

I. 서 론
II. DCASE 2020 챌린지 데이터셋
III. 제안된 음향 사건 검지 모델
3.1 RCRNN 기반 평균 교사 모델 기반 음향 사건 검지
3.2 잡음 학생 모델 기반 음향 사건 검지 모델
IV. 성능 평가
4.1 실험 환경
4.2 평가 지표
4.3 결과 비교
V. 결 론
I. 서 론
소리는 일상생활에서의 중요한 정보를 포함하고 있으며 우리 주변에서 발생하는 개별 음향 사건에 따라 해당 장면을 이해하는 데 큰 도움을 준다. [1] 음향 장면 인지 분야는 기계학습 및 인공지능을 기반으로 다양한 알고리즘들이 연구되고 있으며, 다음향 환경에서의 음향 사건을 인지하는 음향 사건 검지 기술이 주목받고 있다. 특히 음향 사건 검지 기술은 음향 인지와 관련된 광범위 응용 분야에 활용될 수 있다. 특히 영상 사건 검지 기술은 날씨, 조도 및 사각지대 등과 같은 환경에서는 검지 불가능하다는 단점을 가지며, 음향 사건 검지 기술은 이러한 영상 사건 검지 기술과 연동되는 방향으로 활용될 수 있다.[1] 또한, 음향 사건 검지 기술은 유리 파손음, 총소리, 타이어 마찰음 또는 자동차 충돌음과 같은 물리적 사건을 검지할 수 있고,[2] 소셜 미디어 콘텐츠를 더 자세히 이해할 수 있는 오디오 자막생성,[3] 생활 지원 및 의료[4] 등에 활용될 수 있다.
음향 사건 검지 모델은 주로 입력 오디오 샘플에 대해 음향 이벤트 종류와 해당 이벤트의 시작 시점과 끝 시점 정보가 표기된 강력하게 레이블링된 데이터를 활용하여 학습된다. 지난 10년 동안 멜-주파수 켑스트럼 계수 기반의 음향 특징을 활용한 Support Vector Machine(SVM)[5] 및 Gaussian Mixed Model-Hidden Markov Model(GMM-HMM)[6,7]과 같이 기계학습 기반의 음향 사건 검지 모델이 제안되었다. 최근 음성인식, 음성합성 등에서 활용되는 심층 신경망 기반 모델을 응용한 음향 사건 검지 기술이 활발히 연구되고 있다. 완전 연결 신경망,[8] 합성곱 신경망(Convolutional Neural Network, CNN),[9,10] 순환 신경망(Recurrent Neural Network, RNN)[11] 및 합성곱 순환 신경망(Convolutional Recurrent Neural Network, CRNN)[12,13]과 같은 다양한 신경망 구조들이 음향 사건 검지 기술에 적용되었다.
앞서 설명한 음향 사건 검지 모델 학습은 강력하게 레이블링된 데이터를 많이 필요로 한다. 이러한 훈련 데이터는 실제 환경에서 수집된 데이터를 활용하여야 한다. 하지만, 이러한 데이터의 레이블을 생성하기 위해서는 큰 비용과 시간이 필요하다. 이에 대한 대안으로 오디오 샘플에 대해 시작 시점과 끝 시점 정보 없이 음향 이벤트 종류만 표기된 약하게 레이블링된 데이터를 결합하여 음향 사건 검지 모델 학습에 사용한다.[1]
강력하게 레이블링된 데이터와 약하게 레이블링된 데이터 외에도 레이블이 지정되지 않은 비표기 데이터(unlabeled data)를 사용하여 음향 사건 검지 성능 향상이 가능하다. 그 방법의 하나는 평균 교사 모델을 활용한 방법이다.[14] 평균 교사 모델 기반의 음향 사건 검지 모델은 학생 및 교사 두개의 모델이 있으며, 여기서 학생 모델은 교사 모델에 의해 예측되는 레이블과 일관성을 향상하는 방향으로 학습된다. 그런 다음, 각 epoch에 대한 학생 모델의 가중치 갱신에 따라 교사 모델도 업데이트된다. 특히 평균 교사 모델의 손실함수는 데이터 유형에 따라 구성한다. 즉 강력하게 레이블링된 데이터에 대한 손실함수는 강력한 레이블 예측값과 대상 레이블 간의 Binary Cross Entropy(BCE)로 학습된다. 또한, 약하게 레이블링된 데이터에 대한 손실함수는 약한 레이블 예측값과 대상 레이블 간의 BCE로 구성된다. 비표기 데이터 학습을 위한 손실함수는 학생 모델과 교사 모델의 예측 사이의 Mean Square Error(MSE)를 사용하여 학습한다. 이는 강력하게 레이블링된 데이터, 약하게 레이블링된 데이터, 그리고 비표기 데이터를 활용하여 학습된다. 이 평균 교사 학습 기반 모델은 Detection and Classification of Acoustic Scenes and Events (DCASE) 2019 챌린지 Task 4의 baseline 모델로 제안되었으며, DCASE 2019 및 DCASE 2020 챌린지 Task 4에서 상위 순위를 달성한 모델에서 평균 교사 모델을 활용하였다.[15] 하지만, 평균 교사 모델의 예측은 완벽하지 않기 때문에, 약하게 레이블링된 데이터와 비표기 데이터에 대해 정확한 음향 종류와 시간 정보를 제공할 수 없다는 단점을 가진다.
이러한 문제를 해결하기 위해 본 논문에서는 강력하게 레이블링된 데이터, 약하게 레이블링된 데이터 및 비표기 데이터를 활용한 음향 사건 검지 기법을 제안한다. 합성곱 순환 신경망 구조의 합성곱 신경망을 잔차 학습을 통해 개선하였다. 또한, 같은 음향 사건에 속하는 샘플이라도 다른 특성을 가질 수 있으므로,[16] 이러한 특성을 학습하기 위하여 많은 합성곱 신경망 층을 활용하여야 한다. 이 경우, 각 합성곱 층은 잔차 학습을 사용하면 기울기 소실 문제를 극복하여 신경망을 더욱 효과적으로 학습할 수 있다. 결과적으로 합성곱 순환 신경망 대신 잔차 합성곱 순환 신경망(Residual Convolutional Recurrent Neural Network, RCRNN)을 활용한다.[17] 또한, 약하게 레이블링된 데이터와 비표기 데이터 활용을 위하여 잡음 학생 모델을 활용한 자가 학습 기반의 음향 사건 검지 기법을 제안한다.
먼저, RCRNN 기반의 평균 교사 모델을 활용하여 강력한 레이블링된 데이터, 약하게 레이블링된 데이터 그리고 비표기 데이터를 포함한 모든 데이터를 활용하여 학습한다. 다음으로, 잡음 학생 모델은 강하게 레이블링된 데이터는 대상 레이블을 사용하고, 약하게 레이블링된 데이터와 비표기 데이터에 대해 앞서 훈련된 RCRNN 기반의 평균 교사 모델을 활용하여 예측된 레이블을 활용하여 학습된다. 특히 self- training 기법[18]을 적용하여 잡음 학생 모델을 학습시킨다. 여기서 잡음 학생 모델은 특징 잡음, 모델 잡음, 그리고 레이블 잡음 세가지를 활용하였다. 특징 잡음의 경우, SpecAugment,[19] mixup,[20] 시간-주파수 이동[21]을 활용하였고, 드롭아웃기반의 모델 잡음, 레이블 잡음에 해당하는 semi-supervised loss function[17]을 활용하여 학습한다.
본 논문의 구성은 다음과 같다. 서론에 이어 II절에서 본 논문에서 사용되는 음향 사건 검지 분야의 데이터셋에 대해 기술한다. 이어서 III절에서는 잡음 학생 모델을 활용한 자가 학습 기반의 음향 사건 검지 기법을 제안한다. 그리고 IV절에서는 제안하는 음향사건 검지 기법의 성능평가 결과에 대해 기술한 후 V절에서는 본 논문의 결론을 맺는다.
II. DCASE 2020 챌린지 데이터셋
DCASE 2020 챌린지 데이터셋은 모델 학습을 위한 데이터셋으로 세가지 데이터셋을 제공한다.[14] 즉, 1) 약하게 레이블링된 데이터셋, 2) 레이블이 지정되지 않은 비표기 데이터셋, 그리고 3) 합성된 강력하게 레이블링된 데이터셋으로 구성된다. 1)과 2) 데이터셋의 경우, 실제 환경에서 수집된 데이터셋인 Audioset에서 가져온 데이터셋에 비해 강력하게 레이블링된 데이터셋은 Scaper soundscape 합성 및 증강 라이브러리를 활용하여 생성된다. 1), 2), 그리고 3) 데이터셋의 경우 각각 1,578개, 14,412개, 그리고 2,584개의 오디오 클립이 포함되어 있다. 또한, 모델 평가에 활용되는 데이터셋으로 공개 평가 데이터셋은 강력한 레이블을 포함한 1,168개의 validation 평가셋이 제공된다. 각각의 오디오 클립은 44.1 kHz로 샘플링되었으며, 최대 10 s 분량으로 구성된다.
주어진 데이터셋은 먼저 모노 채널로 다운 믹싱되고 44.1 kHz는 16 kHz로 다운샘플링된다. 다음으로, 입력 오디오 클립은 255개 샘플의 홉 길이가 있는 2048개 샘플의 연속 프레임으로 분할된다. 그리고 나서, 분리된 각 신호에 2048-point 고속푸리에 변환에 대해 128차원 mel-filterbank 분석을 수행한다. 각 10 s 오디오 클립은 628개의 프레임으로 표현되어 음향 사건 검지 모델의 입력 특성의 크기는 1 × 628 × 128이 된다. 이때, 10 s보다 짧은 오디오 클립에는 zero padding이 적용된다. 마지막으로 추출된 멜 스펙트로그램은 모든 학습 오디오 클립에 대한 전역 평균과 표준 편차로 정규화된다.
III. 제안된 음향 사건 검지 모델
3.1 RCRNN 기반 평균 교사 모델 기반 음향 사건 검지
Fig. 1과 같이 제안된 음향 사건 검지 모델의 첫 번째 단계는 RCRNN 기반 평균 교사 모델을 기반으로 구성되며,[17] 이는 CRNN 기반의 평균 교사 모델[14]을 RCRNN으로 대체한 동일한 모델 구조를 가진다. Table 1은 평균 교사 모델에 사용된 RCRNN의 구조와 파라미터를 보여 준다.
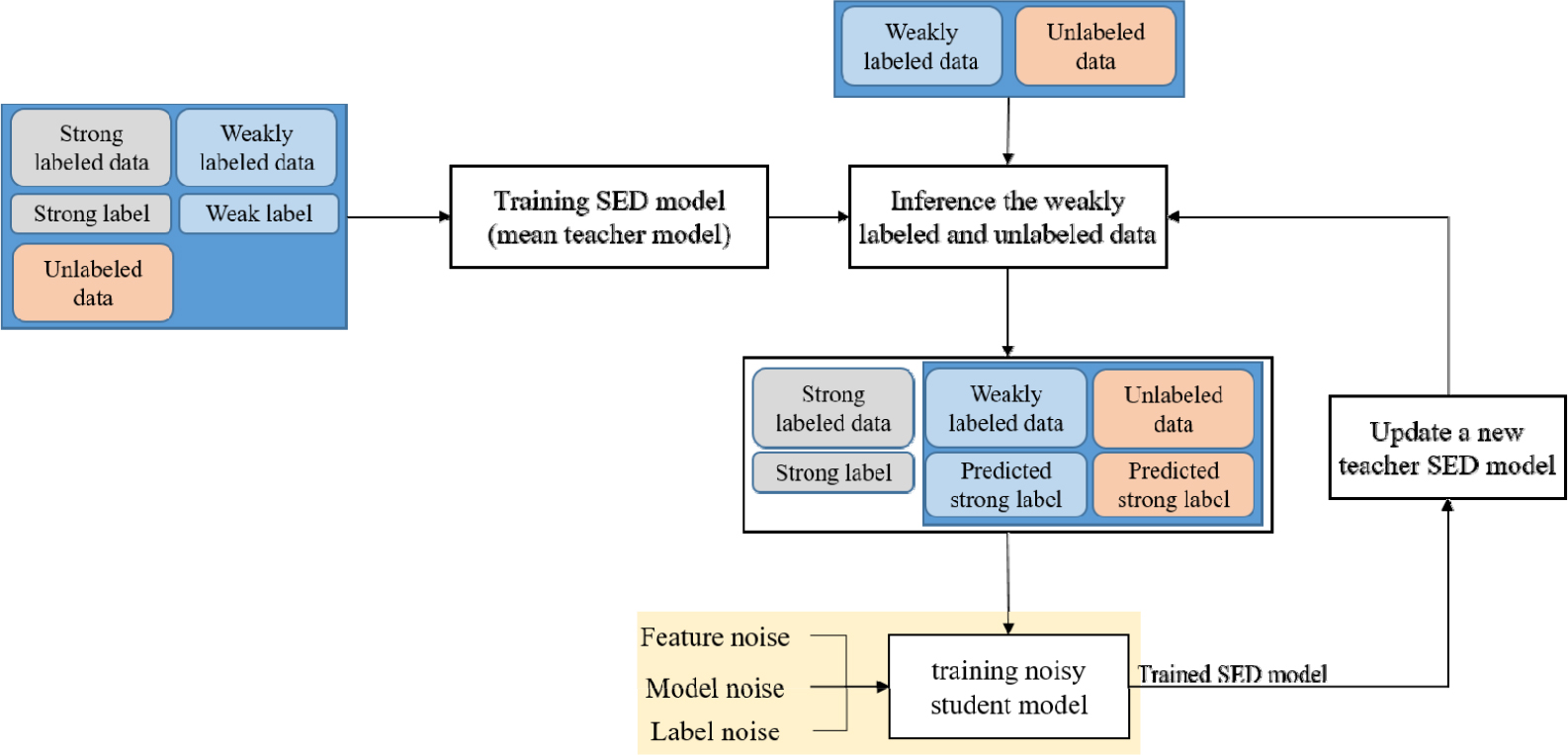
Table 1.
Network architecture of a residual convolutional neural network in the RCRNN used in the mean-teacher model.
먼저 628개 프레임의 특징을 그룹화하여 (628 × 128) 차원의 스펙트럼 이미지를 만든 다음, RCRNN의 입력 특징으로 사용한다. Table 1에서 설명한 바와 같이 RCRNN의 합성곱 블록은 1개의 stem block과 5개의 잔차 컨볼루션 블록으로 구성되며, 여기서 stem block은 첫 번째 및 두 번째 컨볼루션 블록에 대해 각각 16개 및 32개의 커널을 갖는 2개의 컨볼루션 블록으로 구성된다. 각 컨볼루션 블록에는 stride가 (1 × 1)인 (7 × 7) 합성곱 커널이 있으며 배치 정규화(Batch Normalization, BN), 게이트 선형 유닛(Gated Linear Unit, GLU) 활성화 및 (2 × 2) 평균 풀링 레이어가 연결된다. 이는 입력 시간 축을 1/2로 다운샘플링하는 역할을 수행한다. 다음으로, 각 잔차 컨볼루션 블록의 출력에 합성곱 블록 주의 모듈(Convolutional Block Attention Module, CBAM)[22]를 적용한다. 합성곱 레이어를 모두 마친 후 (128 × 157 × 1) 차원의 특징맵이 순환 블록에 적용된다. 순환 블록은 입력 특징의 시간 정보를 학습하기 위한 두 개의 양방향 게이트 순환 유닛(Bidirectional Gated Recurrent Unit, BiGRU)로 구성되며 각 GRU에 대한 활성화 함수로 정류 선형 유닛(Rectified Linear Unit, ReLU)이 사용된다. 순환 블록의 (256 × 157) 차원의 출력은 fully connected layer에 연결되고 시그모이드 함수를 적용한 후 (157 × 10) 차원으로 출력된다. 여기서 10은 감지할 음향 사건의 수를 나타낸다. (157 × 10) 차원 출력은 음향 사건 종류 및 시간 정보를 포함하는 강력한 레이블과 연관된다. 또한, 가중치 풀링 레이어가 (157 × 10) 차원 출력에 적용되어 주어진 오디오 클립에 대한 약한 레이블을 예측하는 (1 × 10) 차원 출력을 얻는다.
지금까지 훈련된 RCRNN 기반 평균 교사 모델은 약하게 레이블링된 데이터셋과 레이블이 없는 데이터셋의 강력한 레이블 예측값을 생성하는 데 사용된다. 여기서, 예측된 강력한 레이블은 임계값이 0.5로 시그모이드 출력에 임계값을 적용하여 생성한다. 이러한 예측된 레이블을 사용하여 다음 세부 절에서 설명할 잡음 학생 모델 기반 음향 사건 검지 모델을 학습에 사용된다.
3.2 잡음 학생 모델 기반 음향 사건 검지 모델
제안된 음향 사건 점지 모델의 두 번째 단계는 RCRNN 기반의 잡음 학생 모델이다. 잡음 학생 모델을 훈련하기 위하여 앞서 설명한 RCRNN 기반 평균 교사 모델에서 예측한 강력한 레이블은 약하게 레이블링된 데이터셋과 비표기 데이터셋에 활용되고, 강력하게 레이블링된 데이터셋은 대상 레이블을 그대로 사용된다.
잡음 학생 모델을 훈련하기 위해 제안된 음향 사건 검지 모델의 첫 번째 단계에서 평균 교사 모델에서 예측된 강한 레이블은 약하게 레이블링된 데이터셋 또는 비표기 데이터셋에 사용되는 반면 강한 레이블이 지정된 데이터에는 지정된 강한 레이블이 사용된다. 그 후 SpecAugment,[19] mixup,[20] 시간-주파수 이동[21]의 시간-주파수 마스킹의 특징 잡음 기술을 순차적으로 적용하여 입력 스펙트럼 이미지에 적용된다. 여기서, 시간-주파수 마스킹은 시간 및 주파수 영역의 값을 0으로 대체하여 작동하고, mixup 기법은 입력 특징을 현재 입력 특징과 다른 특징을 혼합하여 잡음 데이터를 생성한다. 시간 주파수 이동은 주파수 및 시간 축에 대해 각각 평균이 0이고 표준 편차가 각각 4와 32인 임의의 가우스 잡음에 대해 시간 및 주파수 축을 따라 입력 스펙트럼 이미지를 순환 이동으로 적용한다. 또한, 잡음 학생 모델에 대한 모델 잡음 구현을 위해 0.5 확률의 드롭아웃을 적용한다. 마지막으로, 레이블 잡음 적용으로 semi- supervised loss function[17]이 사용된다.
본 논문에서의 semi-supervised loss function은 다음 식과 같이 정의된다.
여기서 및 는 강하게 레이블링된 데이터셋, 약하게 레이블링된 데이터셋 및 비표기 데이터셋을 각각 나타낸다. Eq. (1)에서 는 RCRNN 기반의 잡음 학생 모델을 나타낸다. 또한 는 BCE 손실함수이고 는 RCRNN 기반 평균 교사 모델의 이진화된 강력한 레이블과 의 예측 출력 사이의 BCE 손실함수로 정의된다. 즉, 는 다음 식과 같이 정의된다.
여기서 는 i번째 오디오 클립에 대한 RCRNN 기반 잡음 학생 모델 의 예측값이다. Eq. (2)에서 는 이진화된 강력한 레이블 사이의 보간될 대상이며 다음 식과 같이 계산된다.
여기서 는 RCRNN 기반 평균 교사 모델 의 강력한 레이블 예측값이다. Eq. (3)에서 는 손실함수에 대한 하이퍼파라미터로, 서로 다른 앙상블 모델을 얻기 위해 설정된다. 결과적으로 잡음이 있는 입력 스펙트럼 이미지를 사용하여 잡음이 있는 학생 모델은 특징잡음, 드롭아웃 및 semi-supervised loss function으로 학습된다.
잡음 학생 모델 훈련을 마친 후 모델 매개 변수는 평균 교사 모델의 교사 모델이 된다. 그런 다음 약하게 레이블이 지정되거나 비표기 데이터에 대한 강력한 레이블이 교사모델에 의해 업데이트되며, 이는 또한 잡음 학생 모델에 새 대상 레이블로 사용된다. 결론적으로, 잡음 학생 모델을 훈련하고 레이블을 업데이트하는 이 절차를 두 번 더 반복한다.
IV. 성능 평가
4.1 실험 환경
평균 교사 모델의 학습은 DCASE 2020 챌린지 Task 4의 baseline[14]의 학습 방식을 따라 RCRNN 모델을 학습하였다. 즉, 신경망 가중치는 Xavier 초기화를 사용하여 초기화되었으며 bias 값은 모두 0으로 초기화되었다. 다음으로, 드롭아웃은 0.5의 비율로 적용되었고, ADAM 최적화 알고리즘을 활용하여 모델을 학습하였다. 또한 50 epoch 후에 최대 학습률이 0.001에 도달하는 ramp-up 방식에 따라 학습률을 설정했다. 데이터 증대를 위해 시간-주파수 이동[21]과 mixup[20]을 사용하였다. 여기서 훈련에 사용된 배치의 수는 32로 설정하여 훈련하였다.
다음으로, 잡음 학생 모델은 훈련 셋의 모든 데이터를 5-fold로 나누고 5-fold 중 4개의 fold를 학습에 사용하는 5-fold cross validation을 기반으로 3.2 절에 설명된 바와 같이 학습되었다. 다른 1개의 fold는 모델 검증에 사용되었다. 여기서, 학습률은 초기에 0.001로 설정되었으며 교차 검증에 활용된 손실함수 값을 판단하여 학습률을 감소시켰다.
4.2 평가 지표
제안된 음향 사건 검지 모델의 성능은 F1-score, Error Rate(ER)와 같은 객관적인 척도로 측정되었다. F1 점수는 다음 식과 같이 정의된다.[23]
여기서 True Positive(TP), False Positive(FP), 그리고 False Negative(FN)은 각각 검지된 정답, 검지된 오답, 그리고 검지되지 않은 정답의 수이다. F1 점수가 높을수록 음향 사건 검지에 대한 더 나은 검지 성능을 의미한다. 이벤트 단위 F1-score는 각 이벤트별로 시작과 끝 지점을 일정 범위(본 실험에서는 0.2 s으로 정의) 내로 구간을 맞춘 수를 위 F1-score에 따라 계산된다. 본 계산 방식은 DCASE 2020 챌린지 베이스라인의 측정방법과 동일하게 측정하였다.[14]
ER은 삽입(I), 삭제(D), 치환(S)의 오류 수를 측정하여 다음 식과 같이 정의하였다.[23]
여기서 은 각각 번째 오디오 클립에서 삽입, 삭제, 대체 및 실측 음향 사건의 수를 의미한다. 따라서 낮은 ER은 더 나은 음향 사건 검지 성능을 나타낸다.
4.3 결과 비교
본 세부 절에서는 제안된 잡음 학생 모델 기반의 음향 사건 검지 모델을 DCASE 2020 챌린지 Task 4에 적용하여 챌린지 baseline 및 최상위 모델과 성능을 비교하였다. Table 2는 단일 모델 기준으로 DCASE 2020 Challenge Task 4 baseline, DCASE 2020 Challenge Task 4의 최상위 모델, RCRNN 기반 평균 교사 모델 및 제안된 잡음 학생 모델 기반의 음향 사건 검지 모델의 이벤트 기반 F1-score와 ER을 비교를 보여 준다. 표에서 보는 바와 같이, RCRNN 기반 평균 교사 모델은 DCASE 챌린지의 baseline 및 상위 모델보다 더 높은 F1 점수를 달성하였다. 특히, 잡음 학생 모델 기반의 음향 사건 검지 모델은 값과 관계없이 평균 교사모델 대비 향상된 F1 점수를 얻었으며, 특히 = 0.7일 때 4.6 % 개선으로 최고의 성능을 보였다.
Table 2.
Comparison of F1-score and ERs between the top-ranked sound event detection model and the proposed RCRNN-based noisy student sound event detection model.
| Model |
Event-based F1-score | ER |
| Baseline of DCASE 2020 Task 4[14] | 34.8 | - |
| Top-ranked model of DCASE 2020 Task 4[24] | 46.0 | - |
| RCRNN-based mean-teacher model | 46.8 | 1.13 |
| RCRNN, noisy student, = 1.0 (without label noise) | 50.9 | 1.00 |
| RCRNN, noisy student, = 0.3 | 50.8 | 0.97 |
| RCRNN, noisy student, = 0.5 | 51.2 | 0.96 |
| RCRNN, noisy student, = 0.7 | 51.4 | 0.96 |
| RCRNN, noisy student, = 0.9 | 50.1 | 0.98 |
Table 3은 제안된 잡음 학생 기반 음향 사건 검지 모델의 앙상블 버전과 DCASE 2020 챌린지의 최상위 버전 모델을 비교하였다. 본 논문에서의 모델 앙상블로서 각 5-fold cross validation 시 학습된 모델의 결과를 앙상블하였다. 즉, 5개의 모델을 앙상블하여 단일 모델 대비 성능을 개선하였다. 표에서 보는 바와 같이, 제안된 모델의 앙상블 버전과 DCASE 2020의 최상위 모델을 비교하였을 때, 상위 모델 대비 F1 점수를 3.4 % 증가시켰다.
Table 3.
Comparison of F1-score and ERs between the top-ranked ensemble sound event detection model and the proposed RCRNN-based noisy student ensemble sound event detection model.
| Model |
Event-based F1-score | ER |
| Top-ranked model of DCASE 2020 Task 4 (6 model ensemble)[24] | 50.6 | - |
| RCRNN, noisy student, = 1.0 (5 model ensemble) | 52.6 | 0.92 |
| RCRNN, noisy student, = 0.3 (5 model ensemble) | 51.7 | 0.94 |
| RCRNN, noisy student, = 0.5 (5 model ensemble) | 52.7 | 0.93 |
| RCRNN, noisy student, = 0.7 (5 model ensemble) | 54.0 | 0.89 |
| RCRNN, noisy student, = 0.9 (5 model ensemble) | 51.8 | 0.93 |
마지막으로, Table 4는 제안된 잡음 학생 모델의 ablation study를 수행한 결과이다. 본 실험은 잡음 학생 모델을 구성하는 세가지 잡음을 한가지씩 제외하며 실험하여 어떤 잡음이 성능에 큰 영향을 미치는지 분석하였다. 분석한 결과, 특징잡음 유무에 따라 성능이 크게 개선됨을 확인하였으며, 모든 잡음을 추가하였을 때 음향 사건 검지 성능이 제일 개선됨을 확인할 수 있었다.
Table 4.
Ablation study for the proposed noisy student sound event detection model using an RCRNN-based teacher model with different types of noise injections.
| Model |
Feature noise |
Model noise |
Label noise |
Event-based F1-score |
Error rate |
| Baseline: CRNN-based mean-teacher model[16] (single model) | - | - | - | 34.8 | |
| RCRNN-based mean-teacher model (single model) | - | - | - | 46.8 | 1.13 |
|
Noisy student sound event detection model (RCRNN model, single model) | - | √ | √ | 46.8 | 1.05 |
| √ | - | √ | 49.8 | 0.99 | |
| √ | √ | - | 50.9 | 1.00 | |
| √ | √ | √ | 51.4 | 0.96 |
V. 결 론
본 논문에서는 잡음 학생 모델 기반의 음향 사건 검지 모델을 제안하였다. 제안된 음향 사건 검지 모델은 약하게 레이블링된 데이터와 비표기 데이터와 같은 훈련 데이터셋을 활용한 자가 학습을 기반으로 하였다. 특히, RCRNN 기반 평균 교사 모델을 사용하여 약하게 레이블링된 데이터셋과 비표기 데이터셋에서 각 오디오 클립의 대상 레이블을 예측하였다. 잡음 학생 모델 기반의 자가 학습을 구현을 위해 잡음 학생 모델은 데이터 증대 기반의 특징 잡음, 드롭아웃 기반 모델 잡음, semi-supervised loss function 기반의 레이블 잡음을 모델에 주입하였다. 특히, semi- supervised loss function의 cross-validation과 다른 하이퍼파라미터 값에 따라 잡음 학생 모델을 학습시켰고, 다섯가지의 서로 다른 모델을 앙상블 모델로 하여 성능을 개선하였다. 제안된 음향 사건 검지 모델의 성능은 DCASE 2020 챌린지 Task 4의 validation set에서 평가되었다. 결과적으로, DCASE 챌린지 Task 4의 baseline 모델과 최상위 모델과 성능을 비교하였을 때 높은 성능을 달성하였다. 특히 최상위 모델 대비 단일모델에서 4.6 %, 앙상블 모델에서 3.4 % F1 점수 향상을 보였다.
