

I. 서 론
II. 제안하는 음악 추천 시스템
2.1 템포 기반의 음악 분류 및 색인
2.2 DSNN 기반의 인간 행동 인식
III. 실험 결과
3.1 데이터베이스와 실험 환경
3.2 실험 결과
IV. 결 론
I. 서 론
음악은 사람들의 삶에 중요한 역할을 하며 행동을 증진한다고 알려져 있다. 하지만 사용자는 일상 행동 중에 자신의 상황에 맞는 음악을 찾고 바꾸는 것이 어려우므로 적합한 음악을 자동으로 추천해주는 시스템을 필요로 한다.[1]대부분의 음악 추천 시스템은 사용자의 개인적인 선호도뿐만 아니라 많은 사용자의 관심사와 유사성과의 관계를 기반으로 음악을 분류하고 추천하지만, 사용자의 선호도를 파악하기 위해서는 일정 시간이 필요하다. 또한, 사용자는 다양한 환경에서 이동하는 동안 음악을 청취하기 때문에 그들의 음악 선호도는 단기간 변동성을 가진다.[2]이러한 상황을 반영하고 사용자의 단기적 요구를 충족시키기 위해 감정 및 신체적 상태와 같은 다양한 상황 정보들을 적용하고자 하는 음악 추천 시스템이 활발히 연구되고 있다.[3]
음악은 사람들의 정서와 감정에 매우 직접적인 영향을 끼치는 매개체이다. 음악과 인간 행동의 관계에 관한 많은 연구들을 살펴보면, 음악의 다양한 특성 중 템포가 신체의 움직임과 행동에 많은 영향을 준다는 것을 제시해오고 있다.[4] 이를 역으로 적용하면 사용자의 행동을 인식하고 인식된 행동을 기반으로 적합한 템포의 음악을 추천하고 재생할 수 있다. 센서 기반의 행동 인식은 다양한 센서를 통해 인간의 특정 행동을 인식하는 연구 분야로, 최근에는 모바일 장치에 내장된 가속도, 자이로스코프, 블루투스 등의 센서들로부터 추출된 센서 데이터를 기계학습, 딥러닝에 적용하는 연구가 진행되고 있다.
이에 본 논문에서는 움직임 센서의 실시간 데이터를 통해 인식된 인간 행동 기반의 템포 지향 음악 추천 시스템에 대해 제안한다. 제안하는 방식에 대한 주요 관점들은 다음과 같다. 1) 제안하는 시스템은 스마트폰에 내장된 움직임 센서를 통해 행동을 인식하고 템포 기반의 적합한 음악을 추천한다. 2) 템포 음악 분류 성능 향상을 위해 동적 분류기(Dynamic Classification using a Long-term modulation spectrum, DCL)와 시퀀스 분류기(Sequence Classification using a Short-term spectrogram, SCS)를 결합한 앙상블 분류기를 적용한다. 3) 심층 스파이킹 신경망(Deep Spiking Neural Network, DSNN)을 적용하여 시계열 데이터로부터 높은 정확도로 인간 행동을 분류한다.
본 논문의 구성은 다음과 같다. II장에서는 제안한 방식에 대해 묘사한다. III장에서는 실험 결과를 보여준다. 마지막으로 IV장에서는 결론을 맺는다.
II. 제안하는 음악 추천 시스템
Fig. 1은 제안하는 음악 추천 시스템의 전체 구조를 보여준다. 제안하는 시스템에서는 첫 번째로, 모바일 장치에 저장된 음악 파일에 템포 기반의 음악 분류를 통한 음악 색인이 적용된다. 이때, 입력된 음악 파일에 메타데이터와 같은 템포 정보가 포함되어 있다면, “매우 빠름”, “빠름”, “보통”, “조금 느림”, “느림”, “매우 느림”과 같은 6개의 템포 범주 중 하나에 색인된다. 반대로 템포에 대한 정보가 없다면 입력된 음악 파일은 음악 신호로부터 추출된 특징을 사용하여 템포 범주에 분류된다. 그 후 템포 기반 음악 분류의 결과와 각 사용자의 청취 기록이 결합되어 음악 파일이 자동적으로 색인된다.
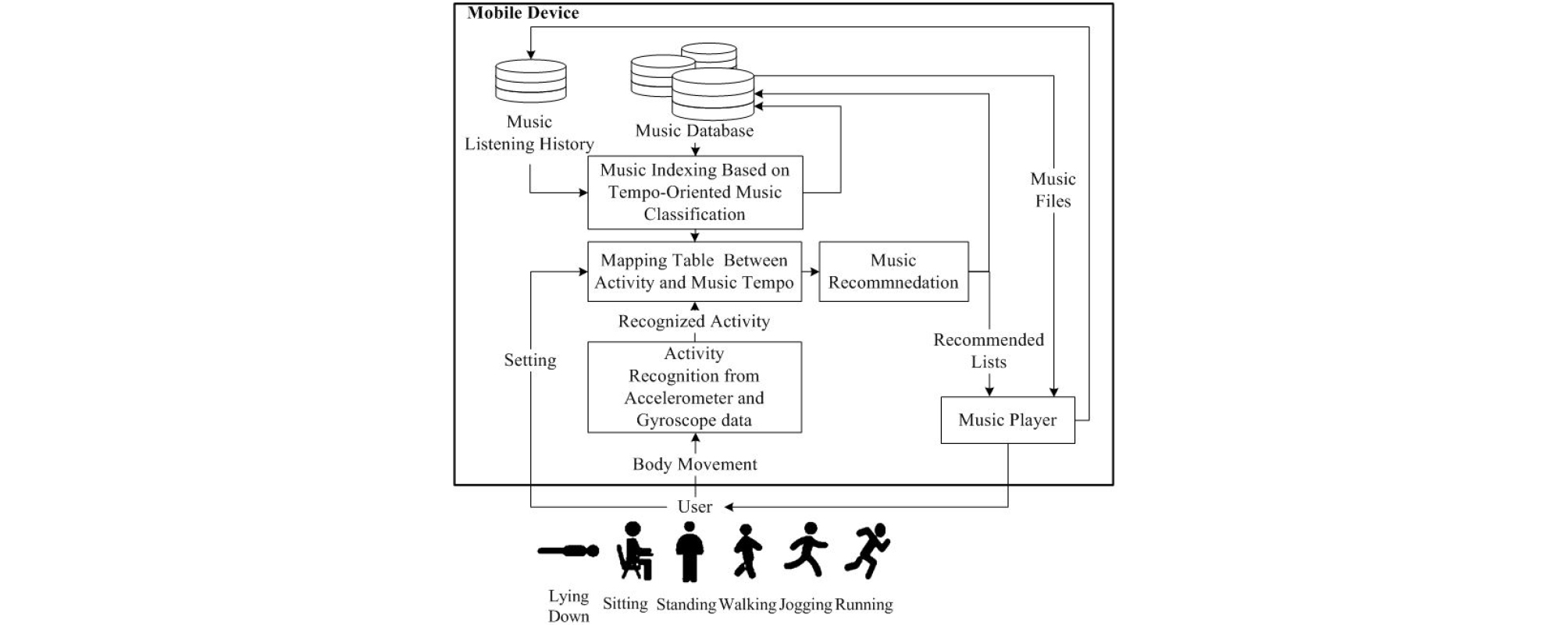
두 번째로, 모바일 장치 안에 내장된 움직임 센서를 통해 3축 가속도계와 자이로스코프 데이터를 수집하여 움직임 변화를 감지하고 “눕기”, “앉기”, “서있기”, “걷기”, “조깅”, “달리기”와 같은 여섯 가지 행동 범주를 인식한다.
세 번째로, 인식된 행동에 따라 적합한 음악을 추천하기 위해 매핑 테이블을 설정한다. 제안하는 시스템의 매핑 관계는 다음과 같다. 1) 자동 비례 매핑 관계 : 색인된 음악의 템포가 인식된 사용자의 행동에 비례하도록 설정된다. 즉, “눕기”는 “매우느림”, “앉기”는 “조금 느림”, 그리고 “달리기”는 “매우 빠름”으로 순차적으로 설정된다. 2) 사용자 설정에 따른 행동 활성화 매핑 관계 : 사용자가 인식된 행동에 따른 자신의 선호 음악 템포를 각각 설정한다.
마지막으로, 음악 추천 목록은 행동과 음악 템포에 따른 매핑 테이블을 통해 생성되며, 사용자는 음악 플레이어를 통해 추천된 음악을 청취한다. 그리고 재생된 음악은 음악 청취 기록 데이터베이스에 저장되어 음악 추천 시스템에 적용된다.
2.1 템포 기반의 음악 분류 및 색인
본 논문에서는 높은 정확도로 템포 기반의 음악 분류결과를 획득하기 위해 장기간 모듈 스펙트럼 기반의 DCL과 단기간 스펙트로그램 기반의 SCS를 결합한 앙상블 방식을 사용한다.
오프라인 프로세스에서 음악 신호로부터 추출된 각 특징은 두 종류의 분류기 학습에 적용되어 모델을 생성하고, 생성된 모델들은 스마트폰의 분류기에 적용된다. 앙상블 분류 결과는 스마트폰에서 동일한 음악의 각 분할 부분에 대해 훈련된 개별 분류기의 출력들이 결합하여 결정된다. 이때, 다수결 투표 규칙을 적용하여 두 분류기의 출력을 비교하고 가장 자주 예측된 출력을 최종 결과로 결정한다.
DCL은 변조 스펙트럼 추출부와 ResNet-18[5]로 구성된다. 템포 정보는 악기의 리듬에 해당하는 영역으로 주로 30에서 300 BPM(0.5 Hz ~ 5 Hz)에 해당하는 저주파에 분포하기 때문에 변조 스펙트럼에 의해 생성된다. 변조 스펙트럼은 수정 이산 코사인 변환 대역 신호에 대한 장기 이산 푸리에 분석을 통해 구현된다. 이때, 분석 창의 길이는 3초, 분석 이동은 1초를 사용한다. 신호의 빠른 변화 성분을 검출하기 위해 시간에 따라 인접한 프레임 간의 전파 정류 및 진폭 편차를 적용하고, 이후에 저역 통과필터를 통해 템포 범위를 벗어난 신호성분들을 제거한다. 그런 다음, 장기 분석 창을 통한 이산 푸리에 변환을 수행하여 템포 특징을 갖는 변조 스펙트럼이 추출된다. 추출된 변조 스펙트럼은 입력 특징으로써 ResNet-18에 입력된다. ResNet-18은 18개의 레이어로 구성된 잔류 신경망으로 잔류 학습을 통해 깊은 신경망 구조의 기울기 폭발/손실 문제를 해결하고 추출된 템포 특징을 사용하여 높은 분류 성능을 제공한다.
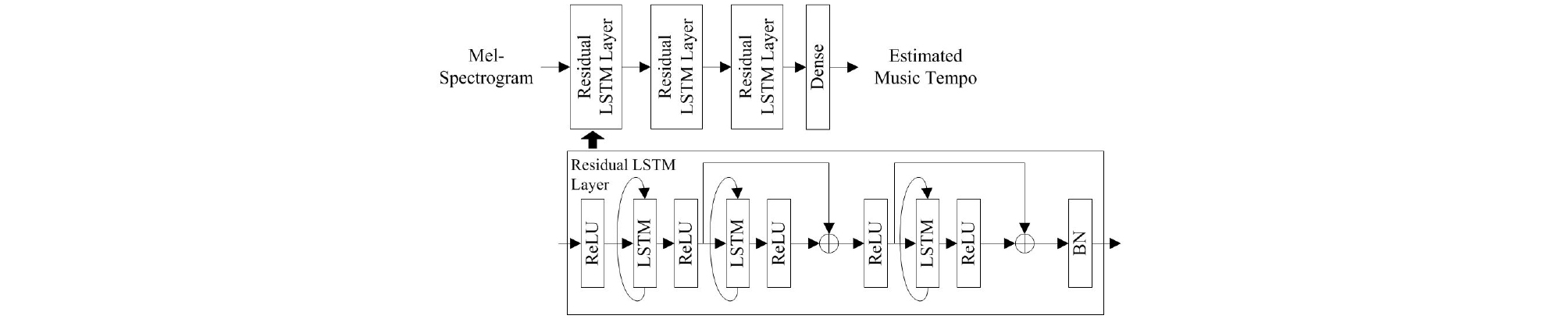
그러나 다양한 리듬 악기들이 혼합된 경우에는 정확한 템포 패턴을 포착하는 것이 어렵다. 이러한 문제점을 개선하기 위해 단기 특징의 순차적 특성을 비트 스펙트럼으로 반영할 수 있는 SCS 방식이 필요하다. SCS는 멜 스펙트로그램 추출부와 심층 잔류 장단기 기억(Deep Residual Long-Short Term Memory, DRLSTM)[6] 신경망으로 구성된다.
먼저, 음악 신호에 대해 단구간 푸리에 변환을 통해 추출한 스펙트럼에 40개의 멜 필터뱅크를 적용하고, 각 필터에 에너지를 합하여 멜 스펙트럼을 추출한다. 멜 범위 임계 밴드의 스펙트럼 에너지 값은 데시벨 범위로 변환되어 음량 수준 곡선과 임계 대역 당 특정 음량 감도를 계산한다. 이를 통해 음악 신호의 각 프레임에서 비트 스펙트럼 특징이 추출된다. 추출된 멜 스펙트로그램의 장기 의존성을 학습하기 위해 DRLSTM을 사용하며 이는 Fig. 2에 나타나 있다. LSTM은 입력 게이트, 망각 게이트, 출력 게이트를 사용하여 내부 셀 장치의 정보 흐름을 제어하고 잔류 연결은 하위층의 입력 데이터를 상위층으로 직접 전달함으로써 기울기의 소실 문제를 효과적으로 해결한다. 이를 식으로 표현하면 다음과 같다.
| $$h_{k+1}^{DRLSTM}=h_k^{LSTM}+\Lambda(h_k^{LSTM},x_k;W_k),$$ | (1) |
여기서 hk와 hk+1는 k번째 유닛의 입력과 출력을 나타내며, Λ는 가중치 매개 변수 Wk를 이용한 잔류 함수를 나타낸다. 또한, xk는 현재의 입력을 나타낸다.
2.2 DSNN 기반의 인간 행동 인식
가속도계와 자이로스코프 센서가 내장된 스마트폰은 일상적인 움직임을 수치화하고 이러한 움직임을 행동으로 분류할 수 있는 강력한 기능을 제공한다. 본 논문에서는 가속도계와 자이로스코프 데이터를 사용하여 여섯 가지 행동을 분류한다.
Fig. 3은 여섯 가지 다른 행동에 대해 각각 약 2초 동안 기록된 가속도계 및 자이로스코프 센서 데이터를 보여준다. 수집된 훈련데이터는 서버에서 여섯 가지 행동을 식별하는 모델을 학습하는 데 사용되며, 학습된 모델은 스마트폰의 인간 행동 인식기에 적용된다. 이때, 서버에서는 데이터의 희소성 문제를 해결하기 위해 데이터 증강 방식[7]을 적용하여 학습 데이터를 확장하고 여섯 가지 행동을 효과적으로 모델링하기 위해 DSNN 기반의 모델을 학습한다. 인식단계에서는 여섯 가지 행동을 식별하기 위해 훈련된 DSNN 모델에 스마트폰의 가속도계와 자이로스코프 신호를 입력하여 행동 분류를 수행한다. 이때, 신호를 입력받는 동안, 스마트폰의 방향 전환으로 인해 x, y, z 데이터의 축이 부분적 또는 완전히 바뀔 수 있으므로 각 축의 데이터는 독립적인 커널 필터를 사용하여 합성 곱 연산을 수행한 후 하나의 신호로 요약되어 다음 과정으로 입력된다.
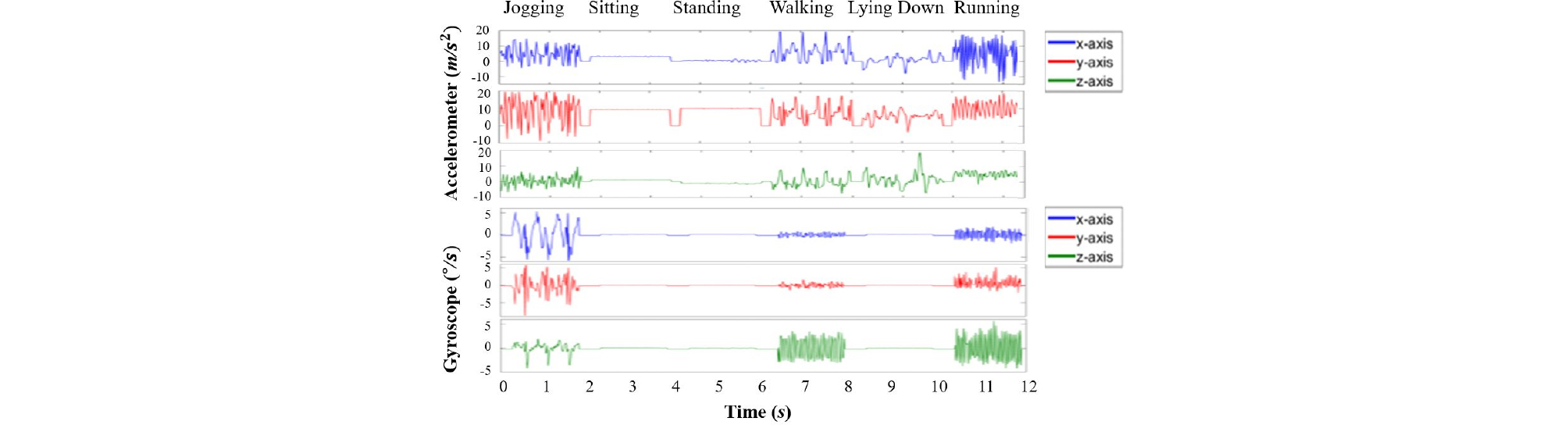
Fig. 4는 행동 인식에 적용되는 DSNN의 구조를 보여준다. DSNN은 6개의 합성 곱 층, 1개의 맥스 풀링, 2개의 은닉 층, 1개의 소프트 맥스로 구성된다. 각 합성 곱 층은 여러 커널이 쌓인 합성 곱 필터 1개, 배치 정규화(Batch Normalization, BN) 1개 및 스파이킹 함수 1개로 구성된다. DSNN은 특정 시점에 발생하는 불연속 스파이크에 의해 입력된 값이 임계값보다 크면 1이 출력되며 그렇지 않으면 0이 출력된다. 이때, DSNN을 사용하여 인식 정확도를 향상시키기 위해서는 데이터의 특성을 고려하여 DSNN을 활성화하기 위한 적절한 임계값을 찾는 것이 중요하다. 이를 위해 제안된 방식에서는 Whetstone 방식[8]을 사용한다. Whetstone 방식은 기존의 딥러닝 방법을 사용하여 이진 임계값으로 활성화되는 DSNN을 학습시킨다. 경계 정류 선형 단위(bounded Rectified Linear Unit, bReLU) 함수 Sα,β는 초기화 함수로써 α, β를 통해 3개의 구역으로 정의되며 다음과 같다.
| $$S_{\alpha,\beta}=\left\{\begin{array}{l}\begin{array}{ccc}1,&if&x_l\geq\beta\\(x_l-\alpha)/(\beta-\alpha),&if&\alpha\leq x_l<\beta\\0,&if&x_l\leq\alpha\end{array}\end{array}\right..$$ | (2) |
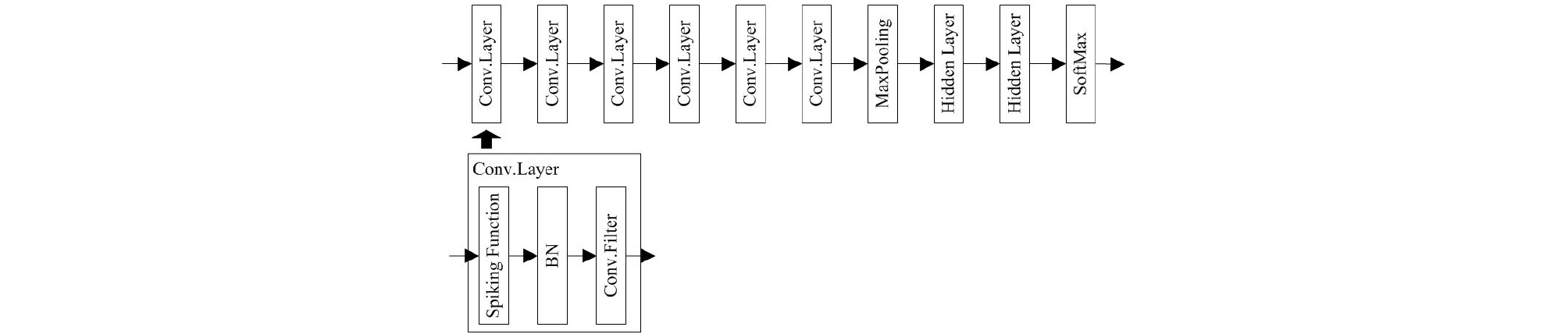
학습 과정을 통해 와 의 차이를 줄임으로써 각 계층의 임계값은 순차적으로 | -0.5 | = | -0.5 |와 동일하게 되고 bReLU 함수는 이진화 되어 스파이킹 함수로써 작동한다. 스파이킹 함수는 학습된 임계값을 사용하여 입력 데이터에서 빈도수가 많고 신호강도가 큰 신호의 특징을 활성화하기 때문에 계산의 복잡성을 줄여줄 뿐만 아니라 데이터 인식 정확도를 향상하는 적응형 필터의 역할을 수행하며 최종적으로 = 0.398, = 0.602의 값으로 결정되었다.
III. 실험 결과
3.1 데이터베이스와 실험 환경
본 실험에서는 템포 기반의 음악 분류 및 색인의 성능을 평가하기 위해 템포정보가 색인된 1300개의 음악 데이터베이스를 사용하였으며 템포에 따라 다음과 같은 6개의 범주로 분류하였다: “매우 느림(40 BPM ~ 57 BPM)”, “느림(58 BPM ~ 65 BPM)”, “약간 느림(66 BPM ~ 83 BPM)”, “중간(84 BPM ~ 19BPM)”, “빠름(120 BPM ~ 192 BPM)”, “매우 빠름(192 BPM) 이상”. 각 곡의 길이는 최소 3분으로 서로 다른 녹음 품질을 다루기 위해 컴팩트 디스크, 라디오, 인터넷과 같은 미디어에서 수집되었다. 그리고 스테레오에서 44.1 kHz와 128 kbps의 표준 MP3 오디오 파일로 인코딩된 후 데이터베이스에 저장되었다. 모든 실험 결과는 4-fold 교차 검증 평가를 사용하여 학습에 70 %, 테스트에 30 %의 곡을 적용하고 최종적으로 4세트의 평균 결과를 측정하였다.
행동 인식 성능을 평가하기 위해 서로 다른 3개의 제조사로부터 5대의 스마트폰을 사용하여 가속도계와 자이로스코프 데이터를 수집하였다. 실험에는 15세에서 40세 사이의 남성 8명, 여성 7명이 참여했으며, 가속도계 데이터는 50 Hz로 각 축에 따른 가속도 값을 제공하며 자이로스코프 데이터는 시간에 따른 물체의 각속도 변화를 초당 mV 단위로 제공한다.
3.2 실험 결과
Table 1은 제안된 방식과 다른 신경망 구조를 포함한 방식의 결과를 비교한다. 실험 결과, DCL과 SCS를 결합한 앙상블 분류를 사용하여 최상의 결과(95.2 %)가 나타난다. SCS가 없는 DCL의 정확도는 앙상블 분류보다 낮지만, 변조 스펙트럼을 사용하는 LSTM, CNN보다 높다. 또한, SCS는 템포 지향 음악 분류에는 직접적인 영향을 미치지 않지만, 비트 스펙트럼을 포함하기 때문에 DCL과 결합하여 높은 음악 분류 성능을 보여준다. Fig. 5는 음악 분류의 상호 오류 결과를 나타낸다. 특히, “매우 빠름”과 “빠름”에서 가장 많은 오류가 발생하는 것을 확인할 수 있었다.
Table 1.
Tempo-oriented automatic music classification results.
| Methods | Recognition accuracy |
| Modulation spectrum (MS)-CNN | 88.3 % |
| Modulation spectrum (MS)-LSTM | 88.7 % |
| DCL | 91.6 % |
| SCS | 74.4 % |
| Ensemble (DCL+SCS) | 95.2 % |
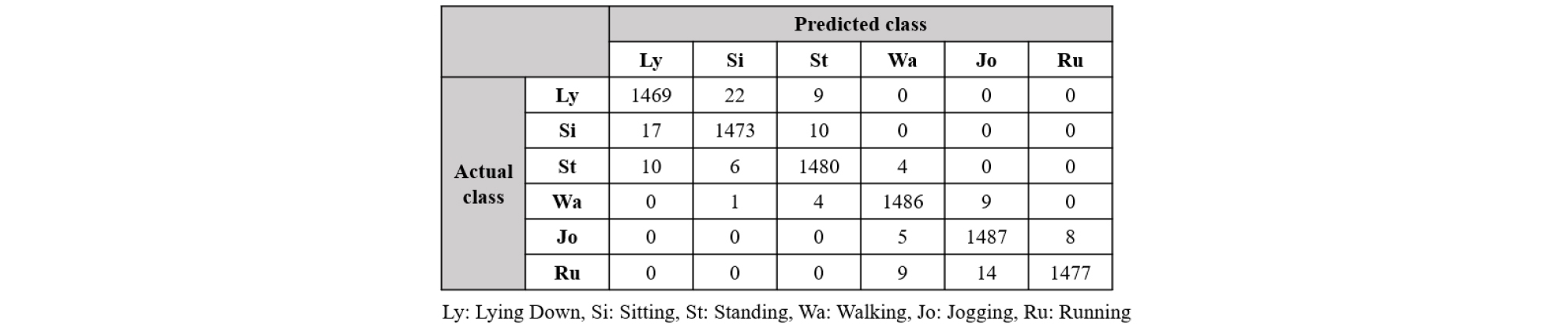
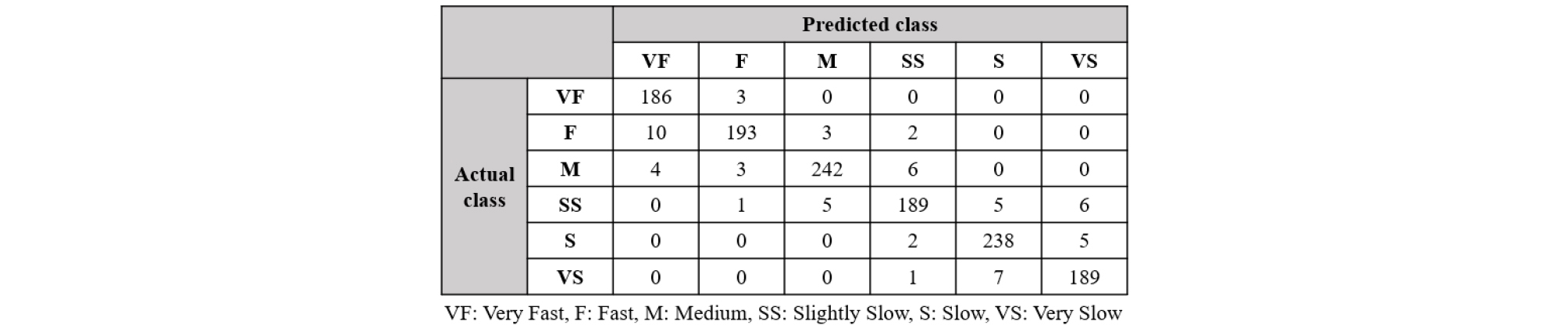
행동 인식 실험 결과는 Table 2에 제시되어 있으며, 가속도계 데이터만 적용되었을 때와 가속도계와 자이로스코프 데이터가 적용되었을 때의 행동 인식 성능을 비교하였다. 결과를 통해 두 가지 데이터가 모두 적용될 때의 인식률은 가속도계 데이터만 적용했을 때보다 2 % ~ 3 % 정도 상승하였음을 확인할 수 있다. DSNN은 학습된 임계값을 사용하여 사람의 작은 움직임에 의해 생성된 잡음 신호가 아닌 인식에 효과적인 신호만을 필터링하여 98.3 %의 정확도를 보여주며 다른 접근법을 크게 능가한다. ResNet -50의 경우 깊은 신경망 구조를 통해 데이터의 특징을 효과적으로 추출함으로써 CNN보다 우수하다. 또한, Fig. 6에는 행동 인식의 상호 오류 결과가 제시되었다. 가장 일반적인 행동인 “걷기”와 “조깅”의 경우에는 약 99 %의 우수한 행동인식 결과가 제공되고 있는 반면에, “앉기”와 “눕기”와 같은 행동을 인식하는데 있어서는 많은 오류가 발생하였다.
Table 2.
Automatic human activity recognition results.
| Methods | Recognition accuracy | |
| Accelerometer | Accelerometer + Gyroscope | |
| CNN | 90.4 % | 92.7 % |
| ResNet-50 | 91.5 % | 93.6 % |
| DSNN | 95.3 % | 98.3 % |
마지막으로 자동 비례 매핑 방식을 기반으로 인식된 행동에 따라 적합한 템포 기반의 음악을 추천하는 시스템의 사용자 만족도를 평가하였다. 이때, 자연스러운 음악 추천을 위해 실험참가자는 동일한 행동을 최소 10 s 이상 유지하였다. 시스템은 2 s 단위로 행동을 인식하고 해당 행동에 적합한 음악을 추천하며, 동일한 행동이 인식될 경우 추천된 음악이 지속해서 재생되도록 설정하였다. 평가를 위해, 18세에서 40세 사이의 10명의 청취자를 대상으로 20일 동안 주관적인 품질 평가를 시행했다. 참가자 1인당 하루 3회(아침, 점심, 저녁) 100곡 중 10곡을 선정해 템포 지향 음악 분류에 적용했다. 평가 점수는 평균 의견 점수(Mean Opinion Score, MOS)를 통해 5단계 척도 (1: Bad, 2: poor, 3: fair, 4: good, 5: excellent)로 분류된 곡이 취향에 따라 적절한 템포로 분류되었는지를 평가하였다. 그 결과, 템포 지향의 음악 분류와 행동 인식의 오류로 인해 6000곡 중 562곡에서 음악 추천 오류가 발생하였으며, 전체 추천된 음악에 대한 MOS 점수는 3.87점을 획득하였다. 그리고 발생한 오류 음악곡들만을 대상으로 측정한 MOS 점수는 2.21이었으며, 오류가 발생하지 않고 추천된 곡에 대한 MOS 점수는 4.13으로 측정되었다.
