

I. 서 론
인식 성능이 저하되는 가장 큰 원인 중 하나는 음성 인식 시스템에 장착되어지는 음향 모델을 훈련하는 환경과 실제 시스템을 적용하는 환경이 음향학적 측면에서 불일치 한다는 점이다. 이러한 음향학적 불일치를 줄이고 음성 인식 성능 향상을 위해 다양한 연구가 진행되어 왔다.[1-6] 이러한 연구는 두 가지 측면으로 나눌 수 있는데, 하나는 음성 인식 시스템의 전처리 단계에서 잡음을 제거하고 음성을 향상시키거나, 잡음에 강인한 음성 특징을 추출하거나, 또는 특징 영역에서 잡음을 제거하거나 보상하는 방법이다. 다른 접근 방법은 이미 훈련되어진 음향 모델을 새로운 잡음 환경과 일치하도록 적응해주는 기법이다. 최근에는 심층 신경망을 활용한 기법들이 소개되었다.[7,8]
본 논문에서는 잡음 환경에 강인한 음성 인식을 위한 효과적인 모델 적응 기법을 제안하고 그 성능을 평가한다. 기존의 전처리 기법과 모델 적응 기법에서는 잡음 환경에서의 음성 신호 및 모델 파라미터의 변화에 대해 다양한 근사화를 통한 모델을 가정하였다. 본 논문에서는 심층 신경망(Deep Neural Network, DNN)이 갖는 우수한 비선형적 특성을 이용하여 잡음 오염 함수를 예측하고 이를 모델 적응에 이용하고자 한다. 성능 평가를 위해 Aurora 2.0 평가 프레임워크와 데이터베이스를 사용하였다.[9]
II. 잡음 오염 함수
깨끗한 음성 신호와 채널 왜곡 요소, 배경 잡음 신호는 오염된 음성 신호와 켑스트럼 특징 벡터 도메인 상에서 다음과 같은 관계를 갖는다.[3]
| $$\boldsymbol y=\boldsymbol x+\boldsymbol h+\boldsymbol C\log(1+\exp(\boldsymbol C^{-1}(\boldsymbol n-\boldsymbol x-\boldsymbol h))).$$ | (1) |
Eq. (1)에서 x, y, h, n는 각각 깨끗한 음성, 오염된 음성, 채널 왜곡 요소, 배경 잡음의 켑스트럼 특징 벡터를 나타내며, C는 이산 코사인 변환 행렬이다. 따라서 음성의 잡음 오염 과정은 Eq. (1)과 같이 깨끗한 음성과 잡음 요소를 입력으로 하여 오염 음성을 출력으로 갖는 비선형 함수 로 생각할 수 있다.
| $$\boldsymbol y=f_{nc}(\boldsymbol x\boldsymbol,\boldsymbol h\boldsymbol,\boldsymbol n).$$ | (2) |
지금까지 개발된 다양한 전처리 기법과 모델 적응 기법에서는 위와 같은 비선형 특성을 갖는 잡음 오염 함수를 여러 수학적 기법을 사용하여 선형적으로 근사화하여 적용해왔다.[3-6] 본 논문에서는 일반적인 전처리 기법, 모델 적응 기법에서 근사화를 통해 모델링하는 잡음 오염 함수를 DNN이 갖는 비선형성을 이용하여 모델링하고자 한다.
III. DNN 기반의 잡음 오염 함수 예측을 이용한 음향 모델 적응 기법
본 논문에서는 잡음 오염 함수를 심층 신경망 학습을 통해 예측하여 이를 음향 모델 적응에 적용하는 기법을 제안한다. L개의 층을 갖는 DNN에서 l번째 층은 다음과 같이 표현할 수 있다.
| $$\boldsymbol v^{\mathbf l}\boldsymbol=f^l(\boldsymbol W^l\boldsymbol v^{l-1}+\boldsymbol b^l).$$ | (3) |
위 식에서 과 은 각각 l번째 층에서의 가중치 행렬과 바이어스 벡터, 출력 벡터를 나타내며, 함수 는 각 층에서 사용된 활성 함수를 나타낸다.
잡음 오염 함수 예측을 위해 잡음 환경에 오염된 음성 데이터와 이에 대응되는 깨끗한 음성 데이터가 필요하다. 깨끗한 음성 특징 벡터와 오염된 잡음 신호의 특징 벡터를 결합하여 신경망의 입력 데이터로 사용한다. 본 논문에서는 오염 음성의 비음성 구간에서 잡음 모델의 평균 을 구하여 이를 깨끗한 음성 특징 벡터와 결합하여 신경망의 입력 데이터로 사용한다.
| $$v^0=\lbrack{\boldsymbol x}_t;{\boldsymbol n}_t\rbrack\simeq\lbrack{\boldsymbol x}_t;{\boldsymbol\mu}_n\rbrack.$$ | (4) |
학습의 목표가 되는 레이블 데이터는 입력 데이터의 깨끗한 음성 특징에 대응되는 오염 음성 특징 벡터 이 된다. 각 층의 활성화 함수는 sigmoid 함수를 사용하고, 최종 출력 층에서는 특징 벡터 차원의 값을 생성하기 위해 활성화 함수를 사용하지 않는다. 이와 같은 구조의 DNN을 학습하게 되면 최종적으로 다음과 같은 잡음 오염 모델 함수를 얻을 수 있다.
| $$\widetilde{\boldsymbol y}=\widetilde{f_{nc}}(\boldsymbol x\boldsymbol,\boldsymbol n\boldsymbol;\boldsymbol W\boldsymbol,\boldsymbol b\boldsymbol).$$ | (5) |
Eq. (5)를 이용하면 깨끗한 음성 특징 벡터와 잡음 신호의 특징 벡터를 입력으로 하여 DNN 학습을 통해 얻어진 가중치 행렬과 바이어스 벡터를 이용하여 오염된 음성 특징 벡터를 구할 수 있다. 따라서 Eq. (5)와 같이 예측된 잡음 오염 함수는 특징 벡터 도메인에서 깨끗한 음성, 잡음, 오염된 음성 사이의 비선형적인 관계를 표현한다.
학습으로부터 얻어진 잡음 오염 함수는 다음과 같이 음향 모델 적응 과정에 이용된다. 오염된 입력 음성의 특징 벡터의 비음성 구간에서 잡음에 대한 평균 벡터 를 계산한다. 취득된 잡음 평균 벡터와 HMM 모델의 각 상태를 구성하는 출력 함수의 평균 벡터를 입력으로 하여 잡음 환경에 적응된 평균 벡터를 구할 수 있다.
위 식에서 는 깨끗한 음성 모델의 상태 (state) s의 k번째 가우시안 요소의 평균 벡터를 나타내고 는 위 식에 의해 생성된 평균 벡터이며, 잡음 환경에 적응된 모델 파라미터를 나타낸다. Fig. 1은 본 연구에서 잡음 오염 함수 예측에 사용한 DNN의 구조를 설명한다. 각 층의 숫자는 뉴런의 개수를 나타낸다.
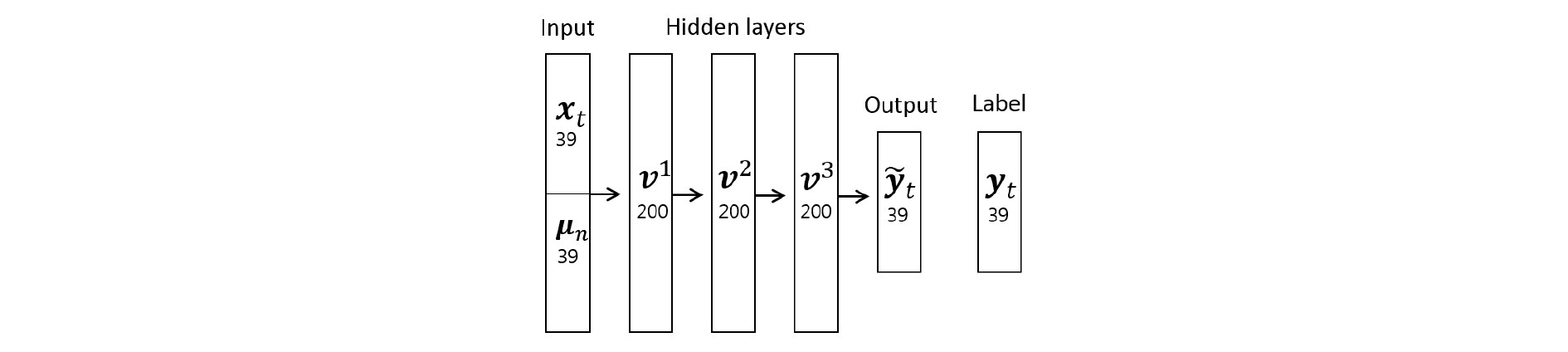
IV. 실험 및 결과
객관적인 성능 평가를 위해서 Aurora 2.0에서 제공하는 평가 방식을 따랐다.[9] 대표적 전처리 알고리즘으로 가장 일반적으로 사용되는 주파수 차감법 (Spectral Subtraction, SS) 기법, 켑스트럼 평균 정규화 (Cepstrum Mean Normalization, CMN), VTS(Vector Taylor Series) 기반 알고리즘을 평가하였다.[3] 또한 제안하는 모델 적응 기법과의 비교를 위해 GMM(Gaussian Mixture Model) 기반의 특징 보상 기법의 하나인 RATZ 특징 보상 기법,[3] 대표적인 모델 적응 기법의 하나인 MLLR 기반 적응 기법,[5] 모델 결합 기법의 하나인 PMC 기법[6]의 성능을 평가하였다. 본 논문에서는 음성 인식 성능의 지표로 단어 오인식율(Word Error Rate, WER)을 사용하였다.
Table 1은 “일치” 잡음 환경에서 성능 평가 비교를 나타낸다. 이 실험에서는 성능 평가를 위해 Aurora 2.0에 포함되어 있는 SetA 테스트 데이터를 사용하였다. Table 1의 결과는 각 테스트 잡음 환경에서 모든 SNR 환경(0 dB, 5 dB, 10 dB, 15 dB, 20 dB) 에 대한 WER의 평균을 구한 결과이다. 제안하는 기법에서의 잡음 오염 함수 예측을 위하여 Aurora 2.0에서 제공하는 multi-condition training 데이터를 사용하였다. multi-condition training 데이터는 SetA 테스트 데이터와 동일한 잡음 데이터를 이용하여 생성한 훈련 데이터이므로 테스트 환경을 사전에 알고 있는 “일치” 조건에 해당한다.
Table 1. Recognition performance in “known” noisy environments as average over all SNRs: 0 dB, 5 dB, 10 dB, 15 dB, and 20 dB (WER, %).
Table 1에서 확인할 수 있는 것과 같이 본 논문에서 제안하는 DNN 기반의 오염 함수 예측을 통한 모델 적응 기법이 평가 대상의 모든 전처리 기법과 모델 적응 기법과 비교하여 모든 잡음 환경에서 현저히 낮은 WER을 보이고, 평균 WER도 15.27 %로 대폭적으로 향상된 성능을 나타내는 것으로 관찰되었다. 이와 같은 결과는 본 논문에서 제안하는 DNN 기반의 오염 함수 예측 기법이 비선형적인 잡음 오염 과정을 효과적으로 모델링함으로써 잡음 환경을 잘 반영하는 모델 파라미터로 변환할 수 있음을 입증한다.
Table 2는 잡음 오염 함수 예측을 위해 DNN 학습에 사용한 학습용 오염 음성 데이터에 테스트 환경의 잡음이 포함되지 않은 “불일치” 잡음 환경에 대한 성능 평가를 나타낸다. 불일치 잡음 환경 성능 평가를 위하여 다른 리소스의 잡음 샘플을 이용하여 새로운 잡음 오염 음성 데이터를 생성하였다. 잡음 데이터로는 NOISEX92에 포함되어 있는 Factory, Car, Babble 잡음과 한국 가요의 전주부분에서 취득한 배경 음악(Music)을 사용하였다.
Table 2. Recognition performance in “unknown” noisy environments as average over all SNRs: 0 dB, 5 dB, 10 dB, 15 dB, and 20 dB (WER, %).
Table 2의 결과와 같이 Music 잡음 환경을 제외한 세가지 잡음 환경에서 제안한 잡음 오염 모델 함수 예측 기반의 모델 적응 기법이 기존의 전처리 기법 및 모델 적응 기법에 비해 대폭적인 성능 향상을 가져온 것을 알 수 있다. 기존의 기법 중 가장 성능이 좋은 MLLR 적응 기법의 경우 전체 잡음 환경에 대한 평균 WER이 15.94 %인데 비하여 제안한 모델 적응 기법은 13.41 %를 나타내어 15.87 %의 상대 향상률을 나타냈다. 오염 함수 예측을 위해 사용한 훈련 데이터가 Music 잡음 환경에서 발생하는 잡음 오염 과정을 충분히 반영하지 못한 것으로 판단된다.
V. 결 론
본 논문에서는 잡음 환경에서 효과적인 음성인식을 위하여 DNN 기반의 잡음 오염 함수 예측을 이용한 음향 모델 적응 기법을 제안하였다. 깨끗한 음성과 잡음 정보를 입력으로 하고 오염된 음성에 대한 특징 벡터를 출력으로 하는 DNN을 학습하여 비선형 관계를 갖는 잡음 오염 함수를 예측하였다. 예측된 잡음 오염 함수를 음향모델의 평균 벡터에 적용하여 잡음 환경에 적응된 음향 모델을 생성하였다. Aurora 2.0 데이터를 이용한 음성 인식 성능 평가에서 본 논문에서 제안한 모델 적응 기법이 기존의 전처리, 모델 적응 기법에 비해 일치, 불일치 잡음 환경에서 모두 평균적으로 우수한 성능을 나타냈다. 특히 불일치 잡음 환경에서 평균 오류율이 15.87 %의 상대 향상률을 나타냈다. 이러한 결과는 제안한 DNN 기반의 잡음 오염 함수 예측 기법이 음성의 잡음 오염 과정의 비선형성을 효과적으로 모델링함을 입증한다.
