

I. 서 론
II. 히스토그램 등화기법
III. 보조 데이터를 이용한 히스토그램 등화기법
IV. 실험 설계 및 결과 분석
4.1 다수 투표
4.2 데이터베이스
4.3 특징 추출 및 화자 모델 학습
4.5 사용한 VoIP 코덱
4.4 실험 결과
V. 결 론
I. 서 론
채널 불일치에 의한 화자 인식 시스템의 성능 저하를 방지하기 위해, 일반적으로 특징 정규화 방법을 사용한다. 기존의 특징 정규화 방법으로 캡스트럼 평균 정규화(Cepstral Mean Normalization),[1] 평균-분산 정규화(Mean and Variance Normalization)[2] 등이 있다. 기존의 특징 정규화 방법은 간단한 선형 변환을 사용하여 특징을 정규화 한다. 선형 변환은 음성 특징에 선형적으로 작용하는 채널 잡음을 제거하는데 효과적이다. 그러나 비선형적으로 작용하는 잡음에는 효과적이지 못하다. 이를 해결하려는 노력으로 비선형적인 잡음 특성을 선형으로 근사하여 처리하는 VTS(Vector Taylor Series)[3]와 SLA(Static Linear Approximation)[4] 등의 연구가 진행되었다. 이러한 접근 방법과 다른 접근 방법으로 히스토그램 등화기법(Histogram Equalization)[5]이 제안되었다. 히스토그램 등화기법은 디지털 이미지 프로세싱에서 디지털 이미지의 밝기와 대비를 조절하기 위해 사용되었다.[5] 히스토그램 등화기법은 이미지 프로세싱 뿐만 아니라, 음성 인식 분야[6-7]와 화자 인식 분야[10]에서 특징 정규화 방법으로 사용되었다. 또한, 히스토그램 등화기법의 응용방법으로 feature warping,[8] modified segmental HEQ[9] 가 제안되었다. 히스토그램 등화기법은 누적 분포 함수(Cumulative Distribution Function)를 기반으로 입력 샘플의 비선형 변환을 가능하게 한다. 그러나 히스토그램 등화기법은 누적 분포 함수 추정을 위해 충분한 길이의 입력 샘플을 필요로 하므로, 입력 샘플의 길이가 짧은 경우 기존의 특징 정규화 방법보다 화자 식별 성능이 떨어질 수 있다. 이런 짧은 입력 샘플에 대한 누적 분포 함수의 강인한 추정을 위해, 이전 연구에서는 배경 화자 모델 학습 데이터에 퍼지 C-Means를 수행한 결과물인 클러스터 중심들을 보조 데이터로 이용한다.[13] 하지만 이 방법은 인식 시점에서 최적의 보조 데이터 수를 추정하기 어려운 문제점이 있었다. 이러한 문제점을 해결하기 위해, 본 논문에서는 다양한 길이의 보조데이터를 이용하여 각기 히스토그램 등화기법을 수행하고, 다수 투표 기반으로 앙상블 결합함으로써 이전의 제안한 방법을 개선하고자한다.
본 논문은 2장에서 히스토그램 등화기법에 대해 설명하고, 3장에서는 보조 데이터를 이용한 히스토그램 등화기법에 대해 설명한다. 4장에서 실험 설계 및 실험 결과를 보이고, 마지막으로 결론을 맺는다.
II. 히스토그램 등화기법
히스토그램 등화기법의 목적은 주어진 확률 분포를 기준이 되는 확률 분포로 변환하는 것이다. 주어진 확률 분포를 변환하기 위해 누적 분포 함수값을 기준 분포의 동일한 누적 분포 함수 값으로 변환한다. 히스토그램 등화기법의 변환식은 다음과 같다.[9]
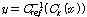 .
.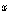 는 입력된 샘플이며,
는 입력된 샘플이며,  는 변환된 샘플이다.
는 변환된 샘플이다. 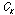 는
는 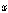 의 누적 분포 함수이며,
의 누적 분포 함수이며, 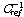 는 기준 누적 분포 함수의 역함수이다.
는 기준 누적 분포 함수의 역함수이다.
히스토그램 등화기법의 구현 방법으로는 누적 히스토그램 기반과 순서 기반의 히스토그램 등화기법이 있다. 누적 히스토그램 등화 기법의 누적 분포 함수 추정 과정은 다음과 같다.[9]
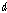 번째 차원, 길이
번째 차원, 길이 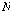 으로 이루어진 입력 시퀀스
으로 이루어진 입력 시퀀스 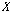 를 다음과 같이 정의한다.
를 다음과 같이 정의한다.
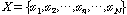 .
.입력된 시퀀스 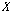 에서 최대값
에서 최대값 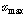 와 최소값
와 최소값 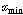 을 찾는다.
을 찾는다. 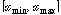 의 범위를 동일한 크기로
의 범위를 동일한 크기로 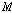 등분한다. 등분한 범위를
등분한다. 등분한 범위를 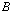 라 하고, 다음과 같이 정의한다.
라 하고, 다음과 같이 정의한다.
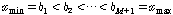 .
.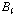 는
는 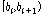 의 범위를 갖는다.
의 범위를 갖는다. 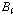 를 빈(bin)이라 한다. 이렇게 얻어진 빈들을 가지고 히스토그램을 측정한다. 각 빈에 속하는 입력 시퀀스
를 빈(bin)이라 한다. 이렇게 얻어진 빈들을 가지고 히스토그램을 측정한다. 각 빈에 속하는 입력 시퀀스 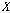 의 원소 개수를 세어 히스토그램을 측정한다. 다음과 같이 측정한 히스토그램을 정규화한다.
의 원소 개수를 세어 히스토그램을 측정한다. 다음과 같이 측정한 히스토그램을 정규화한다.
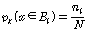 .
.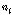 는 빈
는 빈 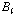 에 속하는 원소 개수이며,
에 속하는 원소 개수이며, 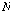 은 입력된 시퀀스의 전체 원소 개수이다.
은 입력된 시퀀스의 전체 원소 개수이다.
정규화한 히스토그램을 이용하여 다음과 같이 누적 히스토그램을 계산한다.
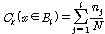 .
.누적 히스토그램을 이용한 입력 시퀀스의 변환은 식(1)을 이용한다.
순서 기반 히스토그램 등화기법의 누적 분포 함수 추정 과정은 다음과 같다.
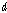 번째 차원, 길이
번째 차원, 길이 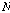 으로 이루어진 입력 시퀀스
으로 이루어진 입력 시퀀스 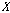 를 식(2)와 같이 정의한다. 입력 시퀀스
를 식(2)와 같이 정의한다. 입력 시퀀스 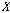 의 오름차순 서열을 구한다.
의 오름차순 서열을 구한다.
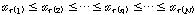 .
.이때, 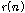 은
은 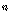 번째 서열을 갖는 원소의 인덱스이다. 측정한 서열은 입력 시퀀스
번째 서열을 갖는 원소의 인덱스이다. 측정한 서열은 입력 시퀀스 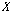 의 누적 분포 함수를 측정하는데 사용한다.
의 누적 분포 함수를 측정하는데 사용한다.
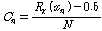 .
.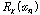 은
은 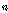 번째 원소의 오름차순 서열을 의미한다. 추정한 누적 분포 함수를 식(1)에 적용하여 입력 시퀀스를 변환한다.
번째 원소의 오름차순 서열을 의미한다. 추정한 누적 분포 함수를 식(1)에 적용하여 입력 시퀀스를 변환한다.
본 논문에서는 기준 분포 함수로 표준 정규 분포를 사용하였다. 표준 정규 분포를 이용한 누적 분포 함수의 역변환은 누적 분포 함수 표를 사용하면 쉽게 구할 수 있다. 표준 정규 분포의 확률 밀도 함수는 다음과 같다.
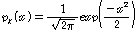 .
.III. 보조 데이터를 이용한 히스토그램 등화기법
보조 데이터를 이용한 히스토그램 등화기법[13]은 순서 기반 히스토그램 등화기법의 응용 방법이다. 보조 데이터를 만들기 위해 배경 화자 모델 학습을 위한 데이터에서 화자별로 퍼지 C-Means[11]를 수행한다. 각 화자의 퍼지 C-Means 중심을 모으고, 오름차순으로 정렬하여 보조 데이터를 구성한다. 여기서 소속 함수의 퍼지성을 결정하는 변수 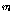 은 2로 설정하였다. 보조 데이터를 이용한 히스토그램 등화기법의 자세한 방법은 다음과 같다. 먼저, 배경 화자 모델 학습 데이터 중
은 2로 설정하였다. 보조 데이터를 이용한 히스토그램 등화기법의 자세한 방법은 다음과 같다. 먼저, 배경 화자 모델 학습 데이터 중 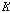 명 화자의 음성 데이터를 무작위로 선택한 집합을
명 화자의 음성 데이터를 무작위로 선택한 집합을 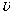 라 하자.
라 하자.
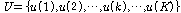 .
.이때, 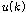 는 선택된
는 선택된 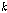 번째 화자의 음성 데이터이며,
번째 화자의 음성 데이터이며, 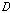 차원 특징 벡터의 관측 시퀀스이다.
차원 특징 벡터의 관측 시퀀스이다.
각 화자의 음성 데이터 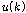 에 퍼지 C-Means를 수행하여 중심 벡터 집합
에 퍼지 C-Means를 수행하여 중심 벡터 집합 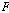 를 얻는다.
를 얻는다.
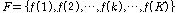 .
.이때, 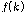 는
는 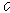 개의 퍼지 C-Means 중심 벡터의 집합으로 구성된다.
개의 퍼지 C-Means 중심 벡터의 집합으로 구성된다. 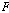 의
의 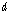 번째 차원 원소를 모두 연결한 길이
번째 차원 원소를 모두 연결한 길이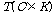 의 보조 데이터
의 보조 데이터 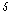 를 다음과 같이 구성한다.
를 다음과 같이 구성한다.
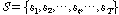 .
.변환하고자 하는 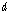 번째 차원, 길이
번째 차원, 길이 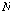 으로 이루어진 입력 시퀀스
으로 이루어진 입력 시퀀스 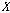 를 식(2)와 같이 정의한다.
를 식(2)와 같이 정의한다.
입력 시퀀스 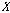 의 오름차순 서열은 다음과 같이 구한다.
의 오름차순 서열은 다음과 같이 구한다.
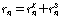 .
.이때, 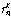 는 시퀀스
는 시퀀스 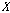 를 기준으로 한 입력 시퀀스
를 기준으로 한 입력 시퀀스 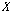 에 속하는
에 속하는 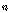 번째 원소의 오름차순 서열이다.
번째 원소의 오름차순 서열이다. 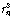 는 시퀀스
는 시퀀스 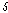 를 기준으로 한 입력 시퀀스
를 기준으로 한 입력 시퀀스 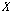 에 속하는
에 속하는 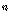 번째 원소의 오름차순 서열이다. 즉, S 내에서 X의 n번째 원소가 오름차순으로 정렬되었을 때 몇 번째인지를 나타낸다. 새로운 서열은 두 오름차순 서열의 합으로 정하며, 새로운 서열을 이용하여 누적 분포 함수를 추정한다.
번째 원소의 오름차순 서열이다. 즉, S 내에서 X의 n번째 원소가 오름차순으로 정렬되었을 때 몇 번째인지를 나타낸다. 새로운 서열은 두 오름차순 서열의 합으로 정하며, 새로운 서열을 이용하여 누적 분포 함수를 추정한다.
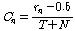 .
.새롭게 추정한 누적 분포 함수를 식(1)에 적용하여 입력 시퀀스를 변환한다.
IV. 실험 설계 및 결과 분석
4.1 다수 투표
본 논문에서는 분류기 앙상블 결합 방법으로 다수 투표[14]를 사용하였다. 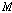 명의 화자 모델이 존재할 때, 부류 표지 벡터
명의 화자 모델이 존재할 때, 부류 표지 벡터 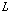 은 다음과 같이 정의 할 수 있다.
은 다음과 같이 정의 할 수 있다.
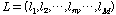 .
.이때, 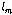 ∈{0, 1}은
∈{0, 1}은 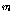 번째 화자의 선택 유무이다. 또,
번째 화자의 선택 유무이다. 또, 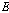 개의 분류기가 존재한다고 가정하면,
개의 분류기가 존재한다고 가정하면, 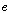 번째 분류기의 출력은 다음과 같다.
번째 분류기의 출력은 다음과 같다.
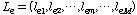 .
.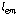 은
은 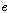 번째 분류기에서
번째 분류기에서 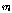 번째 화자의 선택 유무를 나타낸다. 이 부류 표지 벡터를 이용한 다수 투표의 분류 방법은 다음과 같다.
번째 화자의 선택 유무를 나타낸다. 이 부류 표지 벡터를 이용한 다수 투표의 분류 방법은 다음과 같다.
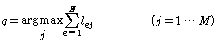 ,
,4.2 데이터베이스
제안한 방법의 성능 평가를 위해 ETRI(Electronics and Telecommunications Research Institute)에서 배포한 한국어 중가 마이크 화자인식용 음성 데이터베이스를 이용하였다. ETRI 데이터베이스는 조용한 사무실 환경에서 수집되었으며, 주차 100명, 월차 100명 3개월차 50명, 총 250명의 화자로 구성되어 있다. 각 화자는 2연 숫자, 4연 숫자, 문장 발성을 수행하였으며, 기간별로 4회 시차 발성과 5회 반복발성을 수행하였다. ETRI 데이터베이스는 16 kHz 표본화 주파수로 녹음되었으며, 본 연구에서는 VoIP 코덱 적용을 위해 8 kHz 표본화 주파수로 변환하였다.
배경 화자 학습을 위해 월차 100명과 3개월차 50명의 1시차 1회차 10~19 번 문장 발성을 이용하였다. 배경 화자 학습에 사용한 총 발화 수는 1500개(150명 × 10문장)이다.
화자 모델 적응을 위해 주차 100명의 1시차 1회차 10~19 번 문장 발성을 이용하였다. 화자 모델 적응을 위해 사용한 총 발화 수는 1000개(100명 × 10문장)이다.
시스템 성능을 평가하기 위해, 주차 100명의 2, 3, 4시차 1회차 10~19 번 문장 발성을 사용하였다. 평가를 위해 사용한 총 발화 수는 3000개(3 시차 × 100 명 × 10 문장)이다. 테스트 데이터는 VoIP 코덱을 이용하여 시뮬레이션 되었다.
4.3 특징 추출 및 화자 모델 학습
본 연구에서는 18차 MFCC(Mel Frequency Cepstral Coefficients)를 사용하였다. MFCC 특징 추출을 위해 pre-emphasis filter(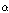 =0.97)를 수행하고, 25 ms 크기의 윈도우로 10 ms 마다 분할하였다. 각 프레임에는 해밍 윈도우가 적용되었고, 26개의 mel 필터를 거쳐 이산 코사인 변환을 수행하였다.
=0.97)를 수행하고, 25 ms 크기의 윈도우로 10 ms 마다 분할하였다. 각 프레임에는 해밍 윈도우가 적용되었고, 26개의 mel 필터를 거쳐 이산 코사인 변환을 수행하였다.
GMM-UBM[12] 방법으로 화자 모델을 학습하였다. 화자 모델은 128개 혼합 수의 배경 화자 모델로부터 MAP(Maximum A Posteriori)[12] 적응 방법을 사용하여 화자 모델을 구성하였다.(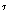 =1)
=1)
4.5 사용한 VoIP 코덱
화자 식별 실험을 위해 사용한 테스트 데이터는 VoIP 코덱으로 시뮬레이션 되었다. 사용한 VoIP 코덱은 G.729,[15] SILK,[16] Speex[17] 이다. Table 1은 사용한 코덱의 상세정보를 보여준다.
Table 1. Specification of the codecs used in the experiments. | |||
Codec | Organization | Sampling rate | Version |
G.729 | ITU-T | 8 kHz | 3.3 |
SILK | Skype | 8, 12, 16, 24 kHz | 1.0.7 |
Speex | Xiph.org | 8, 16, 32 kHz | 1.2rc1 |
4.4 실험 결과
제안한 방법(proposed)의 성능을 평가하기 위해 캡스트럼 평균 정규화(CMN), 평균-분산 정규화(MVN), 누적 히스토그램기반 히스토그램 등화기법(CHEQ, Cumulative histogram based HEQ), 순서 기반 히스토그램 등화기법(OHEQ, Order statistics based HEQ), 보조 데이터를 이용한 히스토그램 등화기법[SHEQ(FCM), Supplement set based HEQ(Fuzzy C-Means)]과 비교하였다. 누적 히스토그램기반 히스토그램 등화기법을 위해 1000개의 빈을 사용하였고, 보조 데이터를 이용한 히스토그램 등화기법을 위해 배경 화자 모델 학습 데이터에서 10명의 화자를 무작위로 선택하였다. 보조 데이터를 이용한 히스토그램 등화기법은 선택한 화자의 음성 데이터로부터 퍼지 C-Means의 중심 수를 늘려가며 실험을 수행하였다.
다수 투표 기반의 제안한 방법은 보조 데이터를 이용한 히스토그램 등화기법에서 사용한 9개 분류기(화자 당 중심개수: 10, 15, 20, 25, 30, 35, 40, 45, 50)를 다수 투표 방식으로 결합하여 화자 식별 오류율을 측정하였다.
Fig. 1은 G.729 환경에서 화자 식별 실험을 수행한 결과를 보여준다. 다수 투표 기반의 제안한 방법은 15.9 %의 화자 식별 오류율을 보였다. 보조 데이터를 이용한 히스토그램 등화기법은 16.27 % ~ 18.2 %의 화자 식별 오류율을 보였으며, 평균 화자 식별 오류율은 17.3 %였다. 다수 투표기반의 제안한 방법은 기존의 특징 정규화 방법보다 상대 오류가 24 %(MVN) ~ 35.9 %(MFCC) 감소하였다. 보조 데이터를 이용한 히스토그램 등화기법이 최고 성능을 가질 때보다 2.5 % 상대 오류가 감소하였고, 평균 성능에 비해 8.4 % 상대 오류가 감소하였다.
Fig. 2는 SILK 환경에서 화자 식별 실험을 수행한 결과를 보여준다. 다수 투표 기반의 제안한 방법은 10.6 %의 화자 식별 오류율을 보였다. 보조 데이터를 이용한 히스토그램 등화기법은 10.8 % ~ 12.4 %의 화자 식별 오류율을 보였고, 평균 성능은 11.7 %였다. 제안한 방법은 기존의 특징 정규화 방법에 비해 상대 오류가 18.6 %(MFCC) ~ 46.5 %(CHEQ) 감소하였다. 보조 데이터를 이용한 히스토그램 등화기법이 가장 좋은 성능을 가질 때, 상대 오류가 1.5 % 감소하였고, 평균 성능을 가질 때, 상대 오류가 9 % 감소하였다.
|
Fig. 1. Speaker identification error rates in G.729 environment. |
|
Fig. 2. Speaker identification error rates in SILK environment. |
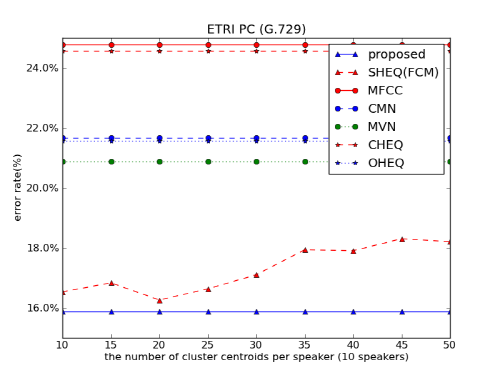
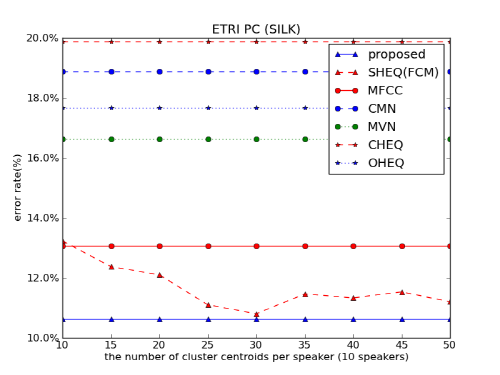
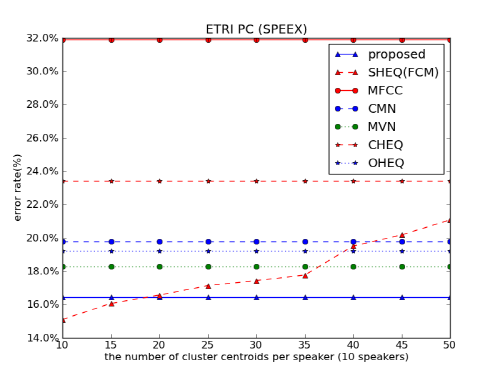
Fig. 3은 Speex 환경에서 화자 식별 실험을 수행한 결과이다. 제안한 방법은 16.4 %의 화자 식별 오류율을 보였다. 보조 데이터를 이용한 히스토그램 등화기법은 15.1 % ~ 21.1 %의 화자 식별 오류율을 나타내며, 평균 성능은 17.9 %였다. 제안한 방법은 다른 특징 정규화 방법에 비해 상대 오류가 48.4 %(MFCC) ~ 10 %(MVN) 감소하였다. 보조 데이터를 이용한 히스토그램 등화기법이 최고 성능을 가질 때, 제안한 성능의 상대 오류가 8.8 % 늘었지만, 평균 성능에 비해 상대 오류가 8 % 감소하였다. 실시간 인식의 경우 최고 성능을 갖는 파라미터를 찾기 어렵기 때문에, 다수 투표를 기반으로 한 방법을 적용하여 이러한 문제를 해결할 수 있음을 확인하였다.
V. 결 론
본 논문에서는 다수 투표 기반의 히스토그램 등화기법을 제안하였다. 다수 투표 시스템을 이루는 분류기는 이전에 제안한 보조 데이터를 이용한 히스토그램 등화기법에서 얻은 화자 모델로 구성하였다. 각 화자 모델은 다양한 크기의 보조 데이터를 사용하여 히스토그램 등화기법을 수행하고, 화자 적응 방법을 이용하여 구성하였다. 채널 불일치 환경을 시뮬레이션 하기 위해 테스트 데이터에 VoIP 코덱을 적용하였다. 따라서 학습 데이터는 클린 환경의 음성 발화이고, 테스트 데이터는 VoIP 환경의 음성 발화이다. 다수 투표 기반의 제안한 방법은 기존의 특징 정규화 방법보다 성능이 향상되었고, 이전에 제안한 보조 데이터를 이용한 히스토그램 등화기법보다도 성능이 향상되었다.
Speex 환경에서는 이전에 제안한 방법이 최고 성능을 가질 때보다 성능이 하락하였지만 평균 성능 보다는 상승하였다. 성능 하락의 원인은 보조 데이터를 이용한 히스토그램 등화기법의 성능 하락 구간에 위치하는 여러 분류기를 포함하여 제안한 방법의 성능 향상 폭이 크지 않았던 것으로 생각된다.
추후, 더 다양한 분류기를 포함하는 투표 시스템을 구성하고, 분류기의 가중치를 고려하는 앙상블 시스템을 구성하면 추가적인 성능 개선이 가능할 것으로 기대된다.
