럴 마이크로폰 착용자에 의한 차이에서도 JND를 초과하는 것으로 나타났다.
본 연구에서는 사운드스케이프 평가 시 바이노럴 마이크로폰 간의 차이를 비교 분석하여 위와 같은 결과를 도출하였다. 이러한 연구 결과는 현재 사운드스케이프 평가 시 사용하고 있는 인공 머리 시뮬레이터를 다른 바이노럴 마이크로폰으로 대체할 경우 측정 음향지표 편차가 발생할 수 있음 나타낸다. 또한 측정 여건과 실험 조건에 따라 사람이 바이노럴 마이크로폰을 착용하고 녹음해야 하는 경우, 개별화된 HRTF가 적용된 음향 필터를 사용하거나 In-ear type 보다 Headphone type을 사용하는 것이 사용자 간 영향을 최소화할 수 있는 것으로 보인다.
본 연구의 피험자는 20명의 대학생으로 작은 샘플 크기로 인해 결과의 일반화에 한계가 있다. 따라서 다양한 연령대와 신체 조건을 가진 피험자 집단을 포함한 추가 연구가 필요하다.
