

I. 서 론
II. 능동 소음 제어 알고리즘 및 하드웨어 구성
2.1 능동 소음 제어 알고리즘
2.2 하드웨어 구조
III. 하드웨어 구현 및 소프트웨어 최적화
3.1 하드웨어 구현
3.2 소프트웨어 최적화
IV. 결 론
I. 서 론
능동 소음 제어의 원리는 오래 전에 제안되었으나 이를 구현할 수 있는 기술적인 뒷바침이 되지 않아 구현의 어려움을 겪다가 최근 반도체 기술 및 디지털 신호 처리 기술의 발달에 힘입어 구현이 가능해지면서 여러 분야에서 활용되고 있다.[1-3] 특히, 소음 제어 헤드폰에 적용되어 상업적으로 큰 성공을 거두었으며, 최근에는 능동 소음 제어 기술을 적용한 자동차들이 점점 늘어 나는 추세이다.[4,5] 능동 소음 제어를 위한 대표적인 알고리즘으로는 LMS(Least Mean Square) 알고리즘을 변형한 Filtered-x LMS(FxLMS)가 널리 사용된다. 또한 최근에는 2차 경로로 인한 지연에서 기인하는 성능 저하를 개선한 MFxLMS(Modified Filtered-x Least Mean Square)가 제안되었으며, 연산량 증가에도 불구하고 개선된 안정성과 수렴 속도 향상으로 인하여 주목을 받고 있다.[6] 또한 단일 채널 능동 소음 제어의 단점인 좁은 정숙 영역을 넓히기 위해 다채널 능동 소음 제어를 고려하게 되었는데, 이를 위하여 단일 채널 FxLMS을 확장한 다채널 FxLMS 또는 다채널 MFxLMS이 제안되었다.[1,5]
앞서 능동 소음 제어 기술의 상업적 활용이 활발해졌다고 언급하였으나, 이는 예전에 비하여 상대적으로 활발해졌을 뿐이며, 사실은 아직도 많은 기술적 제약으로 인하여 능동 소음 제어 기술의 상업적 활용은 초기 단계라고 할 수 있다. 능동 소음 제어가 상업적 활용에 어려움을 겪는데에는 크게 두 가지의 이유가 있다. 그 첫 번째가 현재의 능동 소음 제어 기술의 근본적인 약점인 좁은 정숙 영역 문제이다. 지금까지 알려진 대부분의 능동 소음 제어 알고리즘들의 정숙 영역은 잡음의 주파수에 따라서 다르기는 하지만 에러 마이크를 중심으로 수 cm ~ 수십 cm 정도에 불과하다.[7] 따라서 이러한 제약이 허용되는 응용에서만 적용이 가능하다. 능동 소음 제어 기술이 헤드폰에 성공적으로 적용된 이유도 헤드폰 응용의 경우, 정숙 영역이 헤드폰 내부 정도만 되어도 충분하기 때문이다. 자동차의 경우에는 자동차 실내가 비교적 넓은 편이나 자동차에 장착된 여러 개의 스피커와 다채널 능동 소음 제어 기술을 이용하여 정숙 영역을 확장할 수 있기 때문에 상업적 적용이 가능하였다. 이와 같이 현재의 능동 소음 제어 기술은 해당 응용이 적절한 조건을 갖추었을 때만 적용 가능하다고 할수 있다. 두 번째 이유로는 경제적인 문제이다. 그동안 소음 제거는 흡음제 등을 이용한 차폐 방식을 주로 사용해 왔으며 비용 상승이 크지 않았다. 반면, 능동 소음 제어 기술은 복잡한 장치를 필요로 한다. 연산을 위한 CPU(Central Processing Unit), 신호 변환을 위한 A/D(Analog to Digital), D/A(Digital to Analog) 변환기, 신호 조절을 위한 아날로그 장치, 마이크, 스피커등 상당히 많은 장치를 필요로 한다. 이는 수동적인 소음 제거 시와는 비교도 할 수 없을 만큼의 비용 상승을 초래하기 때문에 상업적 활용에 제약 요소로 작용하고 있다.
본 논문에서는 앞서 언급한 능동 소음 제어 기술의 상업적 활용을 활성화 하기 위한 방안으로 저가의 MCU(Microcontoller Unit)를 이용한 다채널 능동 소음 제어기의 효율적인 구현 방안을 제시하고자 한다. 단일 채널 능동 소음 제어 방식의 제한을 극복하고 활용도를 높이기 위해서는 다채널 구현이 필요한데, 이를 위해서는 고가의 고성능 CPU와 주변 장치들이 필요하다. 본 논문에서는 최대한 MCU에 포함된 주변 장치를 활용하여 추가 장치에 소요되는 비용을 최소화하고, 부족한 성능의 CPU를 보완하기 위하여 병렬 처리 기법을 도입하여 경제적으로 저렴한 다채널 능동 소음 제어기 구현 방안을 제시 하였다.
논문의 구성은 다음과 같다. 2장에서는 구현에 적용된 정규화된 다채널 MFxLMS 알고리즘과 사용한 MCU의 구성에 대하여 소개하고, 3장에서는 2장에서 소개한 알고리즘을 저가의 MCU를 이용하여 효율적으로 구현하는 기법과 최종 동작 결과를 설명하고 4장에서 결론을 맺는다.
II. 능동 소음 제어 알고리즘 및 하드웨어 구성
2.1 능동 소음 제어 알고리즘
Fig. 1은 본 구현에서 사용한 MFxLMS 알고리즘의 블록도를 보여준다. Fig. 1을 보면 기존의 FxLMS와 달리 2차 경로의 지연을 보상하기 위해 기존의 LMS 알고리즘처럼 원하는 신호 을 생성하여 사용한다. Fig. 1은 단일 채널의 경우인데 이를 다채널로 확장하면 아래와 같은 다채널 MFxLMS 알고리즘을 얻을 수 있다.[1,6] 다채널 확장을 위하여 J개의 참조 마이크, K개의 제어 스피커, M개의 오차 마이크를 사용하는 J × K × M 다채널 능동 소음 제어 시스템을 고려하였다.
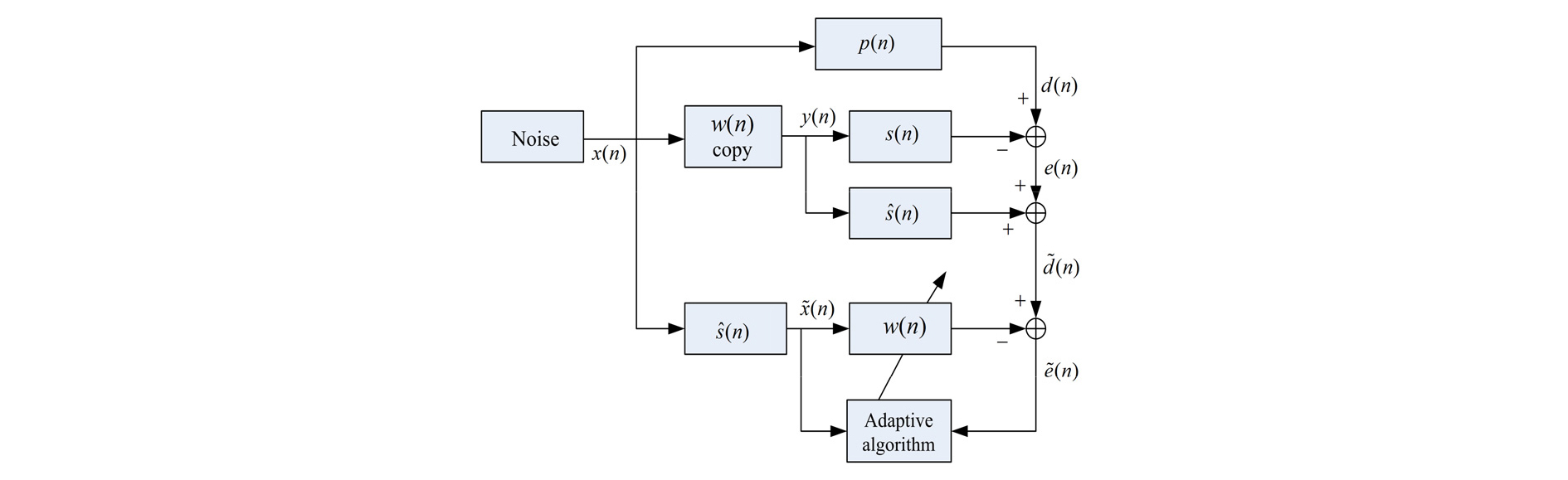
1단계: k번 째 제어 스피커의 출력 을 계산한다.
| $$y_k(n)=\sum_{j=1}^J\boldsymbol w_{\mathbf k\boldsymbol,\mathbf j}^{\mathbf T}(n){\boldsymbol x}_j(n),\;\;k=1,2,\dots,K,$$ | (1a) |
| $${\boldsymbol w}_{k,j}(n)=\lbrack w_{k,j,0}(n)w_{k,j,1}(n)\;\cdots\;w_{k,j,L-1}(n)\rbrack^T,$$ | (1b) |
| $${\boldsymbol x}_j(n)=\lbrack x_j(n)\;\;x_j(n-1)\;\;\cdots\;\;x_j(n-L+1){\rbrack^T,}$$ | (1c) |
여기서 는 j 번째 참조 마이크를 통해 들어온 입력이고 는 j 번째 참조 마이크 입력과 l 번째 오차 마이크 신호 입력에 기반하여 k 번째 제어 스피커 신호 생성을 위한 적응 필터 계수이다.
2단계: 입력 신호가 추정된 2차 경로를 통과한 신호를 계산한다.
여기서 는 k 번째 제어 스피커와 m 번째 오차 마이크 사이의 전달 함수의 추정치이다.
3단계: 와 를 이용하여 가상의 원하는 신호를 계산한다.
| $$\begin{array}{l}{\widetilde d}_m(n)=e_m(n)+\sum_{k=1}^K{\widehat s}_{m,k}(n)\ast y_k(n),\;\;m=1,\;2,\dots,M\\\end{array}$$ | (3) |
여기서 는 m 번째 오차 마이크로 들어온 입력이다.
4단계: 을 이용하여 가상의 오차 신호 를 계산한다.
5단계: 오차 신호 가 주어졌으므로 를 입력 신호로 하여 일반 다채널 LMS 알고리즘처럼 계산할 수 있다.
여기서 µ는 수렴 속도를 조절하는 수렴 인자이다.
6단계: 본 구현에서는 5 단계의 고정 수렴 인자를 가지는 알고리즘이 아닌 비정상 신호에 대하여 개선된 안정성을 보이는 정규화된 다채널 MFxLMS 알고리즘을 적용하였다.[8]
J, K, M이 증가할수록 연산량이 급속히 증가함을 알 수 있다. 실질적인 연산량이 어느 정도나 되는지와 이를 저가의 MCU에서 어떻게 효율적으로 구현할지에 대해서는 다음 장에서 설명한다.
2.2 하드웨어 구조
저가의 시스템으로 구현하기 위해서 가장 중요한 것은 적절한 MCU의 선택이다. 두 가지 조건을 충족해야 한다. 첫째, Eq. (6)을 수행할 수 있을 정도의 연산 능력을 보유해야 하며, 두 번째로는 추가의 장치를 최소화하기 위하여 다채널 능동 소음 제어기 구현에 필요한 주변 장치들을 내장하고 있어야 한다. 본 연구에서는 이에 적합한 MCU로서 Texas Instruments 사에서 나온 저가의 MCU인 TMS320F280049를 채택하였다.[9] Fig. 2는 본 구현에서 필요한 부분만을 포함한 TMS320F280049의 블록도이다.
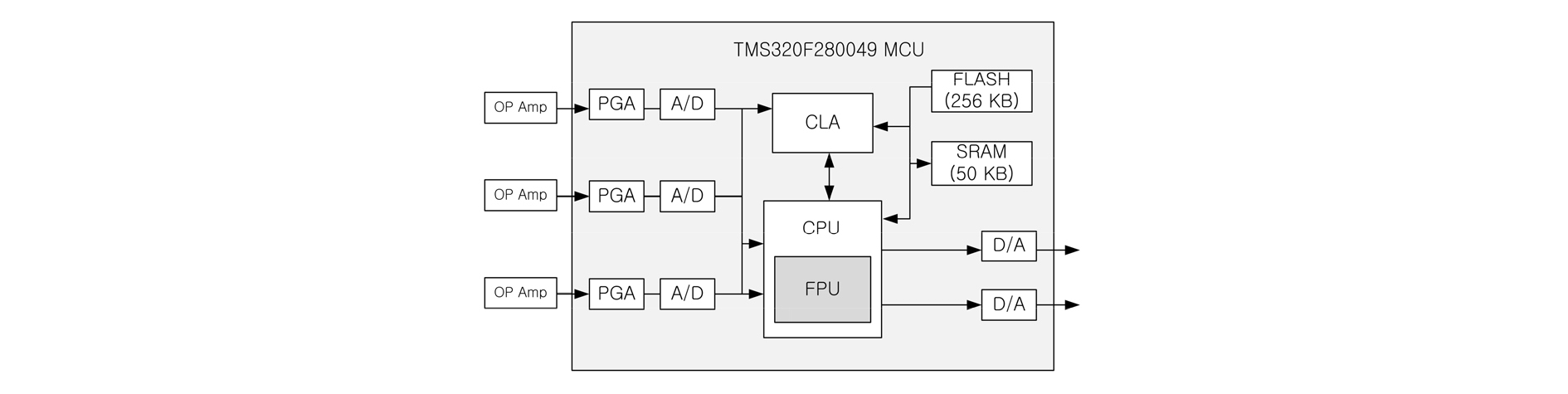
우선 앞서 언급한 연산 능력과 관련하여 TMS320F280049의 성능을 살펴보면, 100 MHz로 동작하기 때문에 기본적으로 100 MIPS의 처리 능력을 보유하고 있다. 사실, TMS320F280049는 과거에는 C2000 계열의 DSP(Digital Signal Processor)로 분류됬던 만큼, 디지털 신호 처리에 적합한 연산 기능을 보유하고 있다. 과거 C2000 계열은 고정소수점 연산 방식의 DSP였으나 TMS320F280049는 FPU(Floating Point Unit)를 내장하고 있기 때문에 부동소수점 DSP로 볼 수 있다. DSP가 갖추어야 하는 zero overhead loop 기능이나 단일 싸이클 MAC(Multiply- Accumulate) 연산 기능이 포함되어 있기 때문에 FIR(Finite Impulse Response) 필터류의 연산에 최적화 되어 있다. 따라서 부동소수점 연산 능력면에서 200 Mflops의 연산 능력을 보유하고 있다. 이는 일반적인 DSP 알고리즘을 수행하기에 적합한 성능이라고 할 수 있다. 그러나 다채널 MFxLMS 알고리즘의 경우, 연산이 상당히 많기 때문에 적응 필터 차수에 제약이 있을 수 있다. 본 논문에서는 이러한 부족한 연산 성능 문제를 해결하기 위해 코드 최적화와 병렬 처리 방안을 제안한다. Fig. 2의 블록도를 보면 CLA(Control Law Accellerator)라는 유닛이 존재하는데, 이 유닛을 통해 병렬 처리가 가능하다. CLA은 일종의 보조 FPU이다. 주 용도는 CPU를 보조하여 CPU의 연산 부담을 덜기 위해 사용된다. 예를 들어 센서를 통해 들어온 신호를 CPU가 본격적으로 처리하기 전에 CLA에서 사전 처리를 할 수 있다. 그러나 CLA의 용도가 특정되어 있는 것이 아니기 때문에 CPU와 독립적으로 범용 연산 장치로 사용 가능하다. CLA의 성능 역시 수치적으로는 200 Mflops이나 MAC 연산이 매우 제한된 상황에서만 사용할 수 있기 때문에 실질적으로는 100 Mflops라고 할 수 있다. 또한 CPU에 포함된 FPU와 달리 범용 레지스터가 4개, 보조 레지스터가 2개로 최소로만 제공되기 때문에 실제 구현 시에는 CPU에 포함된 FPU에 비하여 성능이 많이 떨어진다고 할 수 있다. 그러나 추가적으로 활용할 수 있는 독립적인 연산 유닛인 만큼 이를 이용하여 병렬 처리를 하게 되면 그 만큼 CPU의 연산 부담을 덜 수 있다. 3장에서 CLA를 이용한 병렬 처리가 성능을 얼마나 향상시키는 지에 대하여 살펴볼 것이다.
내장 주변 장치와 관련해서는 12 bit A/D 변환기 3개와 12 bit D/A 변환기 2개를 내장하고 있고 신호 조절을 위한 PGA(Programmable Gain Amplifier) 7개가 내장되어 있다. 이 모든 것이 내장되어 있지 않다면, 추가적으로 장착되어야 할 부품들이기 때문에 매우 유용한 주변 장치라 할 수 있다. A/D 변환기가 3개 그리고 D/A 변환기가 2개가 내장되어 있으므로 이를 통해 다채널 능동 소음 제어기를 구현할 수 있다. 본 구현에서는 J = 1, K = 2, M = 2구조의 다채널 능동 소음 제어기를 구현하였다. 즉, 참조 마이크 신호의 A/D 변환을 위하여 A/D 변환기 하나를 사용하고, 2개의 오차 마이크 신호들의 A/D 변환을 위하여 2개의 A/D 변환기를 사용하였다. 또한 2개의 제어 스피커 구동 신호의 D/A 변환을 위해 2개의 D/A 변환기를 사용하였다. PGA는 신호 조절을 위한 일종의 비반전 증폭기 구조를 가지는 OP 앰프다. 레지스터 설정을 통해 소프트웨어적으로 증폭도를 조절할 수 있고 캐패시터를 추가하면 RC 저역 필터를 구성할 수 있다. 다만, 그 외의 회로 구성은 불가능하기 때문에 이를 통해 충분한 감쇠 특성을 가지는 anti-aliasing 저역 필터를 구현할 수는 없다. 따라서 anti-aliasing 저역 필터의 구현을 위해서는 외부에 추가적인 OP 앰프가 필요하나, 내부의 PGA를 활용함으로 외부에 추가되는 OP 앰프의 수를 최소할 수 있었다.
III. 하드웨어 구현 및 소프트웨어 최적화
3.1 하드웨어 구현
2장에서 언급한 바와 같이 TMS320F280049 MCU는 다채널 능동 소음 제어기를 구현하기 위한 거의 대부분의 주변 장치를 내장하고 있기 때문에 만약 실험실에서처럼 장비를 통해 신호 조절이 별도로 이루어진다면 추가적인 하드웨어 없이, MCU 칩 하나, 즉 단일 칩으로 동작하는 다채널 능동 소음 제어기를 구현할 수 있다. 그러나, 상용 제품이 되기 위해서는 입출력 부분의 신호 조절을 위한 아날로그 회로 부분이 반드시 포함되어야 하고, 이 부분이 능동 소음기 제어기 동작에 전반적으로 영향을 미칠 수 있기 때문에 여러 요소를 고려하여 설계가 이루어져야 한다. 신호 조절은 A/D 변환기 입력단의 anti-aliasing 저역 필터와 D/A 변환기 출력단의 anti-imaging 저역 필터로 이루어진다. 이러한 저역 필터를 설계하기 위해서는 우선 능동 소음 제어기가 몇 Hz까지의 신호를 주요 제거 대상 신호로 할 것인가를 설정해야 하는데, 본 구현에서는 이를 1.5 kHz로 정하였다. 대부분의 능동 소음 제어기들이 주로 1 kHz 이하의 저주파 잡음 제거에 집중하고 있기 때문에 이 정도의 주파수를 대상으로 하는 것이면 충분하다고 판단하였다. 따라서 저역 필터의 3 dB 차단 주파수를 1.5 kHz로 설정하였다. 한편, 능동 소음 제어기 설계에 있어서 A/D 변환기의 선택 및 샘플링 주파수의 선택이 중요하다. 일반적으로 오디오 신호 처리에서 많이 사용되는 sigma-delta 변조 방식의 A/D 변환기는 샘플링 주파수 설정에 따른 anti-aliasing 저역 필터가 데시메이션 및 디지털 필터링을 통해 자동으로 이루어지므로 고주파 차단을 위한 간단한 RC 저역 필터 외에 별도의 anti-aliasing 저역 필터가 필요 없다는 장점이 있지만, 변환 시간이 수 msec에 달하기 때문에 일부 feedback 방식의 능동 소음 제어기를 제외하고는, 본 연구에서 구현하고자 하는 feedforward 방식과 같이 인과성을 요구하는 능동 소음 제어기에는 적합하지 않다(변환 시간이 긴 A/D 변환기를 사용하여 인과성이 보장되지 않는 경우에는 주기적인 소음의 제거만 가능하다). TMS320F280049 MCU는 변환 시간이 매우 짧은 SAR(Successive Approximation Register) 방식의 A/D 변환기를 내장하고 있기 때문에 능동 소음 제어기 구현에 적합하다고 할 수 있다. 실질적으로는 A/D 변환 시간과 변환된 신호의 처리가 개시되는데까지 걸리는 인터럽터 지연(latency) 시간의 합이 중요하기 때문에 짧은 인터럽터 지연 또한 중요하다. TMS320F280049 MCU는 A/D 변환기 사용 시, 인터럽터 지연을 최소화 할 수 있는 기능을 제공하고 있기 때문에 능동 소음 제어기 구현에 매우 적합하다고 할 수 있다.
적절한 샘플링 주파수의 설정은 능동 소음 제어기 설계에서 중요한 요소이다. 제거를 대상으로 하는 신호의 주파수를 1.5 kHz로 설정하였으므로 나이키스트 샘플링 주파수를 고려한다면, 샘플링 주파수를 3 kHz ~ 4 kHz로 설정하면 충분할 것이다. 하지만, 본 구현에서는 아래와 같은 이유로 훨씬 높은 샘플링 주파수를 선정하였다. 나이키스트 샘플링 주파수를 샘플링 주파수로 설정할 경우, 급격한 감쇠 특성을 구현하기 위해 아날로그 저역 필터의 차수가 매우 커지게 되고 이를 구현하기 위해 다수의 OP 앰프가 필요하게 된다. 따라서 다수의 추가 부품이 요구된다. 더구나 저역 필터의 높은 차수로 인해 그룹 지연이 크게 발생하게 되는데, 이는 feedforward 능동 소음 제어기에서는 바람직 하지 않다. 따라서 높은 샘플링 주파수를 적용할수록 낮은 차수의 저역 필터를 사용할 수 있고 이를 통해 그룹 지연이 적은 저역 필터를 구현할 수 있다. 본 구현에서는 샘플링 주파수로 10 kHz를 선택하였다. 8 kHz도 적당하다고 판단하였으나 적은 차수의 저역 필터로도 anti-aliasing 잡음과 그룹 지연을 최소화하기 위해 10 kHz를 선택하였다. 다만, 높은 샘플링 주파수로 인하여 증가되는 연산량의 증가는 소프트웨어 최적화를 통해 해결해야 할 문제이며 이와 관련해서는 소프트웨어 최적화 부분에서 설명한다.
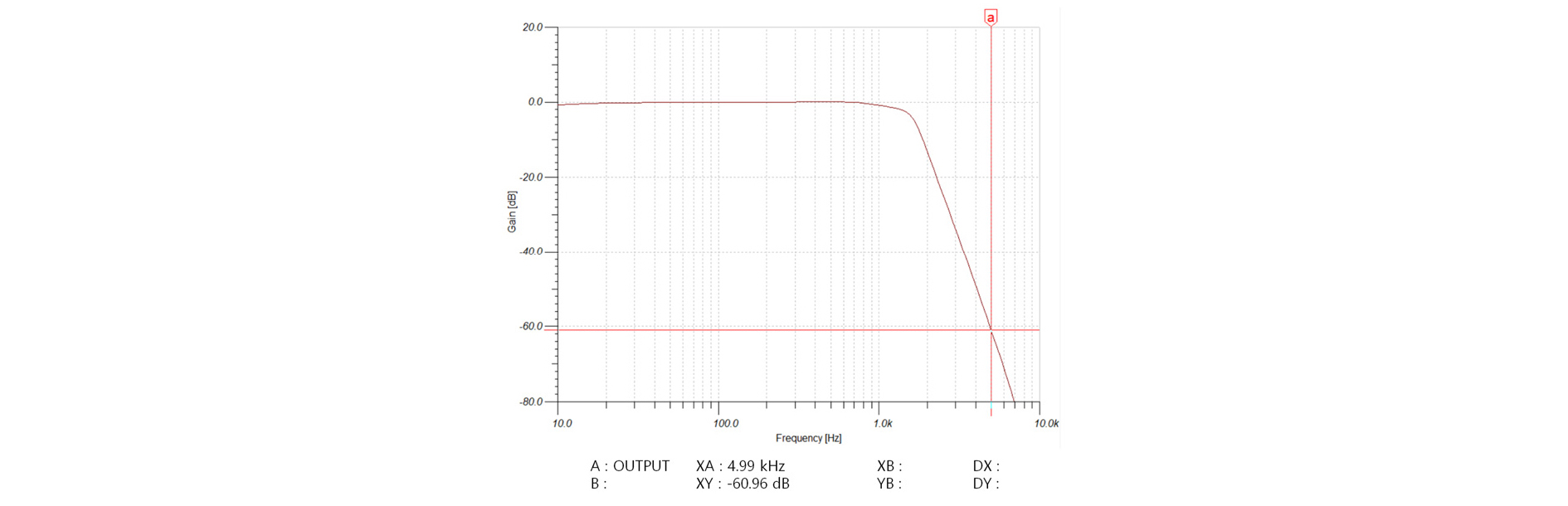
Fig. 3은 A/D 변환을 위한 anti-aliasing 저역 필터 회로이다. 저역 필터로는 4차의 Chebyshev 저역 필터를 채택하였으며 Sellen-Key 방식으로 구현하였다. 4차의 능동 필터를 구현하기 위해서는 2개의 OP 앰프가 필요하기 때문에 구현 시에는 2개의 OP 앰프를 내장하고 있는 OPA2340를 사용하였다. 따라서 3개의 A/D 변환을 위해 3개, 2개의 D/A변환을 위해 2개, 총 5개의 OPA2340를 사용하였다. 또한 추가적인 감쇠를 얻기 위하여 각각 단마다 RC 필터를 추가하였다. 한편, Fig. 3을 살펴보면 OP 앰프가 4개인데 이 중 뒤의 2개는 TMS320F280049에 내장된 PGA이다. 내장된 PGA 2개를 연결하여 2단 증폭을 하도록 하였다. PGA를 이용한 회로 구성은 단순히 증폭 회로로 제한되기 때문에 증폭 기능 만을 담당한다. 다만, 외부 단자에 캐패시터를 연결하면 내장된 저항을 이용하여 RC 필터를 추가할 수 있기 때문에 RC 필터를 추가하여 저역 필터의 추가 감쇠 특성을 얻도록 하였다. 따라서 외부의 OP 앰프는 증폭도 1의 4차 저역 필터 기능만 담당하고 내부의 PGA가 마이크 프리앰프 역할을 담당한다. PGA는 Fig. 3의 R1, R2, R3, R4 저항값 설정을 통해 3 ~ 24배까지 증폭할 수 있기 때문에 2단 증폭의 경우 9 ~ 576배까지 증폭할 수 있으므로 미약한 마이크 신호를 증폭하기에 충분하다 또한 여러 가변적인 상황에서 잡음의 크기에 따라서 마이크의 증폭도를 조절해야 할 경우 소프트웨어적으로 설정할 수 있기 때문에 외부 회로를 변경하거나 가변 저항을 사용할 필요가 없다. Fig. 4는 anti-aliasing 저역 필터의 주파수 특성을 보여 준다. Anti-aliasing 성능을 보기 위하여 PGA의 증폭도를 1로 가정한 주파수 특성이다. 그림에서 보듯이 5 kHz 부근에서 약 61 dB의 감쇠가 일어남을 알 수 있다.
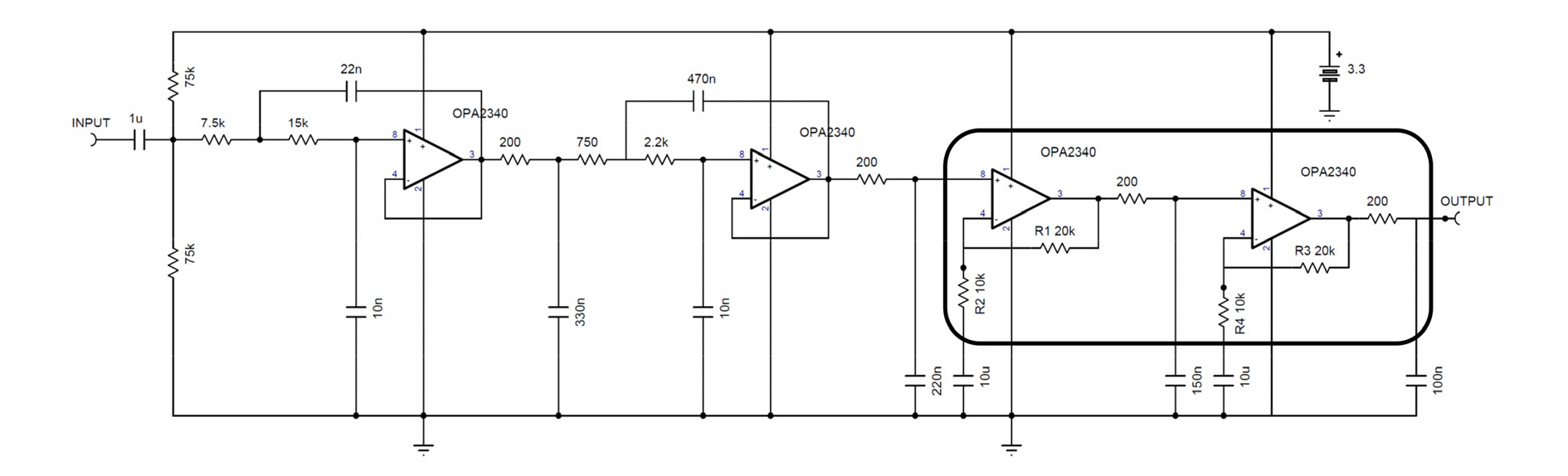
한편, D/A 출력단을 위한 anti-imaging 필터의 경우에는 증폭 기능 없이 4차 저역 필터 기능만을 하도록 하였다. A/D 입력단의 증폭과 달리 D/A 출력단은 스피커를 구동하는 파워 증폭이 필요하기 때문에 이를 내장하는 것은 적당하지 않다. 응용에 따라서 제거하고자 하는 소음이 크다면 수십와트 이상의 파워 증폭이 필요할 수도 있기 때문에 파워 증폭기는 별도로 사용하였다. 본 연구에는 증폭기를 내장한 액티브 스피커를 사용하였기 때문에 별도의 파워 앰프를 사용하지는 않았다.
3.2 소프트웨어 최적화
본 구현에서 수행한 소프트웨어 최적화 과정을 설명하기 전에 우선 2.1절에서 설명한 다채널 MFxLMS 알고리즘의 연산량을 살펴볼 필요가 있다. 연산량이 Table 1에 나와 있다. Table 1은 단계별 계산에서 필요하거나 이전 단계 이후에 추가된 연산량의 정도를 소요 곱셈의 수로 보여준다. 최종 알고리즘으로는 6단계의 정규화된 다채널 MFxLMS 알고리즘을 사용하였기 때문에 5단계는 생략하였다.
Table1. The number of multiplications of the multi-channel MFxLMS algorithm.
한편, 6단계에서의 분모 부분은 직접 계산하지 않고 다음과 같은 연산을 통하여 연산량을 줄였다.
샘플링 주파수를 10 kHz로 설정했으므로 실시간 처리를 위해서는 모든 연산이 100 µsec 내에 수행이 되어야 한다. TMS320F280049 MCU의 대부분의 명령어들이 단일 싸이클에 수행이 되기 때문에 이는 대략 10,000개의 명령어를 수행할 수 있는 시간에 해당한다. Table 1의 연산량은 단지 곱셈만을 고려한 것이기 때문에 덧셈과 메모리 읽기 쓰기, 조건 판별, 분기 등의 모든 명령어들을 포함한다면 단순히 C 컴파일러가 생성한 코드가 실시간으로 동작할 수 있다고 장담하기 어려운 정도의 연산량이라고 할 수 있다.
Table 2는 본 연구에서 수행한 소프트웨어 최적화 과정을 통하여 실시간으로 감당할 수 있는 연산량의 정도를 실험한 결과를 보여주고 있다. 감당할 수 연산량의 정도는 실시간 동작이 가능한 적응 필터의 차수로 측정하였다. 즉, 적응 필터의 차수를 늘려가면서 정상 동작하는 최대 차수를 확인하는 방법을 통하여 적용된 최적화가 얼마나 효과가 있는지를 확인하였다. 실험을 위하여 2차 경로의 차수는 80으로 고정하였다. 2차 경로의 경우, 추정치를 사용하게 되는데, 어느 정도까지만 추정을 해도 MFxLMS 알고리즘이 안정적으로 동작하는데 영향을 주기 않기 때문에 2차 경로 의 뒷 부분 잔향에 해당하는 작은 값들은 0으로 대치하여 2차 경로의 차수를 줄인다.[10] 반면 MFxLMS 알고리듬의 성능은 주로 적응 필터의 차수에 영향을 받기 때문에 적응 필터의 차수를 기준으로 최적화 정도를 확인하였다. 최적화를 수행하기 전에 비교를 위하여 최적화를 수행하지 않은 baseline 코드의 성능을 측정하였다. Baseline 코드의 경우에는 적응 필터 차수 L이 L = 98 까지만 실시간 동작했다. Baseline 코드이므로 특정 MCU나 특정 개발 툴에 특화되어 작성된 부분은 없으나, 기본적으로 C 언어를 이용하여 최대한 효율적으로 작성하였으며, 컴파일할 때 컴파일러가 제공하는 최적화 레벨을 최대로 하여 가장 속도가 빠른 코드가 생성되도록 하였다.
Table 2. The maximum number of filter taps for real-time operation at each optimization stage.
첫 번째 최적화와 두 번째 최적화는 CLA를 활용하지 않고 오로지 CPU만을 이용한 최적화이다. 첫 번째 최적화는 MAC 연산 최적화이다. TMS320F280049 MCU는 단일 싸이클 MAC 연산을 지원한다. 만약 어셈블리 프로그래밍을 한다면 여러 상황에서 단일 싸이클 MAC 연산 기능을 활용할 수 있지만, 컴파일러를 이용할 경우, 컴파일러가 제한된 상황에서만 단일 싸이클 MAC 연산 명령어를 이용하여 코드를 생성하기 때문에 어떤 조건에서 단일 싸이클 MAC 코드가 생성되는지를 알아야 한다. 아래 코드는 MAC 연산을 이용하는 반복문 C 코드의 일부분이다.
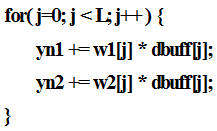
위의 코드는 매우 정상적인 코드이나 TMS320F280049 MCU에서는 효과적인 코드가 아니다. 위의 코드는 다음과 같이 작성되었을 때 단일 싸이클 MAC 연산 기능을 활용하여 컴파일이 된다.
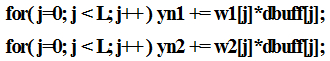
일반적인 C 코드 관점에서 볼 때, 두 번째 코드가 두 번의 반복문을 사용하기 때문에 loop overhead가 더 크고, 따라서 비효율적인 코드라고 할 수 있다. 그러나 TMS320F280049 MCU에서는 두 번째 코드의 각각의 반복문은 아래와 같이 zero overhead loop의 단일 싸이클 MAC 어셈블리 명령어를 이용하여 컴파일 된다.
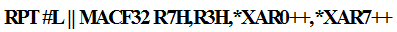
위의 어셈블리 코드는 L 싸이클이 소요된다. 매 싸이클마다 곱하기, 더하기, 두 개의 메모리로부터 읽기, 다음 메모리 읽기를 위해 두 개의 포인터 증가가 수행된다. 즉, 개별 연산으로 따졌을 때 6개의 연산이 한 싸이클에 수행된다. 반복문 준비를 위해 8 싸이클이 필요하기 때문에 하나의 반복문을 실행하는데 소요되는 싸이클 수는 L + 8이다. 따라서 총 실행 싸이클 수는 2L + 16이다. 반면, 첫 번째 코드의 경우, 컴파일러가 생성한 코드는 단일 싸이클 MAC 명령어를 활용하지 못하였고, 실제 실행 싸이클 수는 8L + 9였다. 4배 정도 더 많은 시간이 소요되었다. Eqs. (1) ~ (6)을 살펴보면 MAC 연산이 상당히 많은 부분은 차지 하고 있으므로 해당 부분을 모두 두 번째 반복문 코드와 같이 수정하여 실험을 하였다. 실시간 가능한 최대 적응 필터 차수는 L = 204였다. 성능이 상당히 향상됨을 알 수 있다.
한편, Eqs. (1) ~ (6)에 포함된 대부분의 연산을 실제 C 코드로 구현할 때, 지연 메모리의 데이터를 이동시키는 연산이 수반된다. 한 예로, 아래 코드는 전형적인 적응 필터 연산 과정을 보여준다.
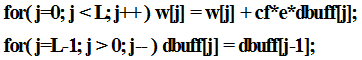
여기서 w[j]는 적응 필터 계수이고, dbuff[j]는 입력이 저장되는 지연 메모리이다. 하드웨어가 circular addressing을 지원하고 어셈블리 언어로 작성한다면 명시적 메모리 이동 없이 작성하는 것이 가능하지만, C 코드로 작성할 때에는 위와 같이 별도로 메모리 이동을 해주어야 한다. L개의 메모리를 이동시킨다면 메모리로부터 레지스터로 데이터를 읽어오고, 읽어온 데이터를 메모리에 쓰고, 루프 카운터를 증가시키는 최소 3번의 연산을 필요로 한다. 따라서 3L 정도의 연산이 수반된다. 오히려 단일 싸이클 MAC 연산보다도 많은 연산량을 요구한다. 따라서 본 구현에서는 메모리 연산을 별도로 수행하지 않고 적응 필터 연산을 수행하는 방식을 제안하였다. 위의 C 코드를 그대로 구현하는 기존의 방식은 Fig. 5와 같다.
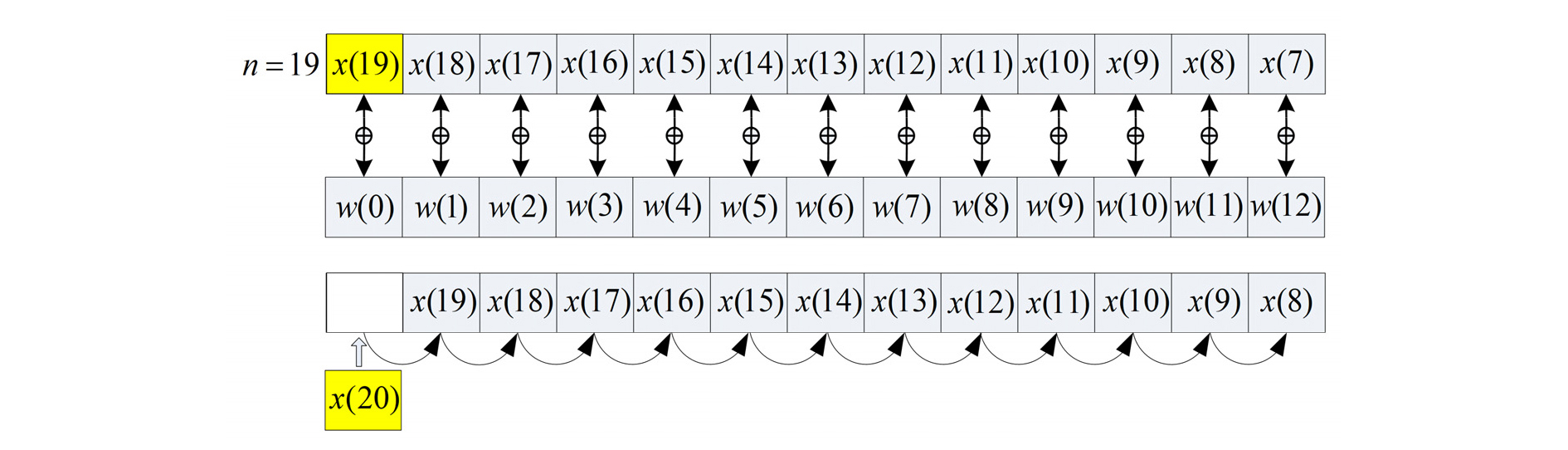
Fig. 5는 L = 13이고 현재의 시간 인덱스가 n = 19인 경우를 보여 주고 있다. 적응 필터 계수 w[j]를 갱신한 후, 지연 메모리 dbuff[j]를 Fig. 5와 같이 모두 이동 시켜준다. Fig. 5에서 ⊕ 기호는 적응 필터 갱신 연산을 의미한다. 그리고 n = 20에 입력된 새로운 입력 데이터는 지연 메모리의 맨처음에 저장된다. 위의 그림은 적응 필터 갱신뿐만 아니라, 일반 FIR 필터 연산에도 해당 되는데 그 경우에는 ⊕ 기호는 MAC 연산을 의미한다. 본 논문에서 제안된 방식은 지연 메모리 이동을 제거하기 위하여 하나의 반복문을 두 개의 반복문으로 나눈다. 그리고 지연 메모리에 최근 입력 데이터를 저장할 때, 기존 데이터들의 이동 없이 저장 위치를 현재 위치에서 하나씩 감소 시키면서 저장을 한다.
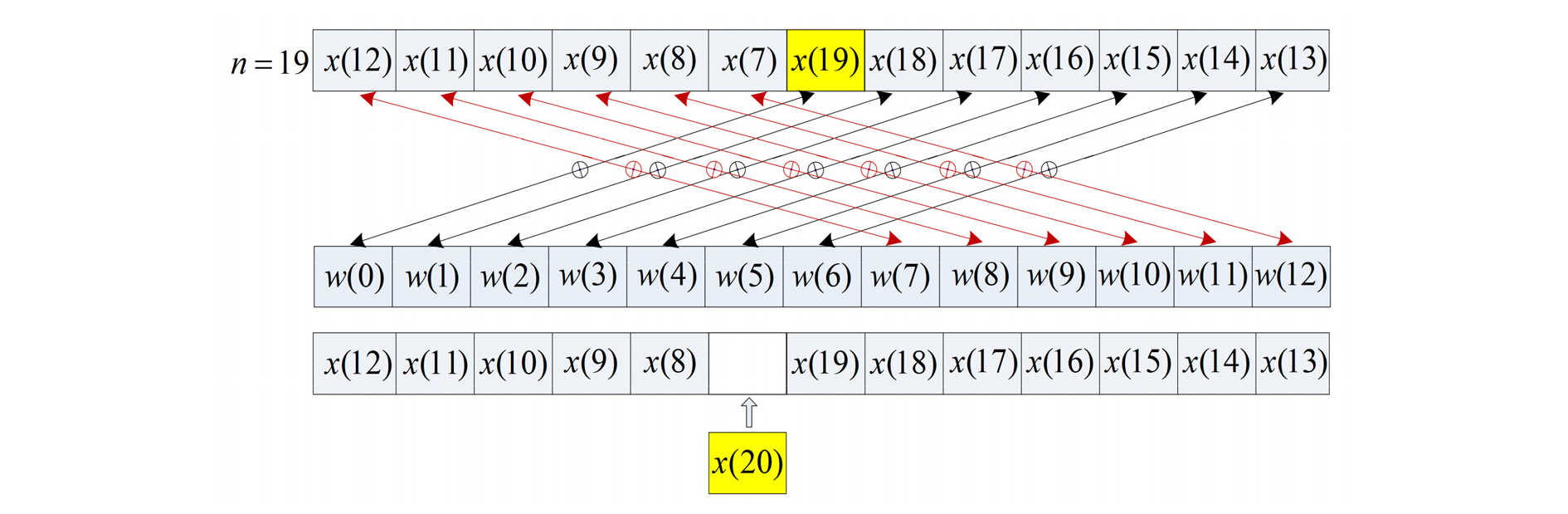
Fig. 6에서 도식적으로 설명하고 있다. Fig. 6에서 검은 선에 해당하는 연산을 위해 한 번의 반복문, 그리고 빨간 선에 해당하는 연산을 위해 또 한 번의 반복문을 수행한다. 이렇게 두 번의 반복문을 수행하면, Fig. 5와 동일하게 적응 필터 계수를 갱신한다. 그리고 Fig. 5와 달리 지연 메모리 내용의 이동 없이 n = 20에 새로 입력된 데이터는 Fig. 6에서처럼 현재 위치에서 하나 왼쪽에 저장되고, 제일 오래된 입력된 데이터를 덮어 쓰게 된다. 이렇게 하여 지연 메모리의 맨처음까지 도달하게 되면 다시 지연 메모리의 맨 마지막으로 돌아가 입력 데이터를 저장하게 된다. 비록 하나의 반복문을 두 번에 걸쳐 계산하므로 약간의 오버헤드가 발생하기는 하지만, 두 반복문의 루프 카운터의 합은 Fig. 5에 해당하는 루프 카운터와 같다. 단일 싸이클 MAC 연산을 이용하면, 두 번의 반복문을 사용할 경우에는 단일 반복문을 사용할 때에 비하여 반복문을 준비하는데 걸리는 8 싸이클의 오버헤드가 더 추가될 뿐이다. 그외에 지연 메모리에서의 새로운 저장 위치에 해당하는 포인터 갱신과 두 반복문의 루프 카운터 갱신과 같은 약간의 부수적인 연산이 추가 된다. 위와 같이 지연 메모리 이동을 최적화했을 경우 실시간 가능한 최대 적응 필터 차수는 L = 309였다. 단일 싸이클 MAC 연산 최적화만큼이나 최적화 효과가 있음을 알수 있다.
다음은 앞서 언급한 CLA를 이용하여 병렬 처리를 함으로써 연산 최적화를 수행 하는 부분에 대하여 설명한다. Eq. (1)과 Eq. (2)를 살펴보면, A/D 변환된 입력 신호 이 입력되면 이를 이용하여 계산을 하고 있다. 따라서 Eq. (1)과 Eq. (2)는 동시에 계산될 수 있기 때문에 Eq. (1)은 CPU에서, Eq. (2)는 CLA에서 동시에 계산하도록 할 수 있다. Eq. (2)에서 계산한 이 Eq. (4)에서 사용되기 때문에 CLA는 Eq. (2)를 CPU가 Eq. (1)과 Eq. (3)의 계산을 마치기 전에 계산해 놓으면 된다. Fig. 7에 CLA를 이용한 병렬 처리 과정이 나와 있다.
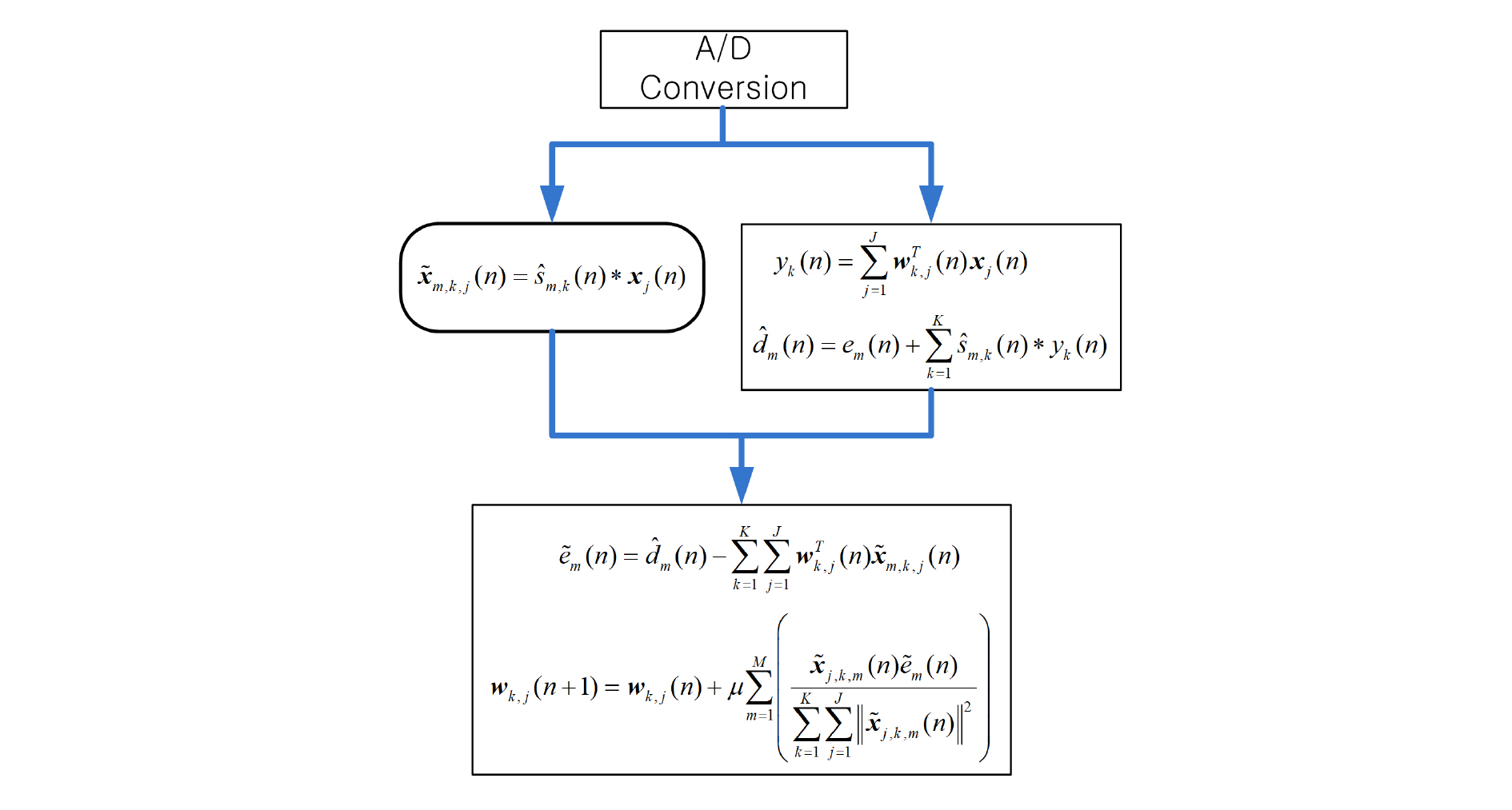
그림에서 둥근 사각형은 CLA에서 수행되는 연산을 의미한다. 비록 CLA의 연산 속도가 느리기는 하지만, Eq. (2)의 연산량이 Eqs. (1)과 (3)을 합친 연산량보다 충분히 작기 때문에 CLA의 연산이 먼저 종료된다. 따라서 Fig. 7과 같이 병렬 처리 하면, CLA의 연산이 먼저 종료되기 때문에 CPU만을 이용하여 연산할 때의 소요 시간보다 Eq. (2)의 연산 시간만큼을 절약할 수 있다. 이렇게 CLA를 이용하여 병렬 처리할 경우, 실시간 가능한 최대 적응 필터 탭 수는 L = 352였다.
한편, Eqs. (1) ~ (4)를 살펴보면, Eq. (1)과 Eq. (2)가 종료되어 와 이 얻어지면 Eq. (3)과 Eq. (4)가 동시에 연산 가능하다는 것을 알 수 있다. 이 과정이 Fig. 8에 나와 있다.
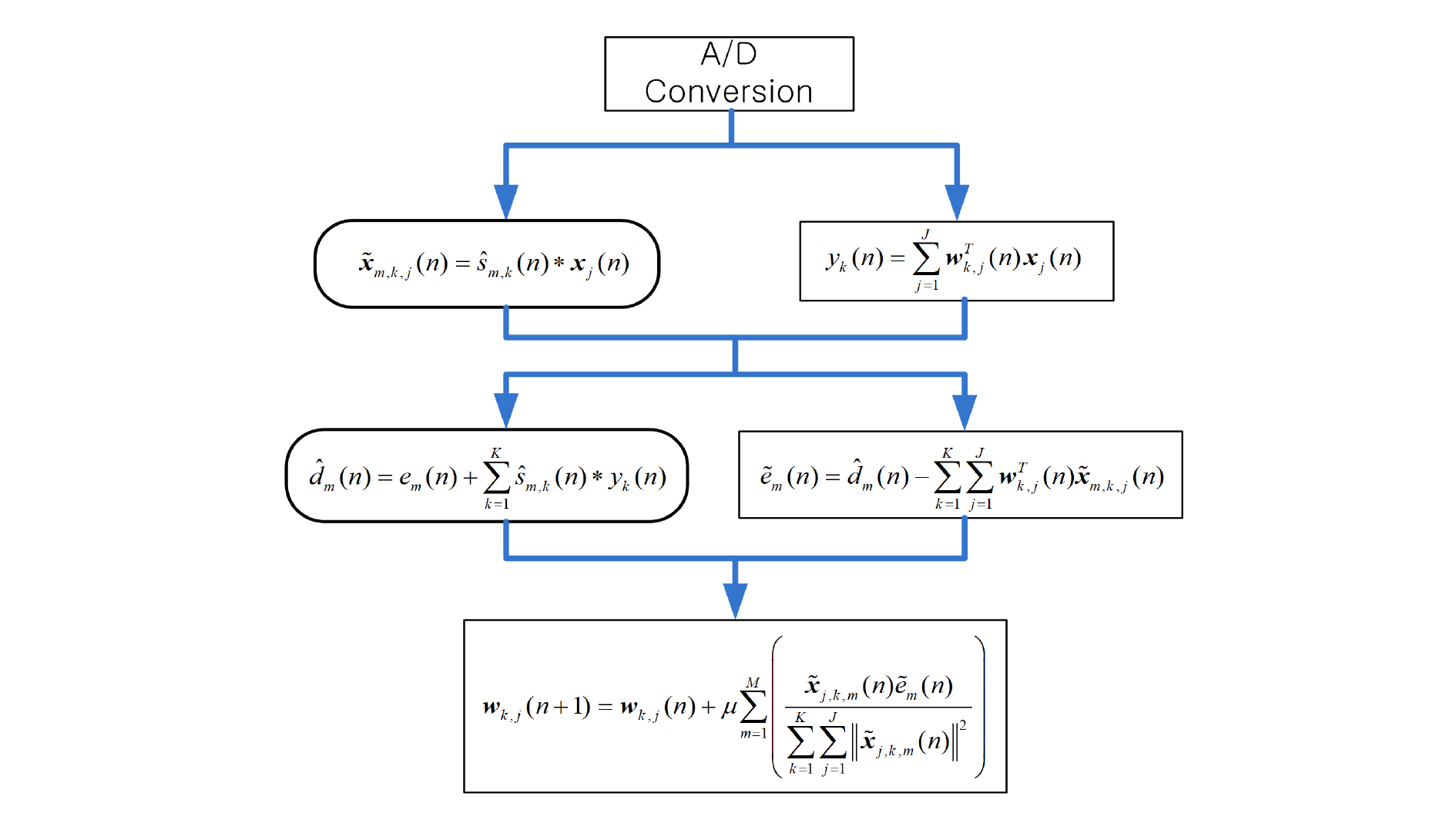
이렇게 두 번에 걸쳐 병렬 처리를 하면 Eq. (2)와 Eq. (3)의 연산을 CLA가 담당하므로 CPU 만으로 연산할 때보다.그 만큼 연산 시간을 절약할 수 있을 것이다. 그러나 실제로는 Eq. (2)만을 CLA가 담당할 때보다 시간이 절약되지 않았다. 그 이유는 CLA의 연산 성능이 CPU에 비하여 훨씬 낮기 때문에 Eq. (2)와 Eq. (3)에 대한 CLA의 연산 소요 시간이 Eq. (1)과 Eq. (4)에 대한 CPU의 연산 소요시간 보다 거의 두 배 가까이 소요됬기 때문이다.
Fig. 9는 CLA가 Eq. (2)를 수행하고 CPU가 Eq. (1)을 동시에 수행할 때의 소요 시간을 오실로스코프로 본 것이다. 그림을 보면 CLA의 수행 시간이 CPU보다 훨씬 많이 걸린다는 것을 알 수 있다. CLA를 이용한 병렬 처리 1단계에서처럼 Eq. (2)만을 CLA에서 처리할 경우에는 CPU가 Eq. (1)과 Eq. (3)을 연산하는 것보다 먼저 처리되었기 때문에 문제가 없었지만, 이제는 CLA가 수행하는 Eq. (2)가 CPU가 실행하는 Eq. (1)보다 일찍 끝나야하고, CLA가 수행하는 Eq. (3)이 CPU가 실행하는 Eq. (4)보다 일찍 끝나야 CLA를 이용한 병렬 처리로부터 이득을 얻을 수 있다. 따라서 병렬 처리 이득을 얻기 위해서는 CLA가 담당하는 연산의 속도를 향상시켜야 한다. 이미 C 언어 기반에서 수행할 수 있는 최적화는 어느 정도 적용이 되었기 때문에 속도를 향상시킬 수 있는 유일한 방법은 어셈블리 프로그래밍을 통하여 최적화하는 것이다. 어셈블리 프로그램밍은 개발 기간이 길어지고 코드 관리의 어려움으로 인해, 불가피한 경우가 아니면 잘 수행되지 않지만 속도 향상을 위해 꼭 필요한 경우, 부분적으로 수행이 된다. 특히 CLA의 경우는 CPU와 동일 클럭으로 동작하기는 하나, 보조적인 연산 장치이기 때문에 CPU와 달리 프로그래밍에 매우 제약이 많다. 특히, CPU에 비해 1/3도 되지 않는 레지스터의 수는 컴파일러 사용 시 매우 비효율적인 코드가 생성되는 요인이다. 따라서, 어셈블리 프로그래밍을 할 경우, 컴파일러가 생성하는 코드보다 훨씬 향상된 코드를 작성할 수 있을 것으로 예상되므로 어셈블리 프로그래밍을 수행하였다. 그 결과, 컴파일러가 생성하는 코드보다 약 2배 빠른 코드를 작성할 수 있었고 그 결과가 Fig. 10에 나와 있다.
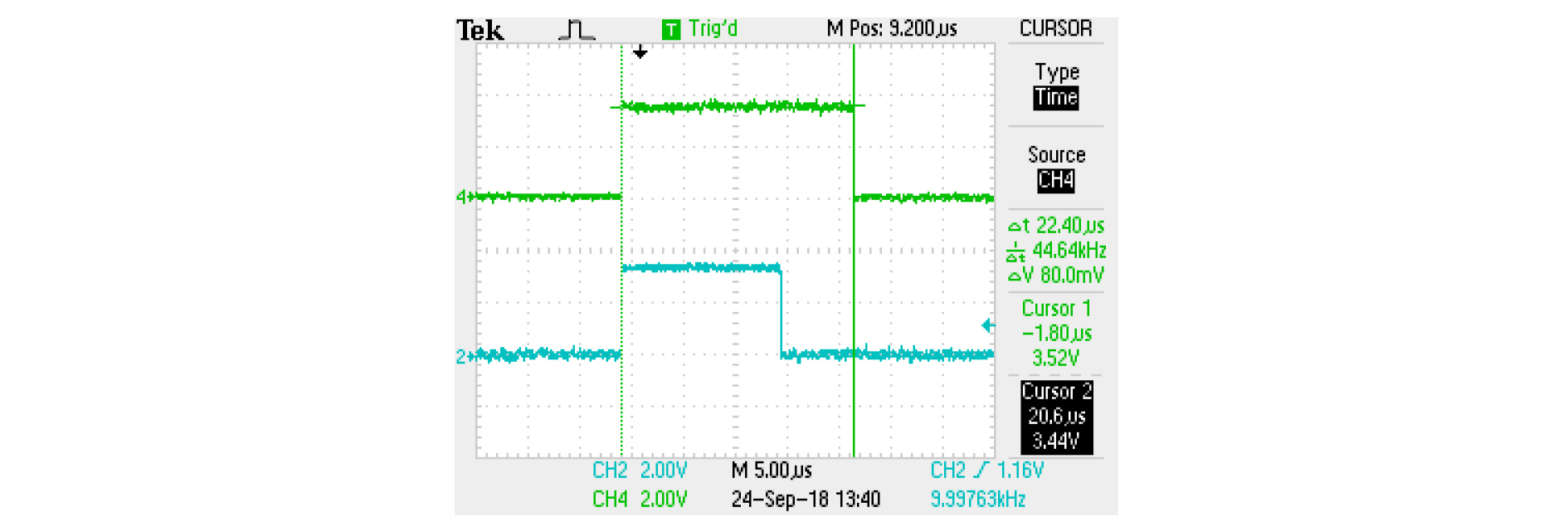
Fig. 9와 비교해 보면, CLA의 실행 소요 시간이 22.40 µs에서 11.40 µs으로 줄어 들었으므로 어셈블리 프로그래밍을 통하여 CLA의 연산 속도가 거의 2배 가까이 향상되었음을 알 수 있다. 이제 CLA의 Eq. (2) 연산이 CPU가 Eq. (1)을 연산하는 시간보다 짧아졌다. 한편, Eq. (2)와 Eq. (3)의 연산량은 유사하고, Eq. (4)는 Eq. (3)의 연산량보다 많기 때문에 CLA의 Eq. (3) 연산 역시 CPU의 Eq. (4) 연산보다 일찍 종료된다. 이상의 방법과 같이 CLA를 이용한 병렬 처리 2단계를 수행할 경우, 실시간 가능한 최대 적응 필터 차수는 L = 418이 였다. 최종적으로 baseline 코드와 비교해 보면 실시간으로 동작할 수 있는 적응 필터의 차수가 4배 이상 증가하였다. 한편, 이제 2차 경로와 관련된 연산은 전적으로 CLA에서 이루어지고 있기 때문에 CLA의 연산 능력 한도 내에서 2차 경로의 전달 함수 차수 N을 늘려도 실시간 동작에는 전혀 영향을 미치지 않는다. 실제로 Fig. 10은 2차 경로의 전달 함수 차수 N = 80, 적응 필터 차수 L = 352인 경우인데, CLA의 연산이 CPU의 연산보다 먼저 종료되고 추가적인 연산 여력이 있음을 알수 있다. 더구나 L = 418의 경우에는 CPU 연산 시간이 늘어나기 때문에 CLA 역시 연산할 있는 시간적 여유가 더 생긴다. 따라서, 2차 경로 전달 함수의 차수를 높일 수 있다. 실제로 N = 100까지 증가시켜도 정상적인 실시간 동작이 가능하였다.
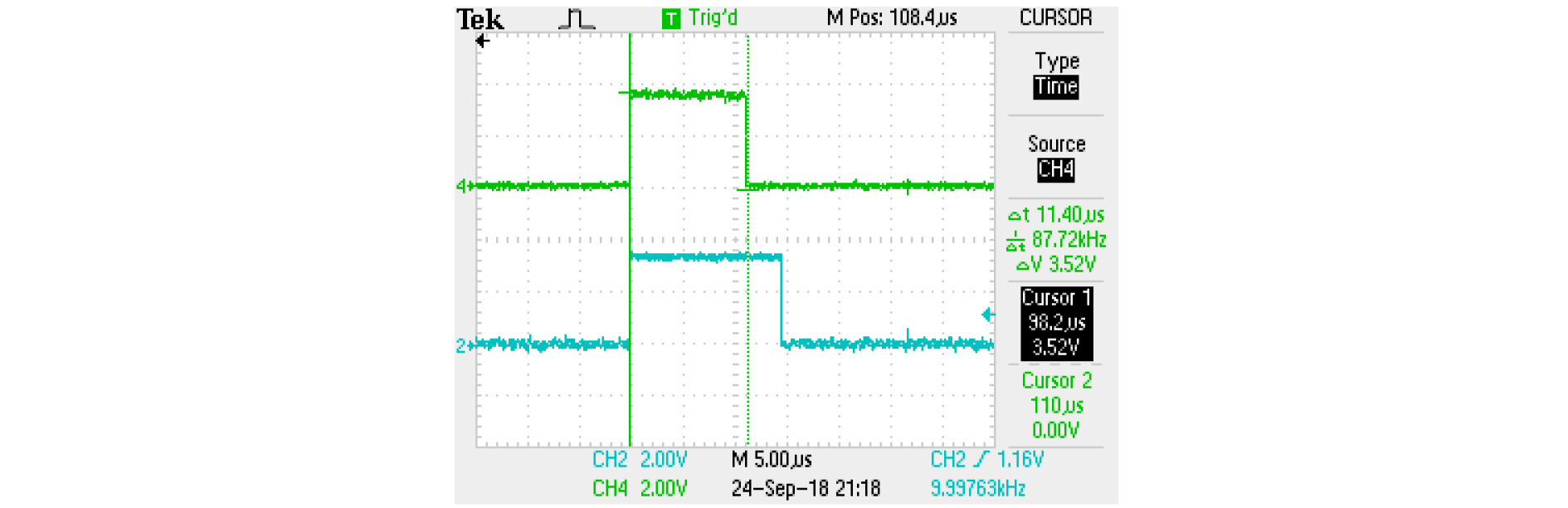
Fig. 11은 본 논문에서 구현한 하드웨어이다. MCU 프로세서 모듈은 개발을 위해 Texas Instruments 사에서 제공하는 에뮬레이터가 포함된 TMS320F280049 MCU 모듈을 사용하였다, 왼쪽은 개발과 실험을 위해 아날로그 front-end와 back-end를 브레드보드 상에서 구현하여 Texas Instruments 사의 MCU 모듈에 연결한 모습이고, 오른쪽은 별도의 TMS320F280049 MCU 모듈 장착을 위해 아날로그 관련 부분을 PCB로 제작한 모습니다. 현재는 MCU 모듈 사이트에 Texas Instruments 사의 모듈을 연결하여 사용 중이며, 자체 MCU 모듈은 현재 개발 중에 있다.

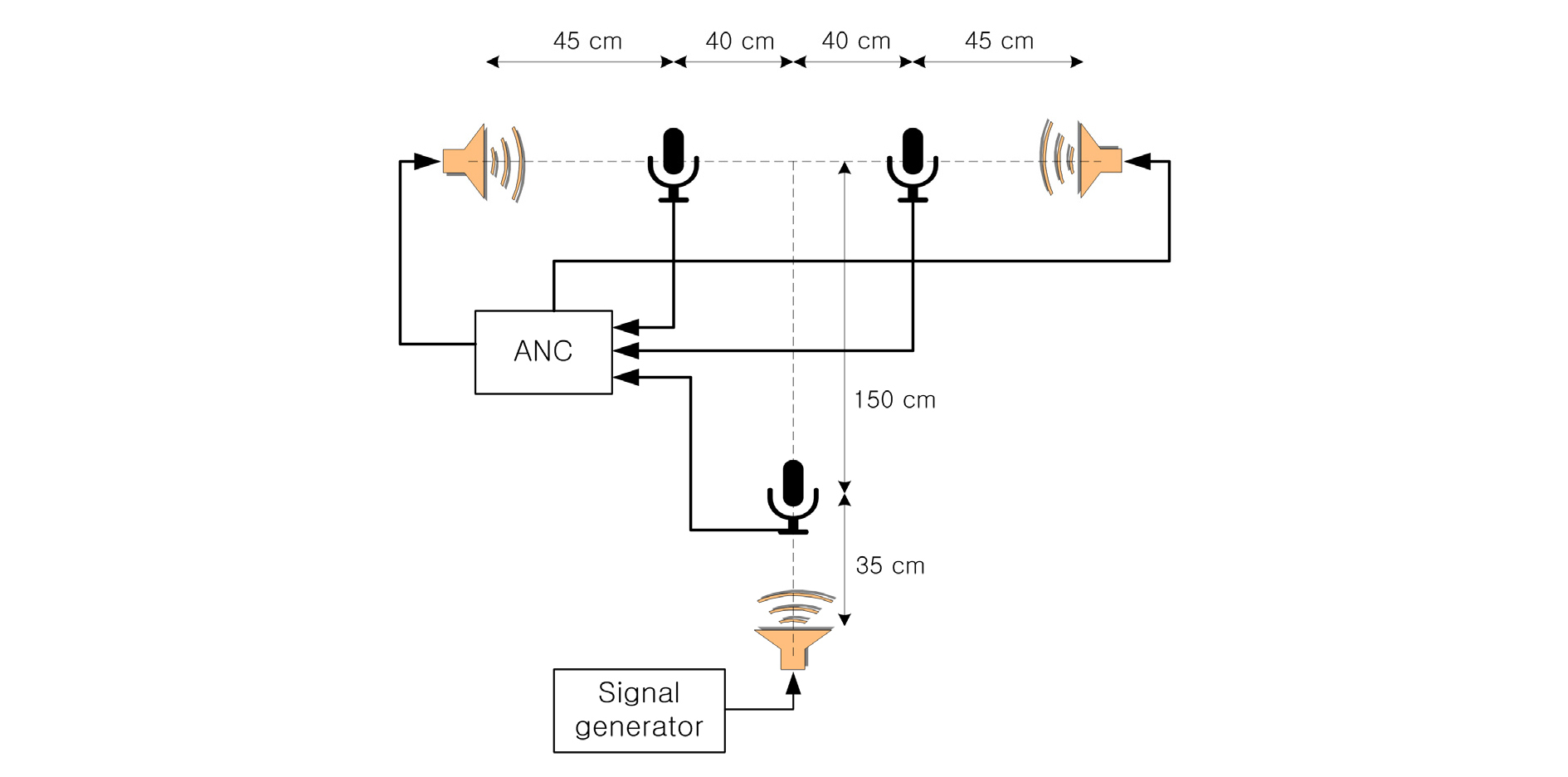
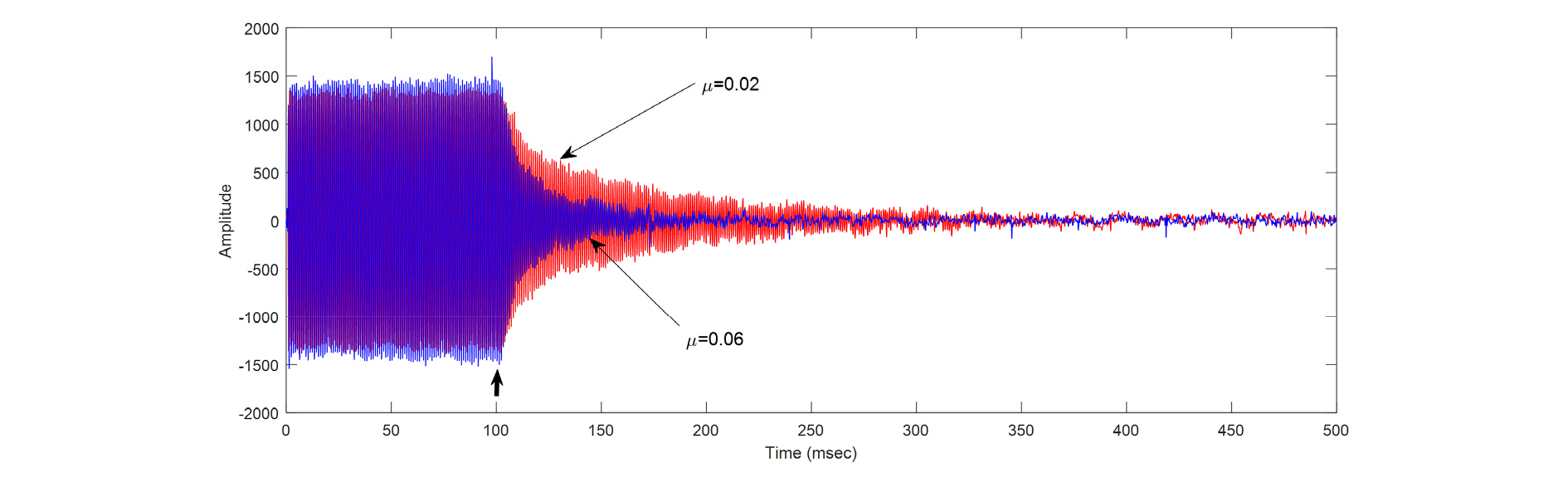
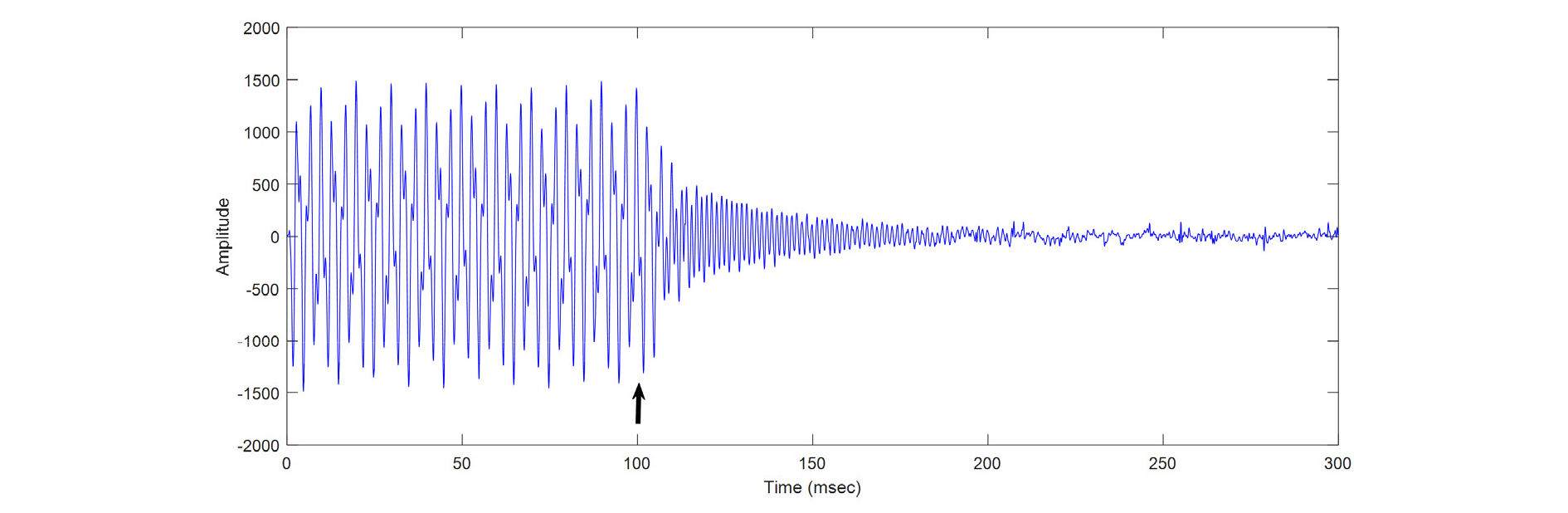
Fig. 12는 실시간으로 동작하는 능동 소음 제어기 실험을 위한 실험 환경을 보여준다. Figs. 13과 14는 능동 소음 제어기가 동작되었을 때 소음이 제거되는 모습을 보여주고 있다. Fig. 13은 소음 신호로 1 kHz의 정현파를 사용하였으며 수렴 인자 µ가 0.02와 0.06일 때의 수렴 과정을 보여준다. 두 에러 마이크를 통해 입력된 신호의 양상이 거의 유사하기 때문에 한 에러 마이크의 신호만을 도시하였다. 그림에서 굵은 화살표는 능동 소음 제거기가 개시된 시점을 보여준다. 수렴 인자가 클 때, 수렴 속도가 빠름을 볼 수 있다. Fig. 14는 소음 신호로 200 Hz와 700 Hz의 다중 정현파를 사용하였을 때의 수렴 특성을 수렴이 진행되는 부분을 중심으로 보여 준다.
IV. 결 론
본 논문에서는 저가 MCU를 이용하여 다채널 능동 소음기를 효율적으로 구현할 수 있는 방안을 제안하였다. 구현에 사용한 MCU는 다채널 능동 소음기 구현에 필요한 주변 장치들을 모두 내장하고 있기 때문에 최소한은 추가 부품으로 다채널 능동 소음 제거기를 구현할 수 있었으며, 단독 동작을 위해 적절한 anti-aliasing 필터와 anti-imaging 필터 구현을 포함하였다. 저가 MCU의 부족한 성능을 보완하기 위하여 소프트웨어 최적화를 수행하였다. CPU만을 이용한 최적화를 통하여 baseline 코드에 비하여 적응 필터의 차수를 3배 이상 늘릴 수 있었다. 한편, 보조 프로세서인 CLA를 이용한 병렬 처리를 추가함으로서 baseline 코드에 비하여 적응 필터의 차수를 4배 이상 늘렸다. 본 연구를 통해 고가의 연구 장비를 통해서 실험실에서 수행되던 능동 소음 제거 기술이 상용화되는 데 기여할 것으로 기대한다.
