
-
Research Article
-
A study on the acoustic performance of an absorptive silencer applying the optimal arrangement of absorbing materials
흡음재 최적 배치를 적용한 흡음형 소음기의 음향성능 연구
-
Dongheon Kang, Haesang Yang, Woojae Seong
강동헌, 양해상, 성우제
- In this paper, the acoustic performance of an absorptive silencer was enhanced by optimizing an arrangement of multi-layered absorbing materials. The acoustic …
본 논문에서는 흡음형 소음기의 음향성능을 향상시키기 위해 다층 흡음재 배치 순서를 최적화하였다. 소음기의 음향성능은 투과손실로 판단하였으며, 투과손실을 계산하기 위해 유한요소법 기반 수치해석 …
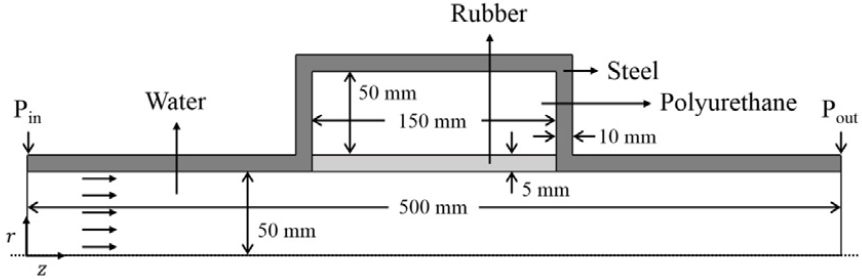
- In this paper, the acoustic performance of an absorptive silencer was enhanced by optimizing an arrangement of multi-layered absorbing materials. The acoustic performance of the silencer was evaluated through transmission loss, and finite element method-based numerical analysis program was employed to calculate the transmission loss. Polyurethane, a porous elastic material frequently used in absorptive silencers, was employed as the absorbing material. The Biot-Allard model was applied, assuming that air is filled inside the polyurethane. By setting the frequency range of interest up to the 2 kHz and the acoustic performance affecting properties of the absorbing materials were investigated when it was composed as a single layer. And the acoustic performance of the silencers with the single and multi-layered absorbing materials was compared with each other based on polyurethane material properties. Subsequently, the arrangement of the absorbing materials was optimized by applying the Nelder-Mead method. The results demonstrated that the average transmission loss improved compared to the single-layered absorptive silencer.
- COLLAPSE
본 논문에서는 흡음형 소음기의 음향성능을 향상시키기 위해 다층 흡음재 배치 순서를 최적화하였다. 소음기의 음향성능은 투과손실로 판단하였으며, 투과손실을 계산하기 위해 유한요소법 기반 수치해석 프로그램을 사용하였다. 흡음재는 흡음형 소음기에서 많이 사용되는 다공탄성 물질인 폴리우레탄을 사용하였으며, 내부에 공기가 흐르는 상황을 가정하여 Biot-Allard 모델을 적용하였다. 2 kHz 대역까지 관심주파수 영역을 설정하여 흡음재가 단층으로 구성되어 있을 때 음향성능에 영향을 주는 물성치를 확인하였으며, 폴리우레탄 물성치를 바탕으로 단층 및 다층 흡음재를 가진 소음기의 음향성능을 서로 비교하였다. 이후 Nelder-Mead 방법을 적용하여 소음기 내 다층 흡음재의 배치 순서를 최적화하였으며, 단층 흡음형 소음기에 비해 평균 투과손실이 증가하는 것을 확인하였다.
-
A study on the acoustic performance of an absorptive silencer applying the optimal arrangement of absorbing materials
-
Research Article
-
Analysis of stick-slip characteristics of materials used for mechanical and electronic components
기계전자 부품재료의 스틱슬립 특성 평가방법에 관한 연구
-
Du-Seop Kim and Won-Jin Kim
김두섭, 김원진
- In this study, we analyzed the stick slip characteristics through friction experiments on materials used in mechanical and electronic products, and propose …
본 연구에서는 기계전자 제품에 사용되는 소재의 마찰실험을 통해 스틱슬립 특성을 분석하고 냉장고 내부에서 발생하는 이상소음을 저감하는 개선안을 제안하였다. 소재의 스틱슬립 현상을 분석하기 …
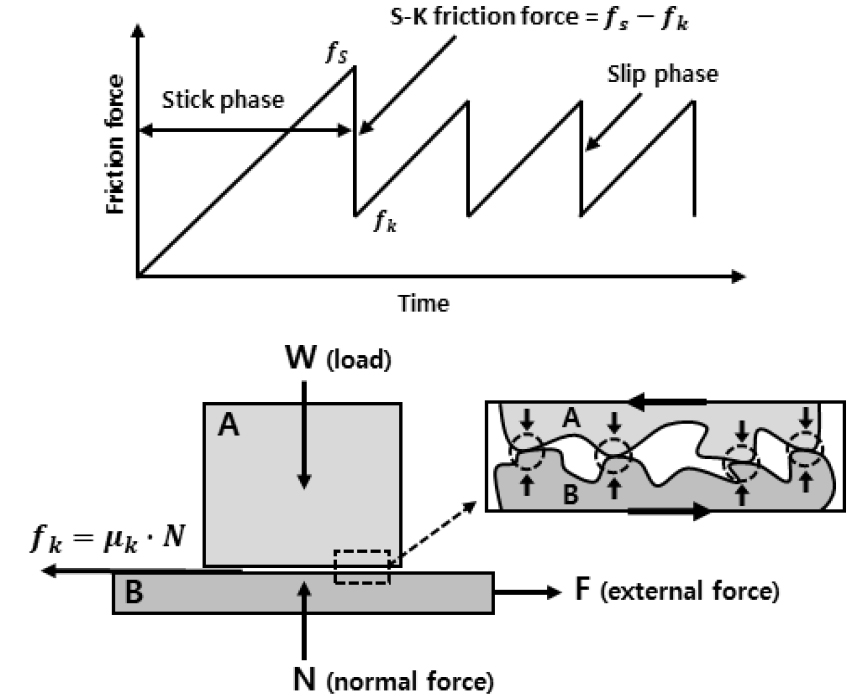
- In this study, we analyzed the stick slip characteristics through friction experiments on materials used in mechanical and electronic products, and propose improvements to reduce abnormal noise generated inside refrigerators. To analyze the stick slip phenomenon of the materials, we fabricated a friction testing device and conducted friction experiments. Additionally, we measured the vibration and noise levels of internal components to analyze the occurrence and location of abnormal noise inside the refrigerator. By comparing the results of the refrigerator’s phenomenon analysis and friction experiment, we confirm that the abnormal noise occurring inside the refrigerator is caused by the stick slip phenomenon of internal components. Finally, to propose improvements for abnormal noise reduction, we performed friction experiments using the Taguchi method and validated the performance of the proposed improvements by applying them to refrigerators.
- COLLAPSE
본 연구에서는 기계전자 제품에 사용되는 소재의 마찰실험을 통해 스틱슬립 특성을 분석하고 냉장고 내부에서 발생하는 이상소음을 저감하는 개선안을 제안하였다. 소재의 스틱슬립 현상을 분석하기 위해 마찰실험장치를 제작하고 마찰실험을 수행하였다. 또한 냉장고 내부에서 발생하는 이상소음의 현상과 위치를 분석하기 위해 내부부품의 진동과 소음 레벨을 측정하였다. 그리고 냉장고 현상분석 결과와 마찰실험 결과를 비교하여 냉장고 내부에서 발생하는 이상소음은 내부부품의 스틱슬립 현상에 의한 것임을 확인하였다. 마지막으로 이상소음을 저감하는 개선안을 제안하기 위해 다구찌 기법을 이용한 마찰실험을 수행하였다. 그리고 개선안을 냉장고에 적용하여 성능을 검증하였다.
-
Analysis of stick-slip characteristics of materials used for mechanical and electronic components
-
Research Article

-
A study on the noise reduction method of transformer using harmonic response analysis
조화응답해석을 이용한 변압기의 소음저감 방법에 관한 연구
-
Chang-Seop Kim and Won-Jin Kim
김창섭, 김원진
- This study proposes a method to predict noise reduction based on noise-reduction measures, using harmonic response analysis, for transformer design. The dynamic …
본 연구에서는 변압기 설계에 활용하기 위해 조화응답해석을 이용하여 소음저감 대책에 따른 소음 저감 예측 방법을 제안한다. 변압기 부품들의 재질을 간단한 형상의 시편으로 …
- This study proposes a method to predict noise reduction based on noise-reduction measures, using harmonic response analysis, for transformer design. The dynamic elastic coefficients of the components comprising the actual transformer were determined by manufacturing the materials of the transformer components into simple-shaped specimens, followed by a comparison of the modes between the experiments and the analyses. A finite element model of the transformer was implemented, and harmonic response analysis was performed by deriving the exciting force of the transformer. Subsequently, the theoretical sound power level of the transformer was derived from the results of the harmonic response analysis. Finally, noise reduction measures were established, and the noise reduction amounts were compared between the experiments and the analyses, before and after applying the measures. Through the comparison and analyses of the noise reduction measures, it was confirmed that the trends in the experiments and analyses matched.
- COLLAPSE
본 연구에서는 변압기 설계에 활용하기 위해 조화응답해석을 이용하여 소음저감 대책에 따른 소음 저감 예측 방법을 제안한다. 변압기 부품들의 재질을 간단한 형상의 시편으로 제작하고, 실험과 해석의 모드 비교분석을 통해 실제 변압기를 구성하는 부품들의 동적 탄성계수를 규명하였다. 변압기의 유한요소모델을 구현하고 변압기의 가진력을 도출하여 조화응답해석을 수행하였다. 그리고 조화응답해석 결과에서 변압기의 음향파워레벨(Sound power level)을 이론적으로 도출하였다. 마지막으로 소음저감 대책을 수립하고, 적용 전·후에 따른 실험과 해석의 소음 저감량을 비교하였다. 대책별 소음저감 비교분석을 통해 실험과 해석의 경향이 일치하는 것을 확인하였다.
-
A study on the noise reduction method of transformer using harmonic response analysis
-
Research Article

-
Estimation of underwater acoustic uncertainty based on the ocean experimental data measured in the East Sea and its application to predict sonar detection probability
동해 해역에서 측정된 해상실험 데이터 기반의 수중음향 불확정성 추정 및 소나 탐지확률 예측
-
Dae Hyeok Lee, Wonjun Yang, Ji Seop Kim, Hoseok Sul, Jee Woong Choi, and Su-Uk Son
이대혁, 양원준, 김지섭, 설호석, 최지웅, 손수욱
- When calculating sonar detection probability, underwater acoustic uncertainty is assumed to be normal distributed with a standard deviation of 8 dB to …
소나 탐지확률을 계산하는 경우, 수중음향 불확정성은 표준편차가 8 dB ~ 9 dB인 정규분포를 따르는 것으로 고려되고 있다. 하지만, 소나 탐지성능은 실험해역, 해양환경 …
- When calculating sonar detection probability, underwater acoustic uncertainty is assumed to be normal distributed with a standard deviation of 8 dB to 9 dB. However, due to the variability in experimental areas and ocean environmental conditions, predicting detection performance requires accounting for underwater acoustic uncertainty based on ocean experimental data. In this study, underwater acoustic uncertainty was determined using measured mid-frequency (2.3 kHz, 3 kHz) noise level and transmission loss data collected in the shallow water of the East Sea. After calculating the predictable probability of detection reflecting underwater acoustic uncertainty based on ocean experimental data, we compared it with the conventional detection probability results, as well as the predictable probability of detection results considering the uncertainty of the Rayleigh distribution and a negatively skewed distribution. As a result, we confirmed that differences in the detection area occur depending on each underwater acoustic uncertainty.
- COLLAPSE
소나 탐지확률을 계산하는 경우, 수중음향 불확정성은 표준편차가 8 dB ~ 9 dB인 정규분포를 따르는 것으로 고려되고 있다. 하지만, 소나 탐지성능은 실험해역, 해양환경 변동성에 따라 크게 변화하기 때문에 해상실험 데이터 기반의 수중음향 불확정성을 반영한 탐지성능 예측이 필요하다. 본 논문에서는 동해 천해환경에서 측정된 중주파수(2.3 kHz, 3 kHz) 소음준위와 전달손실 자료 기반의 수중음향 불확정성이 산출되었다. 해상실험 데이터 기반의 수중음향 불확정성을 반영한 예상탐지확률을 산출한 후, 이를 기존의 탐지확률 결과, 레일리 분포의 불확정성과 음으로 치우친 분포의 불확정성을 반영한 예상탐지확률 결과와 비교하였다. 결과적으로 각각의 수중음향 불확정성에 따라 탐지영역의 차이가 발생하는 것을 확인할 수 있었다.
-
Estimation of underwater acoustic uncertainty based on the ocean experimental data measured in the East Sea and its application to predict sonar detection probability
-
Research Article

-
A sea trial method of hull-mounted sonar using machine learning and numerical experiments
기계학습 및 수치실험을 활용한 선체고정형소나 해상 시운전 평가 방안
-
Ho-seong Chang, Chang-hyun Youn, Hyung-in Ra, Kyung-won Lee, Dea-hwan Kim, and Ki-man Kim
장호성, 윤창현, 라형인, 이경원, 김대환, 김기만
- In this paper, efficient and reliable methodologies for conducting sea trials to evaluate the performance of hull-mounted sonar systems is discussed. These …
본 논문에서는 선체고정형소나의 해상 시운전을 효율적이면서 신뢰성 있게 수행하기 위한 방안을 제시하였다. 현재 함 건조 과정에서 선체고정형소나의 해상 시운전 절차에는 해저 지형, …
- In this paper, efficient and reliable methodologies for conducting sea trials to evaluate the performance of hull-mounted sonar systems is discussed. These systems undergo performance verification during ship construction via sea trials. However, the evaluation procedures often lack detailed consideration of variabilities in detection performance due to seabed topography, seasonal factors. To resolve this issue, temperature and salinity structure data were collected from 1967 to 2022 using ARGO floats and ocean observers data. The paper proposes an efficient and reliable sea trial method incorporating Bellhop modeling. Furthermore, a machine learning model applying a Physics-Informed Neural Networks was developed using the acquired data. This model predicts the sound speed profile at specific points within the sea trial area, reflecting seasonal elements of performance evaluation. In this study, we predicted the seasonal variations in sound speed structure during sea trial operations at a specific location within the trial area. We then proposed a strategy to account for the variability in detection performance caused by seasonal factors, using results from Bellhop modeling.
- COLLAPSE
본 논문에서는 선체고정형소나의 해상 시운전을 효율적이면서 신뢰성 있게 수행하기 위한 방안을 제시하였다. 현재 함 건조 과정에서 선체고정형소나의 해상 시운전 절차에는 해저 지형, 계절적 요인 등에 따른 탐지 성능의 변동성이 세밀하게 반영되어 있지 않다. 문제 해결을 위해 1967년부터 2022년까지의 기간 동안 Array for Real time Geostrophic Oceanography(ARGO) 플로트 및 정선 해양관측 정점 데이터를 통해 수온, 염도 구조를 수집하고, 수집된 데이터를 바탕으로 월별 평균 음속 구조를 분석하였다. Bellhop 모델링을 통해 해상 시운전 구역 내 해저 지형 선택, 선체고정형소나와 표적함의 배치, 음파 전송 방향 및 빔 조향각 설정이 포함된 해상 시운전 세부 수행 방안을 제안하였다. 또한, 획득 데이터를 활용하여 물리정보신경망이 적용된 기계학습 모델을 도출하였다. 이를 통해 해상 시운전 구역 내 특정 지점에서 해상 시운전을 수행하는 시점의 계절적 요소를 반영한 음속 구조를 예측하고, Bellhop 모델링 결과를 통해 계절적 요인에 의한 탐지 성능 변동성을 반영한 해상 시운전 방안을 제시하였다.
-
A sea trial method of hull-mounted sonar using machine learning and numerical experiments
-
Research Article

-
Sonar detection performance analysis considering bistatic target strength
양상태 표적강도를 고려한 소나 탐지성능 분석
-
Wonjun Yang, Dongwook Kim, Dae Hyeok Lee, Jee Woong Choi, and Su-Uk Son
양원준, 김동욱, 이대혁, 최지웅, 손수욱
- For effective bi-static sonar operation, detection performance analysis must be performed reflecting the characteristics of sound propagation due to the ocean environment …
효과적인 양상태 소나 운용을 위해서는 해양환경 요인에 의한 음파전달 특성과 표적의 정보를 반영한 탐지성능 분석이 수행되어야 한다. 하지만 기존의 양상태 소나 탐지성능 …
- For effective bi-static sonar operation, detection performance analysis must be performed reflecting the characteristics of sound propagation due to the ocean environment and target information. However, previous studies analyzing bistatic sonar detection performance have either not considered the ocean environment and target characteristics or have been conducted using simplified approaches.Therefore, in this study, we compared and analyzed the bistatic detection performance in Yellow sea and Ulleung basin both with and without considering target characteristics. A numerical analysis model was used to derive an accurate bistatic target strength for the submarine-shaped target, and signal excess was calculated by reflecting the simulated target strength. As a result, significant changes in detection performance were observed depending on the source and receiver locations as well as the target strength.
- COLLAPSE
효과적인 양상태 소나 운용을 위해서는 해양환경 요인에 의한 음파전달 특성과 표적의 정보를 반영한 탐지성능 분석이 수행되어야 한다. 하지만 기존의 양상태 소나 탐지성능 분석은 해양환경 및 표적 특성을 고려하지 않거나 단순화되어 수행되었다. 따라서 본 연구에서는 서해와 울릉분지 해역에서 해양환경과 표적의 특성을 고려한 양상태 탐지성능을 산출하였다. 잠수함 형상을 가지는 표적에 대한 양상태 표적강도 도출을 위해 수치해석 모델을 활용하였으며, 모의된 표적강도를 반영하여 신호초과를 계산하였다. 그 결과 송․수신기 위치, 양상태 표적강도에 따라 유의미한 탐지성능 변화가 확인되었다.
-
Sonar detection performance analysis considering bistatic target strength
-
Research Article

-
Comparison of score-penalty method and matched-field processing method for acoustic source depth estimation
음원 심도 추정을 위한 스코어-패널티 기법과 정합장 처리 기법의 비교
-
Keunhwa Lee, Wooyoung Hong, Jungyong Park, Su-Uk Son, Ho Seuk Bae, and Joung-Soo Park
이근화, 홍우영, 박중용, 손수욱, 배호석, 박정수
- Recently, a score-penalty method has been used for the acoustic passive tracking of marine mammals. The interesting aspect of this technique lies …
최근 해양 포유동물의 수동 음향 추적을 위해 스코어-패널티 법이 사용되고 있다. 전통적인 시간영역 정합장처리 기법은 손실함수에 측정신호와 손실신호간의 정합도만을 고려하는 반면, 스코어-패널티법은 …
- Recently, a score-penalty method has been used for the acoustic passive tracking of marine mammals. The interesting aspect of this technique lies in the loss function, which has a penalty term representing the mismatch between the measured signal and the modeled signal, while the traditional time-domain matched-field processing is positively considering the match between them. In this study, we apply the score-penalty method into the depth estimation of a passive target with a known source waveform. Assuming deep ocean environments with uncertainties in the sound speed profile, we evaluate the score-penalty method, comparing it with the time-domain matched field processing method. We shows that the score-penalty method is more accurate than the time-domain matched field processing method in the ocean environment with weak mismatch of sound speed profile, and has better efficiency. However, in the ocean enviroment with strong mismatch of the sound speed profile, the score-penalty method also fails in the depth estimation of a target, similar to the time-domain matched-field processing method.
- COLLAPSE
최근 해양 포유동물의 수동 음향 추적을 위해 스코어-패널티 법이 사용되고 있다. 전통적인 시간영역 정합장처리 기법은 손실함수에 측정신호와 손실신호간의 정합도만을 고려하는 반면, 스코어-패널티법은 측정 신호와 모의 신호의 비적합도를 반영하는 페널티 항도 추가로 고려한다. 본 연구에서는 스코어-패널티법을 파형을 알고 있는 수동 표적의 심도 추정에 적용했다. 수중 음속 구조의 불확실성을 갖는 심해 환경을 가정하고, 스코어-패널티법의 성능을 평가했다. 또한 시간영역 정합장 처리기법의 결과와 서로 비교했다. 약한 수중 음속 오정합 환경에서 스코어-패널티법은 시간영역 정합장 처리기법보다 높은 정확도를 보이고 효율적으로 동작했다. 그렇지만 수중 음속 구조의 오정합이 매우 큰 경우에는 두 기법 모두 표적의 심도 추정에는 실패했다.
-
Comparison of score-penalty method and matched-field processing method for acoustic source depth estimation
-
Research Article

-
Estimation of a source range using acoustic wavefront in bottom reflection environment
해저면 반사 환경에서 음파의 파면을 이용하는 음원의 거리 추정
-
Joung-Soo Park, Jungyong Park, Su-Uk Son, and Ho Seuk Bae
박정수, 박중용, 손수욱, 배호석
- The Wavefront Curvature Ranging (WCR) is an estimation method for a source range from the wavefront curvature of acoustic waves. The conventional …
파면곡률거리추정(Wavefront Curvature Ranging, WCR)은 음파의 파면곡률로부터 음원의 거리를 추정하는 방법이다. 기존의 파면곡률거리추정은 음속을 상수로 가정하고 삼각법으로 거리를 추정한다. 이 가정 때문에 해저면반사경로가 …
- The Wavefront Curvature Ranging (WCR) is an estimation method for a source range from the wavefront curvature of acoustic waves. The conventional method uses trigonometry to estimate the source range by assuming the sound speed as a constant. Because of this assumption, range error occurs in the ocean environment where the bottom reflection is clearly separated. In order to reduce the range error, Matched Wavefront Curvature Ranging (MWCR) was proposed applying the sound speed structure in the ocean environment and Maximum Likelihood Estimation (MLE). The range error was reduced in the results of the simulation on the proposed method. In the future, this method will be applicable to the sonar system if the reliability of ranging is confirmed by measured signal.
- COLLAPSE
파면곡률거리추정(Wavefront Curvature Ranging, WCR)은 음파의 파면곡률로부터 음원의 거리를 추정하는 방법이다. 기존의 파면곡률거리추정은 음속을 상수로 가정하고 삼각법으로 거리를 추정한다. 이 가정 때문에 해저면반사경로가 뚜렷하게 분리되는 해양환경에서는 거리 오차가 발생한다. 거리 오차를 줄이기 위해 해양의 음속구조를 적용하고 최대우도추정(Maximum Likelihood Estimation, MLE)방법으로 거리를 추정하는 정합 파면곡률거리추정(Matched Wavefront Curvature Ranging, MWCR) 을 제안하였다. 정합 파면곡률거리추정의 시뮬레이션 결과로부터 거리 오차의 감소를 확인하였다. 향후에 실측 신호로부터 거리 추정의 신뢰성을 확인하면 소나 시스템에 적용 가능할 것이다.
-
Estimation of a source range using acoustic wavefront in bottom reflection environment
-
Research Article

-
Calculation of the ultrasonic radiation force acting on a rigid circular cone and the study on the metrology for the acoustic power measurement
강체원뿔표적에 대한 초음파 방사힘 계산과 음향파워측정모델에 관한 연구
-
Kyungmin Baik, Jooho Lee, Elmina B. C. Fritzie, and Yong Tae Kim
백경민, 이주호, 프리치, 김용태
- This paper came up with the theoretical modelling of the metrology for the acoustic power using ultrasonic radiation force and showed some …
본 논문은 초음파 방사힘을 이용하여 음향파워를 측정하는 방법에 대한 이론적 모델을 세우고 이에 대한 이론적 결과를 다루었다. 이를 위해 Kirchhoff approximation 기반으로 …
- This paper came up with the theoretical modelling of the metrology for the acoustic power using ultrasonic radiation force and showed some theoretical results. In order to do this, a scattering model for a rigid circular cone based upon the Kirchhoff approximation was made, which was followed by the calculation of acoustic power, and then, was converted to the radiation force. From these works, it provided the accuracy and limitation of the conventional method using a circular cone, and the expanded metrology modelling that can be applied to a circular cone with arbitrary apex angle. Using these, this study provided the dependence of the metrology for the acoustic power using ultrasonic radiation force on the frequency and the size of the target. As a result, the correction was yielded in the value of the acoustic power calculated by the suggested International Electrotechnical Commission (IEC) method, which needs to be added when the frequency and the size of the target was considered.
- COLLAPSE
본 논문은 초음파 방사힘을 이용하여 음향파워를 측정하는 방법에 대한 이론적 모델을 세우고 이에 대한 이론적 결과를 다루었다. 이를 위해 Kirchhoff approximation 기반으로 강체원뿔표적에 대한 산란모델을 세우고 음향파워를 계산한 후 이를 방사힘으로 환산하였다. 이를 통해 원뿔표적을 사용하는 기존 방법의 정확성 및 측정 한계, 그리고 임의의 경사각의 원뿔표적으로도 측정할 수 있는 음향파워측정에 관한 확장된 이론을 제시하였다. 이를 이용하여 초음파 방사힘을 이용한 음향파워측정 방법의 주파수 및 표적 크기에 대한 의존도도 본 논문에서 제시하였다. 그결과로 주파수 및 표적 크기를 고려하였을 때 국제표준규격(International Electrotechnical Commission, IEC)에서 제시하는 방법으로 계산한 음향파워값에 추가되어야 할 보정값을 산출하였다.
-
Calculation of the ultrasonic radiation force acting on a rigid circular cone and the study on the metrology for the acoustic power measurement
-
Research Article

-
Development of the calibration procedure of the reference sound source and case study on the uncertainty evaluation
기준음원의 교정 절차 개발 및 불확도 평가 사례
-
Jae-Gap Suh and Wan-Ho Cho
서재갑, 조완호
- A Reference Sound Source (RSS) is an important standard device employed in measuring sound power. The specifications of RSS is specified in …
기준음원은 음향파워 측정에 활용되는 중요한 기준기로, 국제 표준으로 그 사양이 규정되어 있으며, 측정 표준 분야에서 주요 교정 품목으로 분류되고 있다. 이러한 기준음원은 …
- A Reference Sound Source (RSS) is an important standard device employed in measuring sound power. The specifications of RSS is specified in international standards, and it is classified as a major calibration item in the field of acoustic metrology. Since the output power of RSS is affected by the supply voltage, each country needs to secure its own calibration service system. In this study, a procedure for calibrating a RSS is established based on the reverberant room conditions and uncertainty evaluation is conducted. Basically, the calibration procedure can apply a precision measurement process of acoustic power, and here, the measurement method using the reverberation chamber of ISO 3741 is applied. For this purpose, a measurement system is constructed, measurements are conducted with two types of RSS, and measurement uncertainty is evaluated. Through measurement examples, it is confirmed that the non-uniformity of the sound pressure distribution in the reverberation room and the volume measurement uncertainty contributed significantly to the overall uncertainty. Additionally, the influence of input voltage is experimentally examined to examine the uncertainty contribution that can be reflected in acoustic power measurements.
- COLLAPSE
기준음원은 음향파워 측정에 활용되는 중요한 기준기로, 국제 표준으로 그 사양이 규정되어 있으며, 측정 표준 분야에서 주요 교정 품목으로 분류되고 있다. 이러한 기준음원은 공급 전압에 의하여 그 출력이 영향을 받기 때문에 각국에서 자체적으로 교정 서비스 체계를 확보할 필요가 있다. 본 연구에서는 잔향실 조건에서 기준음원을 교정하는 절차를 수립하고 불확도를 평가하였다. 교정 절차는 기본적으로 음향 파워의 정밀급 측정과정을 적용할 수 있으며, 여기서는 ISO 3741의 잔향실을 활용한 측정 방법을 검토하였다. 이를 위한 측정 시스템을 구성하고 실제 2종의 기준음원에 대하여 측정을 수행하고 측정 불확도를 산출하였다. 측정 예를 통하여 잔향실 내 음압 분포의 불균일성과 체적 측정 불확도가 전체 불확도에 기여가 큰 것을 확인하였다. 추가적으로 입력 전압에 대한 영향을 실험적으로 검토하여 음향 파워 측정에서 반영할 수 있는 불확도 기여량을 검토하였다.
-
Development of the calibration procedure of the reference sound source and case study on the uncertainty evaluation
-
Research Article

-
A method for localization of multiple drones using the acoustic characteristic of the quadcopter
쿼드콥터의 음향 특성을 활용한 다수의 드론 위치 추정법
-
In-Jee Jung, Wan-Ho Cho, and Jeong-Guon Ih
정인지, 조완호, 이정권
- With the increasing use of drone technology, the Unmanned Aerial Vehicle (UAV) is now being utilized in various fields. However, this increased …
드론 기술의 발전으로 인해서 최근 다양한 분야에서 무인항공기가 활용되고 있으며, 이와 더불어 드론 사용 증가에 따르는 여러 가지 문제들이 발생하고 있다. 드론은 …
- With the increasing use of drone technology, the Unmanned Aerial Vehicle (UAV) is now being utilized in various fields. However, this increased use of drones has resulted in various issues. Due to its small size, the drone is difficult to detect with radar or optical equipment, so acoustical tracking methods have been recently applied. In this paper, a method of localization of multiple drones using the acoustic characteristics of the quadcopter drone is suggested. Because the acoustic characteristics induced by each rotor are differentiated depending on the type of drone and its movement state, the sound source of the drone can be reconstructed by spatially clustering the results of the estimated positions of the blade passing frequency and its harmonic sound source. The reconstructed sound sources are utilized to finally determine the location of multiple-drone sound sources by applying the source localization algorithm. An experiment is conducted to analyze the acoustic characteristics of the test quadcopter drones, and the simulations for three different types of drones are conducted to localize the multiple drones based on the measured acoustic signals. The test result shows that the location of multiple drones can be estimated by utilizing the acoustic characteristics of the drone. Also, one can see that the clarity of the separated drone sound source and the source localization algorithm affect the accuracy of the localization for multiple-drone sound sources.
- COLLAPSE
드론 기술의 발전으로 인해서 최근 다양한 분야에서 무인항공기가 활용되고 있으며, 이와 더불어 드론 사용 증가에 따르는 여러 가지 문제들이 발생하고 있다. 드론은 크기가 매우 작아서 레이더나 광학장비로 탐지하기 어려운 문제가 있으며, 따라서 최근에는 음향학적인 방법을 이용한 추적 방식이 적용되고 있다. 본 논문은 쿼드콥터 드론의 음향 특성을 활용하여 다수의 드론 위치를 추정하는 방법을 다루었다. 드론의 종류와 드론의 움직임 상태에 따라 각 로터로부터 유발되는 음향 특성이 구별되므로, 블레이드 통과 주파수 및 이에 대한 고조파 음원에 대한 위치 추정을 수행한 결과를 공간 군집화하여 드론의 음원을 재현하였다. 재현된 음원은, 위치 추정 알고리즘을 적용하여 최종적으로 다수의 드론 음원에 대한 위치를 결정하는데 사용된다. 쿼드콥터 드론의 음향 특성을 분석하기 위한 실험을 수행하였으며, 이때 측정한 음향 신호를 기반으로 서로 다른 세 종류의 드론에 대한 음원 위치 추정 시뮬레이션을 수행하였다. 이를 통해 드론의 음향 특성을 활용하여 다수의 드론 위치를 추정할 수 있음을 확인하였고, 분리된 드론 음원의 명확성과 음원 추정 알고리즘이 다수의 드론 위치 추정 정확도에 영향을 주는 것을 관찰하였다.
-
A method for localization of multiple drones using the acoustic characteristic of the quadcopter
-
Research Article

-
Functional beamforming for high-resolution ultrasound imaging in the air with random sparse array transducer
고해상도 공기중 초음파 영상을 위한 기능성 빔형성법 적용
-
Choon-Su Park
박춘수
- Ultrasound in the air is widely used in industry as a measurement technique to prevent abnormalities in the machinery. Recently, the use …
공기중 초음파 측정은 각종 기계 설비류의 이상 발생 예방 활동으로 산업계에서 사용되고 있다. 최근에는 다수의 초음파 센서 배열을 이용하여 설비의 이상 발생 …
- Ultrasound in the air is widely used in industry as a measurement technique to prevent abnormalities in the machinery. Recently, the use of airborne ultrasound imaging techniques, which can find the location of abnormalities using an array transducers, is increasing. A beamforming method that uses the phase difference for each sensor is used to visualize the location of the ultrasonic sound source. We exploit a random sparse ultrasonic array and obtain beamforming power distribution on the source in a certain distance away from the array. Conventional beamforming methods inevitably have limited spatial resolution depending on the number of sensors used and the aperture size. A high-resolution ultrasound imaging technique was implemented by applying functional beamforming as a method to overcome the geometric constraints of the array. The functional beamforming method can be expressed as a generalized beam forming method mathematically, and has the advantage of being able to obtain high-resolution imaging by reducing main-lobe width and side lobes. As a result of observation through computer simulation, it was verified that the resolution of the ultrasonic source in the air was successfully increased by functional beamforming using the ultrasonic sparse array.
- COLLAPSE
공기중 초음파 측정은 각종 기계 설비류의 이상 발생 예방 활동으로 산업계에서 사용되고 있다. 최근에는 다수의 초음파 센서 배열을 이용하여 설비의 이상 발생 위치를 찾을 수 있는 공기중 초음파 영상화 기법의 활용이 증가하고 있다. 초음파 음원의 위치를 가시화하기 위해 센서 별 위상 차이를 이용하는 빔형성법이 사용된다. 2차원 평면에 분포된 초음파 센서 배열을 이용해 3차원 공간에서 빔형성 파워 분포를 구할 수 있다. 본 논문에서는 관심 파장보다 크기가 큰 초음파 센서로 구성된 랜덤 희소배열(random sparse array)을 사용하고, 초음파 배열이 분포한 평면으로부터 일정한 거리만큼 떨어진 평행한 평면 내에서의 빔형성 파워 분포를 통해서 음원의 위치를 보여주는 영상화 기법을 구현하고자 한다. 기존의 빔형성법은 사용 하는 배열 센서의 개수와 그에 따른 구경의 크기 등에 의해 공간 해상도가 제한될 수 밖에 없다. 본 연구에서는 배열이 가지는 기하학적 제약을 극복할 수 있는 방법으로 기능성 빔형성법을 적용하여 고해상도 초음파 영상화 기법을 구현하였다. 기능성 빔형성법은 수학적으로 일반화된 형태의 빔형성법으로 표현 가능하고, 기존의 빔형성법을 통해 얻어진 영상에서 주엽의 폭과 부엽의 크기를 저감시키는 역할을 하여 고해상도 영상화를 얻을 수 있는 장점이 있다. 컴퓨터 시뮬레이션을 통해 제안한 방법에 의한 영상화 성능을 관찰한 결과, 초음파 희소배열을 이용하여 공기중 초음파 음원의 해상도 증대가 성공적으로 구현됨을 확인할 수 있었다.
-
Functional beamforming for high-resolution ultrasound imaging in the air with random sparse array transducer

Journal Informaiton
 The Journal of the Acoustical Society of Korea
The Journal of the Acoustical Society of Korea
The Journal of the Acoustical Society of Korea











한국음향학회지는 KCI, ESCI, Scopus
등재저널입니다.



CLOSE

한국음향학회지는 KCI, ESCI, Scopus
등재저널입니다.
CLOSE