

I. 서 론
파킨슨병은 뇌의 신경세포 손상으로 인해 발생하는 신경퇴행성질환으로, 뇌졸중, 치매와 함께 노년기 3대 질환 중 하나이다.[1]전 세계적으로 2016년 기준 약 600만 명 이상의 환자가 이 질환을 앓고 있으며, 인구고령화에 따라 유병률이 증가하는 경향을 보이고 있다.[2] 파킨슨병의 주요 증상은 운동 증상과 비운동 증상으로 구분되며, 주요 운동 증상은 떨림, 운동의 느려짐, 경축, 자세의 불안정, 보행이상 등이며, 비운동 증상으로는 인지 기능 장애, 정신 증상, 수면 장애 등이 나타난다.[3] 또한 파킨슨병 환자들의 약 70 % 이상은 운동기능저하로 인한 음성장애를 경험한다고 보고되고 있다.[4],[5]대표적으로 단조로운 음도, 강세감소, 단조로운 강도, 거친 소리, 기식음, 부정확한 자음, 부적절한 쉼, 속도변이성 등의 특징을 보인다.[6]이러한 음성 특징을 감지하는 음성 신호분석이 파킨슨병의 진단을 위해 활용되고 있으며[7] 기계학습 방식의 발달로 음성분석의 진단 정확도가 점차 향상되고 있다.
음성 신호 분석을 통한 파킨슨병 진단의 기존 연구들[7],[8],[9],[10],[11],[12]을 살펴보면, 파킨슨병 진단파라미터로 제안된 F0, Shimmer, Jitter, MPT, HNR[8]뿐만 아니라, 다양한 음성 파라미터들을 알고리즘에 적용하여 파킨슨병을 진단하였다. 파킨슨병 진단을 위한 음성 분석연구[7]에서는 음성 특징 선택 과정에서 GA(Genetic Algorithm)를 통해 Fhi(Hz), Fho(Hz), RAP, APQ5 등의 특징 값들을 선택하여 SVM(Support Vector Machine) 식별방식에 적용하였고, 음성 특징을 통한 파킨슨병 식별 알고리즘의 성능 비교 연구[11]에서는 F0(Hz), Jitter(%), RAP, PPQ, Shimmer 등의 선택된 특징 값들을 J48 및 REFTree 식별 알고리즘에 적용하여 성능을 비교 분석하였다.
기존 연구에서 적용한 식별 알고리즘은 데이터와 레이블을 이용하여 모델을 학습시키고 식별하는 기계학습 방식이다. 이러한 기계학습 방식 중의 하나인 심층 신경망은 데이터의 특징과 패턴을 학습하는 방식으로 기존의 식별 알고리즘 보다 높은 인식률을 제공한다. 하지만, 인식률 개선을 위해 신경망의 깊이가 깊어지게 되어, 계산량의 증가와 함께 gradient exploding/vanishing 문제가 발생하였다.[13] 이와 같은 제한점을 해결하기 위해 잔류 학습 방식이 개발되었고 심층 신경망에 잔류 학습 방식을 결합한 모델이 깊은 신경망 구조에서도 뛰어난 성능을 보여주고 있다.[14]
본 논문에서는 음성 신호로부터 추출한 음성 특징과 심층 순환 신경망에 잔류 학습 방식을 결합한 심층 잔류 순환 신경망(Deep Residual Gated Recurrent Neural Network, DRGRNN)을 이용하여 파킨슨병 진단의 정확도를 높이는 방식을 제안한다.
본 논문의 구성은 다음과 같다. II장에서는 제안하는 파킨슨병 진단 방식에 관해 설명한다. III장에서는 DRGRNN 기반의 파킨슨병 진단결과를 제시한다. 마지막으로 Ⅳ장에서 본 논문의 결론을 맺는다.
II. 파킨슨병 진단 방식의 구조
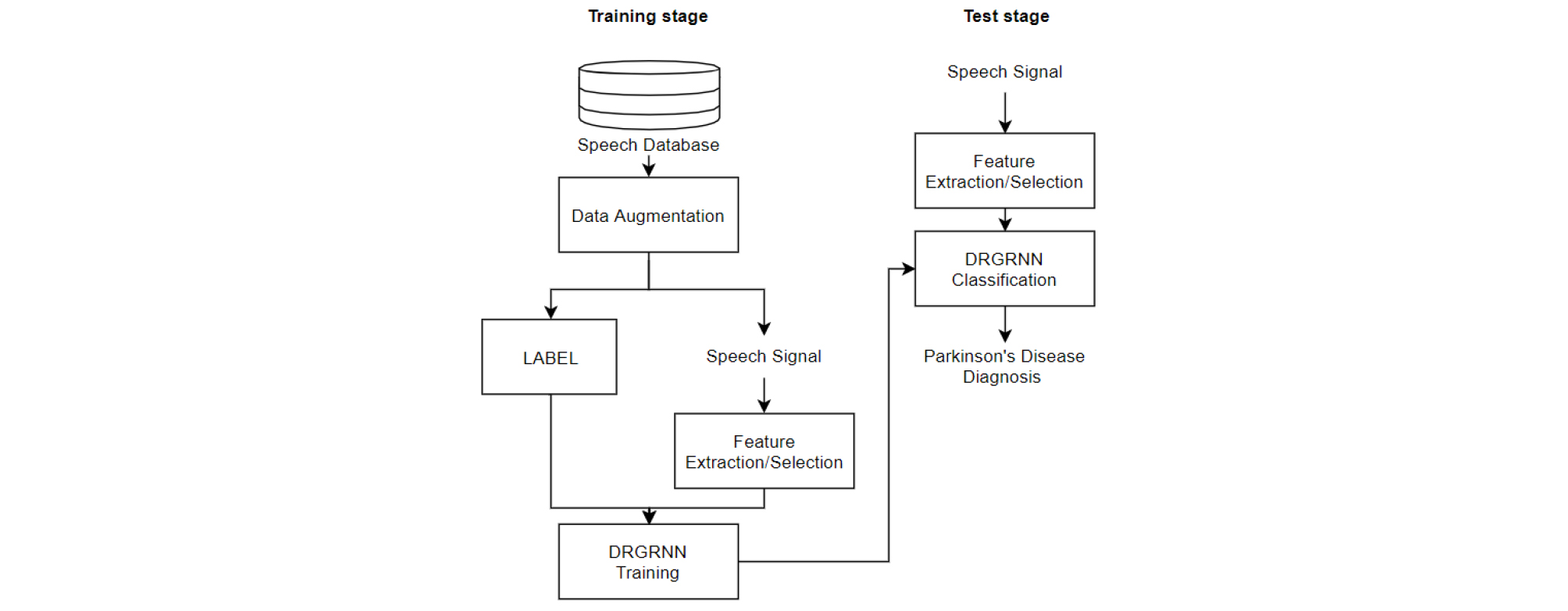
Fig. 1은 본 논문에서 제안한 음성 신호 분석을 통한 파킨슨병 진단 방식의 전체 구조도이다. 전체구조도는 모델 학습부와 식별부로 구성된다. 모델 학습부에서는 데이터 희소성 문제를 해결하기 위해 데이터 증강 방식을 사용하여 학습데이터를 확장한다. 그리고 음성 신호로부터 음성 특징들을 추출한 후, 파킨슨병 진단에 유용한 특징들을 선택한다. 선택된 음성 특징들은 DRGRNN에 적용되어 학습을 통해 파킨슨병 식별 모델을 생성한다. 식별부에서는 환자 혹은 일반인의 음성 신호로부터 음성 특징을 추출하고 식별 모델이 적용된 DRGRNN에 입력되어 파킨슨병의 유무를 판단한다.
2.1 음성 특징 선택 방식
Table 1은 본 연구에 투입된 음성 특징에 대한 설명이다. 본 논문에서는 22개의 음성 특징 중 일부를 조합하여 사용하였다. 파킨슨병 진단에 유용한 음성 특징을 선택하기 위해 심층 신경망 구조를 가진 GRU(Gated Recurrent Unit)[13], LSTM(Long-Short Term Memory)[15], DRGRNN 등의 각 방식에 단일 음성 특징을 적용하여 파킨슨병 식별 정확도를 비교하였다. 세 가지 식별 알고리즘에서 spread1, F0(Hz), PPE, Jitter(%), RAP, DDP 순으로 6개의 음성 특징들이 높은 파킨슨병 식별 정확도를 제공하였다.
Table 1. List of extracted speech features from speech signal.
따라서 본 논문에서는 파킨슨병 진단을 위한 음성 특징으로 F0(Hz), Jitter(%), RAP, DDP, spread1, PPE를 선택하였고 자세한 설명은 다음과 같다.
F0 (Hz)는 기본 주파수의 평균값으로 목소리의 높낮이를 측정한다. 주파수는 이며 는 신호의 주기를 의미한다. spread1은 기본주파수의 비선형 측정값으로 음성 신호의 잡음을 측정하기 위해 사용된다.[16]
Jitter(%)는 단위 결과 값 동안 발음에서 성대의 진동으로 인한 음도의 변화를 %로 표현한 값으로 음도의 불규칙한 변이를 측정하며 계산식은 다음과 같다.[17]
| $$Jitter(\%)=\frac{{\displaystyle\frac1{N-2}}{\displaystyle\sum_{i=2}^{N-1}}\left|T_i-T_{i-1}\right|}{{\displaystyle\frac1N}{\displaystyle\sum_{i=1}^N}T_i},$$ | (1) |
여기서 는 i번째 윈도우의 기본 주파수 주기를 말하며 N은 전체 윈도우의 개수이다.
RAP는 인접한 두 개의 구간에서 음도의 변동 값의 상대적인 변화 값으로 Eq. (2)와 같고 DDP는 인접한 Jitter의 2차 미분 값으로 Eq. (3)과 같이 정의된다. RAP, DDP는 음도 변동에 의한 음질의 변화를 측정하는 파라미터로 음성 측정의 정확도를 높이기 위해 음도 변동 량을 다양하게 조합하여 준주기성 관련 음질을 정량적으로 나타내는 역할을 한다.
| $$DDP=\frac{{\displaystyle\frac1{N-2}}{\displaystyle\sum_{i=2}^{N-1}}\left|(T_{i+1}-T_i)-(T_i-T_{i-1})\right|}{{\displaystyle\frac1N}{\displaystyle\sum_{i=1}^N}T_i}.$$ | (3) |
PPE는 음도 변이를 측정할 때 주변 소음이나 정상인에게 발생하는 변이를 제거한 엔트로피로서 Eq. (4)와 같으며 음도의 비정상적인 변이 측정의 정확도를 높여준다.
| $$PPE=-\sum_rP(r)\log(P(r)),$$ | (4) |
여기서 P(r)은 상대 반음 변이 발생에 대한 이산 확률 분포이다.[1]
2.2 심층 잔류 순환 신경망
본 논문에서는 선택된 음성 특징들을 적용하여 파킨슨병을 진단하기 위해 파킨슨병 식별 알고리즘으로 DRGRNN을 사용한다.
Fig. 2는 본 논문에서 사용한 DRGRNN의 전체 구조도이다. 제안한 DRGRNN은 3개의 Residual GRNN(Gated Recurrent Neural Network) Layer와 파킨슨병 증상식별을 위해 적용된 ReLU(Rectified Linear Units)로 구성되며 Residual GRNN Layer는 3개의 GRNN과 2개의 잔류연결로 구성된다.
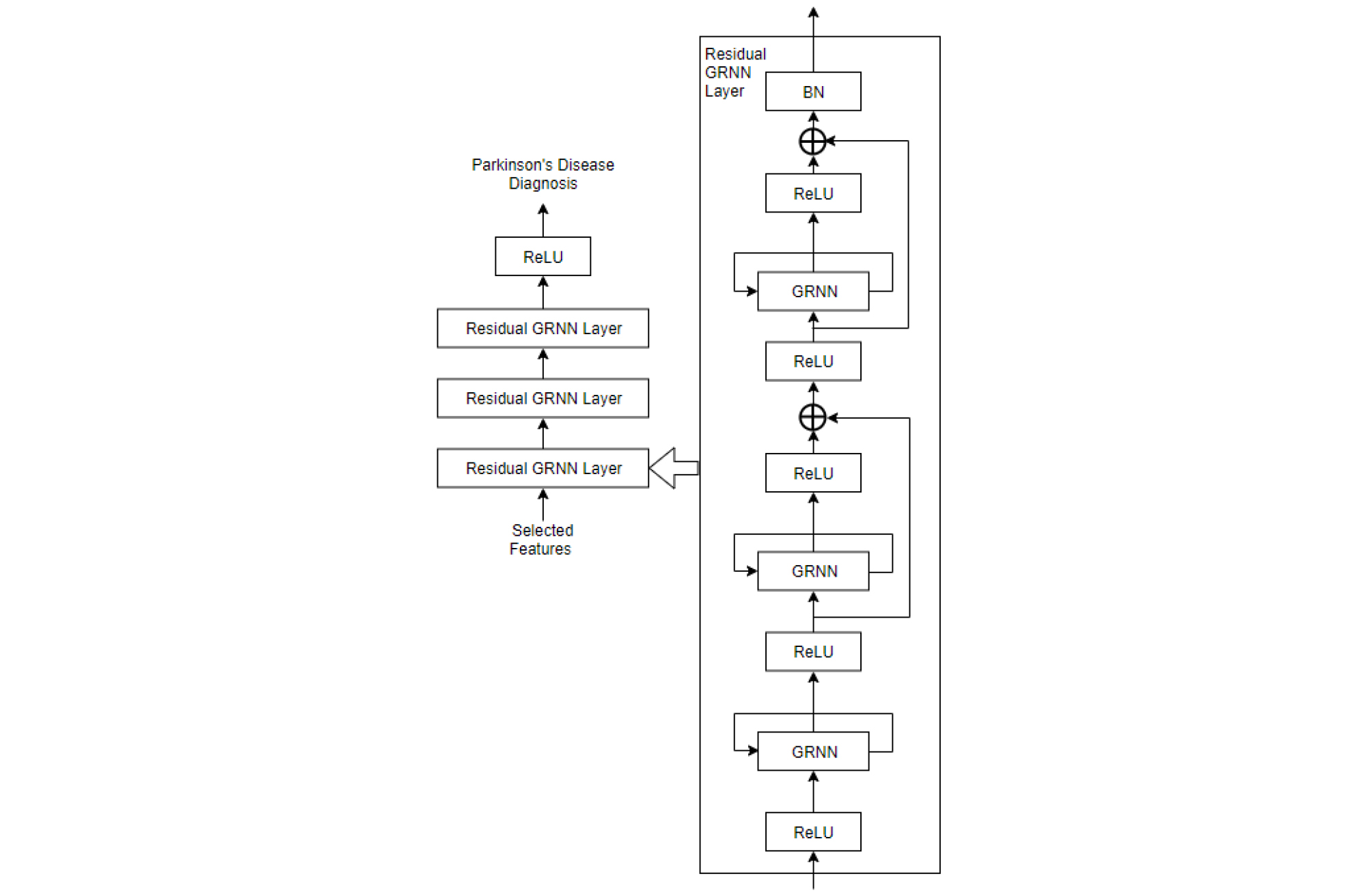
GRNN은 LSTM에 비해 상대적으로 간단한 구조의 GRU를 사용하여 RNN(Recurrent Neural Network)의 gradient exploding/vanishing 문제를 방지한다.[14] LSTM은 3개의 게이트를 사용하여 내부 셀 유닛의 정보 흐름을 제어하지만 GRU는 업데이트 게이트 z와 리셋 게이트 r로 구성된 2개의 게이트만을 사용한다. 업데이트 게이트는 메모리로 유입되는 정보를 제어하고 리셋 게이트는 메모리에서 유출되는 정보를 제어한다. 또한 GRU는 별도의 메모리 유닛 없이 게이트 유닛을 통해 유닛 내부의 정보 흐름을 변조한다. 이는 다음과 같이 나타낼 수 있다.
| $$z_t=\sigma(R_z\left\lceil h_{t-1},\;x_t\right\rceil+b_z),$$ | (5) |
| $$r_t=\sigma(R_r\left\lceil h_{t-1},\;x_t\right\rceil+b_r),$$ | (6) |
| $$\widetilde{h_t}=\tan h(R_h\left\lceil r_t\circ h_{t-1},\;x_t\right\rceil+b_h),$$ | (7) |
| $$h_t^{GRNN}=(1-z_t)\circ h_{t-1}+z_t\circ\widetilde{h_t},$$ | (8) |
여기서 와 는 각각 현재의 입력, 활성화 함수, 후속 활성화 함수, 편향 벡터를 나타낸다. 또한 R 과 𝜎(∙), ∘는 가중치 행렬과 요소별 논리 시그모이드 함수, 요소별 곱셈 연산을 나타낸다.
GRNN의 잔류연결은 특정 레이어에 입력된 데이터를 다음 레이어에 직접 전달하기 때문에 gradient vanishing 문제를 효과적으로 해결한다. 또한 잔류 학습 방식은 덧셈 연산자를 통해 gradient가 제한적인 레이어를 우회하여 통과하기 때문에 학습 연산이 간단해진다는 장점이 있다. 잔류연결의 연산은 다음과 같이 나타낼 수 있다.
| $$h_{k+1}^{DRGRNN}=h_k^{GRNN}+\Lambda(h_k^{GRNN},\;x_k;R_k),$$ | (9) |
여기서 와 은 k번째 유닛의 입력과 출력을 나타내며 𝛬은 가중치 파라미터인 를 이용한 잔류 함수이다.
잔류 학습 방식은 gradient를 방해하지 않고 잔류연결로 구성된 레이어의 출력을 정제하는데 기여하기 때문에 학습 성능을 높이면서 깊은 신경망 구성을 가능하게 한다.[14]
III. 실 험
3.1 실험 데이터
본 논문에서는 파킨슨병 환자와 일반인을 식별하기 위한 음성 특징 데이터로 UCI Machine Learning Repository[1]에서 제공된 데이터베이스를 사용하였다.
데이터는 24명의 파킨슨병 환자를 포함한 총 32명의 피 실험자들로부터 수집된 195개 데이터로 구성되어 있다. 음성 특징은 음성 분석 기기 MDVP(Multi Dimenssional Voice Program)를 이용하여 음성 신호로부터 추출되었으며[1]피 실험자의 번호와 파킨슨병 유무를 나타내는 이름과 상태 변수를 제외한 22개의 연속/비연속적인 음성 특징들로 구성되어 있다. 본 논문에서는 식별 알고리즘의 성능을 측정하기 위해 3-fold 교차 유효성 검증 방법을 사용하였다. 이 검증 방법에서는 데이터의 개수를 동일하게 3개 그룹으로 분할한 후, 각 그룹을 테스트 세트로 선택하고 나머지 2개의 그룹을 학습 세트로 사용한다. 본 논문에서는 파킨슨병 환자 대 일반인의 비율을 모든 그룹에 동일하게 적용하였으며 총 3번의 실험을 통해 각 그룹에 대한 정확도를 측정한 뒤, 평균을 내어 식별 알고리즘의 성능을 측정하였다.
3.2 실험 결과
실험은 음성 특징 선택부에서 선택한 6개의 음성 특징 F0(Hz), Jitter(%), RAP, DDP, spread1, PPE를 DRGRNN 식별 방식에 적용하여 성능을 테스트하고 기존의 식별 알고리즘과 비교하였다.
Table 2는 실험 결과를 나타낸다. 기존의 식별 알고리즘 중에서는 GA와 SVM을 결합한 모델의 정확도가 93.6 %로 REPTree, kNN(k-Nearest Neighbor)[12]보다 높게 나타났으며, 심층 신경망 구조의 LSTM과 GRU의 정확도는 각각 96.2 %와 96.5 %로 GA와 SVM을 결합한 기존의 알고리즘보다 약 2.6 %, 2.9 % 향상되었다. 또한 LSTM보다 비교적 간단한 구조를 사용하는 GRU의 정확도가 약 0.3 % 정도 높게 나타났다. 최종적으로, 본 논문에서 제안한 DRGRNN은 98.4 %로 비교한 방식들 중 가장 뛰어난 정확도를 나타내었다.
Table 2. Results of Parkinson's patient classification through speech features.
| Methods | Recognition accuracy |
| REPTree | 84.3 % |
| kNN | 89.2 % |
| GA+SVM | 93.6 % |
| LSTM | 96.2 % |
| GRU | 96.5 % |
| DRGRNN | 98.4 % |
