

I. 서 론
II. 사용자 정의 기동어 인식
III. 음성 데이터베이스
IV. DNN-HMM 하이브리드 기반 음성 인식 모델
V. HMM score 기반 사용자 정의 기동어 인식
VI. 실험 및 결과
6.1 Threshold 적용 전 시스템 성능 평가
6.2 Threshold 적용 후 시스템 성능 평가
VII. 결 론
I. 서 론
음성 인식기를 대기모드에서 동작 모드로 전환하기 위해 발화하는 짧은 단어를 기동어(Wake Up Word, WUW)[1], [2]라고 한다. 최근 음성 인식 분야에 심층 신경망(Deep Neural Network, DNN) 기법이 도입 되면서 음성 인식기의 성능이 대폭 향상되었지만,[3] 그에 따라 요구되는 연산량이 크게 증가하였다. 연산량이 증가할수록 음성 인식을 담당하는 서버에 부하가 늘어나는데, 이를 줄이기 위해 현재 상용화된 음성 인식 시스템들은 음성 인식 단말기에서 기동어가 인식 될 경우에만 음성 인식기가 동작하도록 음성 인식 시스템을 구현하고 있다. 따라서 기동어 인식 시스템은 음성 인식 시스템 전체에서 사용자와 가장 가까운 위치에 존재하며, 사용자가 느끼는 음성 인식기의 체감 성능은 기동어 인식기의 성능과 밀접한 관련이 있다. 본 논문에서는 사용자와 음성 인식 시스템과의 보다 자연스러운 대화를 위한 방법으로 사용자 정의 기동어 인식 시스템을 제안한다. 사용자 정의 기동어란 기동어 인식기를 제작하는 과정에서 정해진 기동어가 아닌 실제 사용자가 원하는 단어로 지정한 기동어를 의미한다.
본 논문에서는 사용자 정의 기동어를 인식하기 위해 Hidden Markov Model(HMM) 기반의 음향모델을 제작하고 HMM score 기반의 사용자 정의 기동어 인식 시스템을 제작하였다. 본 논문에서 제작한 HMM 기반의 음향모델은 총 3종류로, 기존 음성 인식에서 주로 사용하던 Gaussian Mixture Mode(GMM)-HMM 모델과 입력 특징인 Mel Frequency Cepstral Coefficient (MFCC)[4] 도메인에서 선형 판별 분석법(Linear Discriminant Analysis, LDA)[5]을 적용한 LDA-GMM-HMM 모델, GMM 모델을 DNN으로 대체한 LDA-DNN-HMM 모델을 사용하였다. 실험에서는 3종류의 음향 모델을 사용한 시스템들의 기동어 인식성능 및 비기동어 거절 성능을 비교 평가 하였다.
본 연구에서 제작한 사용자 정의 기동어 인식 시스템은 사용자가 직접 사용하길 원하는 단어로 기동어를 선정할 수 있다는 장점이 있어 사용자가 친밀감을 느낄 수 있어 기존의 기동어 인식기보다 자연스러운 대화를 가능하게 할 수 있을 것으로 기대된다.
II. 사용자 정의 기동어 인식
사용자 정의 기동어 인식기는 일반적인 기동어 인식기와 달리 사용자가 직접 기동어로 사용할 단어를 지정하여 사용할 수 있다는 특징이 있다. 이러한 특징 때문에 사용자가 기존의 기동어 인식 시스템보다 친밀감을 느낄 수 있고 보다 자연스러운 대화를 할 수 있다는 장점이 있다. 하지만, 기동어 인식 모델을 훈련하는 과정에서는 어떤 단어가 기동어로 선택되어 사용될지 전혀 알 수 없어서 인식 과정에서 필요한 단어 사전을 생성하기 어렵다는 문제가 발생한다. 본 논문에서는 이러한 문제를 해결하기 위해 사용자가 기동어를 등록하는 과정에서 단어 사전을 생성하는 방법을 도입하였다. Fig. 1은 본 논문에서 제작한 시스템의 등록과정을 나타낸 그림이다. 등록과정에서 사용자가 기동어를 발화하면 음소 단위로 음성을 인식하는 음향 모델을 통해 인식 결과를 출력하고, 출력된 음소 인식 결과를 하나의 단어를 구성하는 음소열로 간주하여 기동어 사전을 생성하였다.

기동어 인식 시스템은 기동어를 인식하는 능력 뿐만 아니라 비기동어를 거절할 수 있는 능력 또한 요구된다. 일반적인 기동어 인식 시스템과 달리 기동어의 음소열이 고정되어 있지 않아 비기동어를 구분할 기준을 생성하기 어렵다. 본 논문에서는 이러한 문제를 해결하기 위해 기동어와 비기동어를 구분하는 기준이 되는 anti word를 선정하고 anti word 사전을 생성하는 방법을 도입하였다. Anti word는 등록 과정에서 기동어 사전이 생성된 직후에 선정이 되며, 입력된 신호로 훈련에 사용한 단어 목록들에 대한 HMM score를 계산하고 계산된 HMM score가 낮은 순으로 사용할 단어 수만큼 선택하여 anti word로 선정하였다. 본 논문에서는 PBW452 데이터베이스에 포함된 452개의 단어 목록에서 200개의 단어를 선정하여 anti word 사전을 생성하였다.
III. 음성 데이터베이스
사용자 정의 기동어 인식 시스템에서는 훈련 환경에서 사용자가 사용할 기동어가 어떤 단어인지 알지 못하는 상황으로 가정한다. 따라서, 사용자 정의 기동어 인식 시스템을 위한 음향 모델을 훈련할 때에는 기동어가 포함되지 않은 일반적인 단어들로 구성된 음성데이터만을 사용해야한다. 본 논문에서는 한국어 음성 인식 분야에서 많은 연구자들이 사용하고 있는 PBW452 데이터베이스를 사용하여 사용자 정의 기동어 인식 모델을 훈련하였다.
본 논문에서 제작한 사용자 정의 기동어 인식 시스템의 성능 평가를 위해 기동어 음성 데이터를 수집하였다. 10종류의 서로 다른 기동어를 여러 화자가 약 10회 발화한 기동어 데이터 베이스를 수집하였으며, 화자별 5개의 음성 파일을 등록용으로 사용하고 나머지 음성 파일들을 성능 평가용으로 사용하였다. 실험에서는 실제 사용 환경을 조용한 사무실 환경에서 원거리에서 발화하는 것으로 가정하였다. 이러한 사용 환경을 반영하기 위해 Room Impulse Response(RIR) 필터[1]를 적용하여 원거리에서 발화한 것처럼 변형하여 사용하였으며, 사무실 환경에서 발생가능한 약간의 소음을 재현하기 위하여 Youtube에서 수집한 잡음들을 20 dB Signal to Noise Ratio(SNR) 수준으로 합성하여 평가에 사용하였다.
IV. DNN-HMM 하이브리드 기반 음성 인식 모델
기존의 전통적인 GMM-HMM 시스템에서 GMM은 HMM에서 사용할 사후 확률을 계산하는 것을 목적으로 사용되어진다. 시간 t에서의 관측 상태가 일 때, GMM을 이용하여 계산된 은닉 상태 s에 대한 사후 확률 는 다음과 같이 표현된다.
| $$P\lbrack O_t\vert s\rbrack=\sum_m^Mw_{sm}N\lbrack O_t\vert\mu_{sm},\;\sigma_{sm}\rbrack.$$ | (1) |
이때 은 각각 GMM에 사용된 가우시안 함수의 개수, 가우시안 함수의 가중치, 정규 분포 함수, 평균 그리고 공분산 행렬을 의미한다.
DNN-HMM 하이브리드 시스템은 기존의 전통적인 GMM-HMM 기반의 음향모델에서 GMM 모델을 DNN으로 대체한 시스템이다. 기존의 GMM-HMM 모델과 마찬가지로 DNN-HMM 모델의 DNN 모델은 HMM에서 사용되어질 관측 순열에 대한 사후 확률을 계산하는 것을 목적으로 사용되어지며, DNN 모델을 이용하여 사후 확률을 계산하기 위해 출력층의 활성화 함수로는 softmax 함수를 사용한다.[3] 사후 확률 을 대체할 DNN의 출력값 는 다음과 같이 표현된다.
| $$P\lbrack O_t\vert s\rbrack\approx y_s(O_t)=\frac{\exp\lbrack a_s(O_t)\rbrack}{{\displaystyle\sum_{s'}}\exp\lbrack a_{s'}(O_t)\rbrack},$$ | (2) |
여기서 는 DNN 출력층에서 활성화 함수를 적용하기 전의 값을 의미한다.
V. HMM score 기반 사용자 정의 기동어 인식
본 논문에서는 HMM score를 활용하여 기동어 인식기를 제작하였다. HMM score는 입력 신호가 지정된 단어일 확률에 로그를 취한 값으로, 단어 에 대한 입력 신호 x의 HMM score는 다음과 같이 표현된다.
| $$score(x\vert x_i)=\log\lbrack P(x\vert x_i)\rbrack.$$ | (3) |
HMM score는 GMM 혹은 DNN을 사용하여 입력 신호에서 추출한 MFCC 특징으로부터 사후 확률을 계산한 뒤에, 은닉 마르코프 모델과 Viterbi 알고리즘을 사용하여 구할 수 있다.
입력 음성 신호가 기동어인지 비기동어인지 구분하기 위해서는 비교할 만한 기준이 필요한데, 사용자 정의 기동어 인식 시스템에서는 어떤 단어가 기동어로 사용될지 모르기 때문에 이러한 기준을 정하는데 어려움이 있다. 본 논문에서는 이를 해결하기 위해 등록용으로 발화한 음성과 PBW452 데이터 베이스에 포함된 단어 목록들과의 HMM score를 계산한 뒤 HMM score가 낮은 순으로 단어들을 선정하여 비교할 기준으로 삼았다. 이렇게 선정한 단어를 anti word라고 지칭한다.
Fig. 2는 본 논문에서 제작한 사용자 정의 기동어 인식 시스템의 인식단계에서의 전체적인 동작과정을 나타내고 있다. 음성 인식 단말기에 음성이 입력되면 음성 신호로부터 MFCC 특징을 추출한 후에 LDA 선형 변환을 수행한다. 이는 음성 인식 분야에서 고전적으로 성능 향상을 위해 적용되어왔던 방법으로, 클래스 구분이 있는 데이터들을 각 클래스들의 특징이 보다 잘 부각되도록 변환할 수 있다는 LDA의 장점을 이용하여 MFCC 특징의 음소별 구분을 명확하게 하여 인식 성능을 향상시키기 위해 MFCC 도메인에서 LDA를 적용하였다. 그 후에 DNN 모델을 사용하여 사후 확률을 계산하고, HMM 모델을 통해 등록된 기동어에 대한 HMM score들과 미리 선정된 anti-word 단어 목록에 대한 HMM score들을 각각 계산한다. 그 후, 기동어에 대한 HMM score들의 최댓값과 anti-word에 대한 HMM score들의 최댓값을 비교하여 기동어에 대한 HMM score가 비기동어에 대한 HMM score보다 더 높으면서 사전에 정해진 threshold 값 보다 높을 때에만 기동어로 판단하도록 시스템을 제작하였다.

VI. 실험 및 결과
본 논문에서는 은닉 마르코프 모델 기반의 음성 인식기를 사용하여 사용자 정의 기동어 인식 시스템을 제작하였다. 실험에서 사용한 은닉 마르코프 모델은 공통적으로 3개의 은닉 상태를 가지도록 하였으며, 묵음을 포함한 47개 음소로 음향 모델을 구성하였다.
실험에서는 3종류의 모델을 제작하여 각 모델의 기동어 인식 및 비기동어 거절 성능을 평가하였다. 첫 번째 모델로 MFCC 특징을 사용한 기존의 전통적인 GMM-HMM 기반의 음향모델을 사용하였다. 첫 번째 모델의 성능 향상을 위해 MFCC 도메인에서 LDA를 적용하여 변환 행렬을 제작한 후, MFCC 특징을 변환하였다. 변환된 특징들을 사용하여 GMM-HMM 모델을 새로 생성하였고, 이렇게 생성된 모델을 LDA- GMM-HMM 모델이라 하며 이를 두 번째 실험에서 사용하였다. 마지막으로 DNN-HMM 기반의 음향모델을 제작하여 세 번째 모델로 사용하였다. DNN 모델을 훈련하기 위해 LDA-GMM-HMM 모델을 활용하여 사후확률을 계산하고, 계산된 사후 확률을 DNN의 라벨로 삼아 훈련을 진행하였다. DNN의 입력으로는 LDA가 적용된 MFCC 특징을 사용하였으며, DNN은 3개의 은닉 층으로 구성하고 각 은닉층은 100개의 뉴런을 가지도록 구성하였다. 또한 각 은닉층에서 사용한 활성화 함수로는 Rectified Linear Unit(ReLU) 함수를 사용하고 출력층에서의 활성화 함수로는 softmax 함수를 사용하여 사후확률을 대체할 수 있도록 제작하였다. 이렇게 제작된 모델을 LDA-DNN- HMM 모델이라고 한다.
실험에서는 각 모델의 성능을 비교 평가하기 위해 기동어와 비기동어 오인식율을 측정하였다. 또한, 비기동어 거절 성능을 보다 직관적으로 비교하기 위해 시간당 비기동어 오인식 횟수를 계산하여 비교 평가하였다.
6.1 Threshold 적용 전 시스템 성능 평가
입력된 음성 신호가 기동어인지 비기동어인지를 구분하기 위한 기준인 anti word를 음향 모델을 훈련하는데 사용했던 PBW452 데이터 베이스에 포함된 단어 목록에서 선정하였으며, 등록된 단어 목록을 기준으로 HMM score가 가장 낮은 단어들 중 200개를 선택하여 anti word로 사용하였다. 최종적으로는 등록된 기동어 목록들의 HMM score들의 최댓값과 anti word 목록들의 HMM score들의 최댓값을 비교하여 기동어의 최댓값이 높으면 기동어로, 그렇지 않으면 비기동어로 판단하도록 시스템을 구성하였다.
Table 1은 3가지 모델의 사용자 정의 기동어 인식 성능 평가 결과를 나타낸다. GMM-HMM 모델의 경우, 기동어 인식 실패율이 2.61 %, 비기동어 거절 실패율이 5.13 %를 보였다. GMM-HMM 모델에 LDA를 적용한 LDA-GMM-HMM 모델의 경우, 기동어 인식 실패율이 2.24 %, 비기동어 거절 실패율이 3.04 %로 나타났으며, 마지막으로 LDA-DNN-HMM 모델의 경우 기동어 인식 실패율은 2.27 %, 비기동어 거절 실패율은 5.09 %를 나타냈다. 이러한 결과는 기존의 전통적인 음향 모델 제작 방식인 GMM-HMM에 비해 LDA- GMM- HMM 모델과 LDA-DNN-HMM 모델의 성능이 상대적으로 우수함을 의미한다. 하지만 DNN을 적용한 LDA-DNN-HMM 모델의 성능이 LDA-GMM-HMM보다 좋지 못한 결과를 보였다.
Table 1. User defined spoken key word recognition results (error rate, %).
| WUW | Non-WUW | FA number / 1 h | |
| GMM-HMM | 2.61 | 5.13 | 184.68 |
| LDA-GMM-HMM | 2.24 | 3.04 | 109.44 |
| LDA-DNN-HMM | 2.27 | 5.09 | 183.24 |
6.2 Threshold 적용 후 시스템 성능 평가
비기동어 거절 성능이 기동어 인식 성능보다 사용자의 체감 성능에 큰 영향을 미치는 경향이 있다. 따라서 기동어 인식 성능이 감소되더라도 비기동어 거절 성능을 향상 시킬 필요가 있다. 이를 위해 본 논문에서는 threshold를 적용하여 기동어 인식 성능을 낮추는 대신 비기동어 인식 성능을 향상시켰다. 임의의 값 p(0 < p < 1)를 threshold로 설정하여 p와 anti word의 HMM score를 곱한 값 보다 기동어의 HMM score가 높을 때에만 인식이 되도록 시스템을 변경하였다.
Table 2는 3종류의 사용자 정의 기동어 인식 모델에 threshold를 적용 했을 때의 시스템 성능 평가 결과이다. 비교를 위하여 각 모델의 기동어 인식 오류율이 약 10 % 정도의 수준이 되는 threshold에서의 성능을 비교 평가 하였다. GMM-HMM 모델의 경우 기동어 오인식율은 10.08 %, 비기동어 거절 실패율은 0.053 %의 성능을 보였다. LDA를 적용한 모델인 LDA-GMM- HMM 모델은 기동어 인식 실패율 10.45 % 수준에서 0.028 %의 비기동어 거절 실패율을 보이며 기존의 GMM-HMM 모델보다 인식 성능이 우수함을 확인하였다. 마지막으로 LDA-DNN-HMM 모델의 경우 기동어 인식 실패율 9.84 % 수준에서 비기동어 거절 실패율이 0.0058 % 정도로 높은 거절 성능을 보였다. 이는 시간당 비기동어 오류 횟수가 약 0.21회로 다른 모델들에 비해 월등히 높은 성능을 나타내며, threshold 적용전의 시스템에 비해 시간당 오인식 횟수가 183회 이상 감소함을 확인하였다. 이러한 결과는 threshold를 적용하여 기동어 인식 성능을 포기하는 대신 비기동어 거절 성능을 향상시킬 수 있음을 입증하며, DNN 모델을 사용한 경우가 그렇지 않은 경우 보다 threshold 적용 시 비기동어 거절 성능 향상에 따른 기동어 인식 성능 하락이 상대적으로 적음을 입증한다. 이는 LDA-DNN-HMM 모델이 다른 모델들 보다 성능이 우수함을 의미한다.
Table 2. User defined spoken key word recognition results after applying threshold method (error rate, %).
| WUW | Non-WUW | FA number / 1 h | |
| GMM-HMM | 10.08 | 0.053 | 1.91 |
| LDA-GMM-HMM | 10.45 | 0.028 | 1.01 |
| LDA-DNN-HMM | 9.84 | 0.0058 | 0.21 |
Fig. 3은 보다 명확한 성능 비교 평가를 위해 threshold 변화에 따른 기동어 오인식율 및 비기동어 오인식율을 시각화한 그림이다. Threshold 값을 1에서부터 감소시켜가며 기동어 오류율이 0.25 % 증가할 때마다 성능을 기록하였으며, 보다 직관적인 이해를 위해 비기동어 오류율에 자연로그를 취한 값을 기록하여 시각화 하였다. Fig. 3에서 비기동어 오인식율의 감소폭이 LDA-DNN-HMM 모델의 경우가 가장 큰 것을 알 수 있으며, 이는 본 논문에서 제작한 3종류의 모델 중에서 LDA-DNN-HMM 모델의 성능이 가장 우수함을 의미한다.
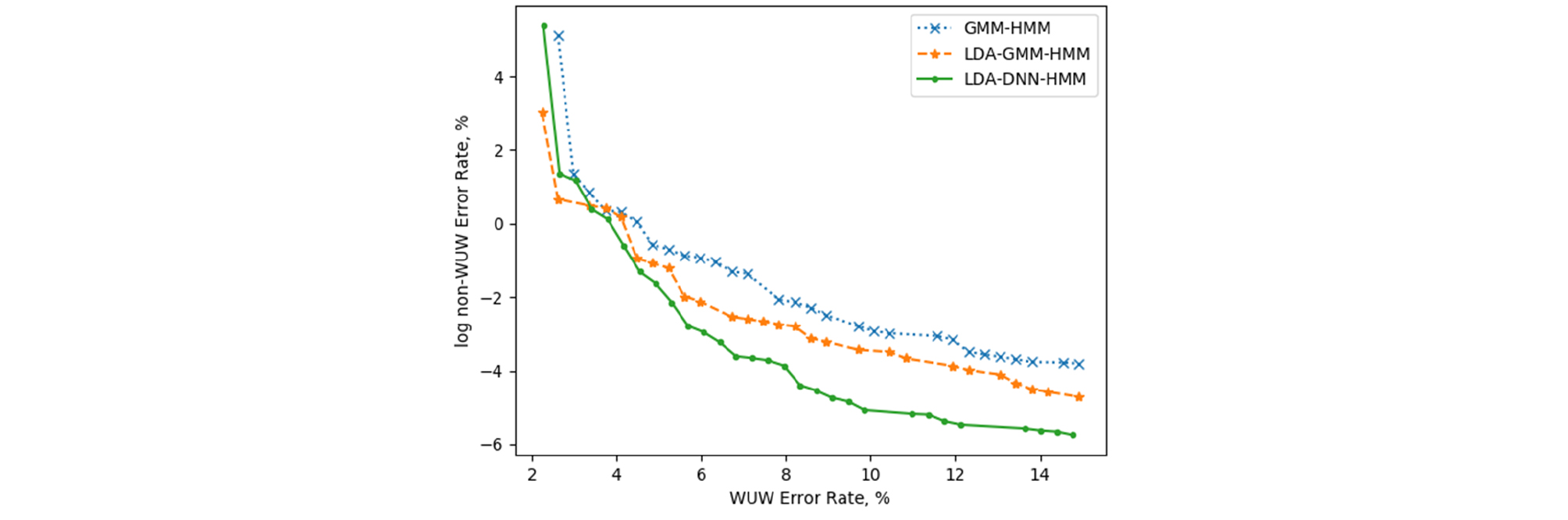
VII. 결 론
본 논문에서는 GMM-HMM, LDA-GMM-HMM 그리고 LDA-DNN-HMM모델을 이용하여 사용자 정의 기동어 인식 시스템을 제작하고 3가지 모델의 기동어 인식 성능 및 비기동어 거절 성능을 비교 평가하였다. 음소 인식기를 사용하여 등록시 발화한 음성으로부터 단어 사전을 생성하고, 인식 과정에서 생성된 단어 목록을 활용하여 사용자 정의 기동어를 인식하는 방법을 적용하였다. 또한, 기동어 인식기의 체감 성능을 향상시키고자 각 모델에 threshold를 적용하여 기동어 인식 실패율을 약 10 % 수준으로 감소 시킨 후에 비기동어의 거절 실패율을 비교 평가하였다. Threshold 적용시에 LDA-DNN-HMM 기반의 시스템의 경우 기동어 인식 실패율 9.84 % 수준에서 비기동어 거절 실패율이 0.0058 %의 인식 성능을 나타내어 LDA-GMM-HMM 시스템보다 약 4.82배 향상된 비기동어 거절 성능을 확인하였다. 이러한 결과는 본 논문에서 제작한 LDA-DNN-HMM 모델이 사용자 정의 기동어 인식 시스템을 구축하는데 효과적임을 입증한다.
