I. 서 론
잡음 제거 기술은 음성 신호 처리 분야의 주요 기술 중 하나로서 잡음이 존재하는 실생활 환경에서 자동 음성 인식, 음성 통신의 성능 보장을 위해 요구되는 기술이다. 하드웨어의 발전에 따라 두 개 이상의 마이크를 이용하는 기기들이 증가하고 있으며, 이에 따라 다채널 잡음 제거 기술에 관한 연구도 확대되어 왔다.
단일 채널 신호에 비해 다채널 신호에는 신호의 공간 정보가 포함되어 있어 음성 왜곡을 최소화하면서 잡음 제거를 효과적으로 수행할 수 있다. 다채널 잡음 제거에 관한 초기 연구에서는 전통적인 빔포밍 기법을 활용하는 연구가 주로 수행되었고, 이후에는 음성 신호와 출력 신호 간의 자승 오차를 통계적 평균 관점에서 최소화하는 필터인 다채널 위너 필터(Multi-channel Wiener Filter, MWF)에 관한 연구가 활발히 진행되었다.[1,2,3,4,5,6,7]
다채널 위너 필터를 구하기 위해서는 음성과 잡음의 상관 행렬들을 추정해야 하는데, 이들 상관 행렬 추정의 정확도에 따라 필터의 잡음 제거 성능이 좌우된다. 음성과 잡음의 상관 행렬들을 추정할 때, 음성 존재 확률을 이용하여 잡음과 음성의 상관 행렬을 추정할 수 있다.[7,8,9] 다채널 신호를 이용한 음성 존재 확률은 단일 채널 신호를 사용했을 때보다 우수한 성능을 보이며, 상관 행렬 추정뿐만 아니라 다채널 위너 필터의 음성 왜곡 가중치를 설정하는데도 효과적으로 사용되었다.[2,3,10]
본 논문에서는 다채널 신호의 음성 존재 확률을 이용하여 다채널 위너 필터를 보정하는 방법을 제안하고자 한다. 부공간(subspace)에서 필터를 구할 때, 하나의 음원으로부터 음성이 여러 마이크에 도달하는 경우는 음성 상관 행렬의 랭크(rank)는 1이 되고 음성 상관 행렬의 주성분 벡터만을 이용하여 다채널 위너 필터의 성능을 향상시킬 수 있다.[1,5,6] 이 때 주성분 벡터는 이론적으로 음성 신호의 음향 전달 함수와 같은 방향을 갖게 된다. 그러나 음성 신호 대 간섭 잡음 비가 낮아질수록 음성 상관 행렬 추정 오차가 커지고 이에 따라 주성분 벡터는 음향 전달 함수와 멀어지게 되며 다채널 위너 필터의 잡음 제거 성능 또한 저하된다.
Reference [1]에서는 주성분 부공간 벡터를 보정하기 위해서 음성 음원의 방향 벡터(steering vector)를 이용하는 방법이 제안되었는데, 주성분 벡터와 방향 벡터가 이루는 각도를 계산하고, 각도가 클수록 주성분 벡터를 방향 벡터 쪽으로 보정하는 정도를 크게 하였다. 이러한 보정 방법은 다채널 위너 필터의 성능을 개선하기는 하나, 주성분 벡터가 왜곡되는 원인에 따라 보정하는 정도를 조절하는 것이 아니라 주성분 벡터가 왜곡된 결과에 따라 보정 정도를 조절하는 방법이다. 본 연구에서는 이러한 방법과 달리 주성분 벡터를 왜곡시키는 원인인 신호 대 간섭 잡음 비와 밀접한 음성 존재 확률을 이용하여 주성분 벡터를 보정하는 정도를 조절하는 방법을 제안하고자 한다. 음성 상관 행렬의 랭크가 1이라는 가정 하에서의 부공간 분해를 통한 다채널 음성 존재 확률을 유도한 후 이를 이용하여 주성분 벡터를 보정하는 방법을 제안한다.
제안하는 방법의 성능을 검증하기 위해 간섭 잡음이 섞인 신호를 다채널 위너 필터에 통과시켜 그 출력 신호의 신호 대 잡음 비와 음성 왜곡과 등의 정량적 지표를 계산하였으며, 그 결과 제안하는 방법을 통해 다채널 위너 필터의 잡음 제거 성능을 향상시킬 수 있음을 확인하였다.
II. 다채널 위너 필터
여러 개의 마이크로부터 취득된 다채널 신호는 다음 식으로 표현될 수 있다.
| $$\begin{array}{l}Y_i(l,k)=H_i(l,k)S(k)+N_i(l,k)\\\;\;\;\;\;\;\;\;\;\;\;\;=X_i(l,k)+N_{i`}(l,k)\end{array},$$ | (1) |
여기서 는 단일 음성 음원을 나타내고, 는 단일 음성 음원으로부터 번째 마이크까지의 음향 전달 함수를 나타낸다. 그리고 는 번째 마이크의 신호들을 나타내는데 각각 관찰되는 신호, 음성 성분, 잡음 성분을 나타낸다. 과 는 각각 시간 프레임과 주파수 대역 인덱스를 나타낸다. 개의 마이크를 이용하여 신호를 수신할 때, Eq. (1)에 표현된 신호들은 에서 M 까지 M 개의 수식으로 표현되는데 이들을 모아 M 차원 벡터로 표현하면 다음 식으로 나타낼 수 있다.
| $$\mathbf y(l,k)=\mathbf x(l,k)+\mathbf n(l,k).$$ | (2) |
위 식의 은 각각 M 차원 벡터를 나타내며 Eqs. (3) ~ (5)로 나타난다.
| $$\mathbf y(l,k)=\left[Y_1(l,k)\;Y_2(l,k)\cdots\;Y_M(l,k)\right]^T,$$ | (3) |
| $$\mathbf x(l,k)=\left[X_1(l,k)\;X_2(l,k)\cdots X_M(l,k)\right]^T,$$ | (4) |
| $$\mathbf n(l,k)=\left[N_1(l,k)\;N_2(l,k)\cdots\;N_M(l,k)\right]^T,$$ | (5) |
여기서 는 전치 행렬을 나타낸다.
다채널 위너 필터는 여러 마이크 중 특정 마이크에서 관찰되는 신호의 음성 성분을 추정하는 필터로서 추정하는 음성 성분과 실제 참값 사이의 오차 평균을 최소로 하는 수식화 과정을 통해 유도된다. 다채널 위너 필터를 벡터 로 나타내면 필터를 통과한 출력 신호 는 다음 식으로 나타난다.
| $$Z(l,k)=\mathbf w^H(l,k)\mathbf y(l,k),$$ | (6) |
여기서 는 행렬의 원소들을 켤레 복소수로 바꾸고, 행과 열을 전치시키는 연산 즉, Hermitian 행렬로 바꾸는 것을 의미한다. 음성 성분을 추정하는 특정 마이크를 첫 번째 마이크로 정할 경우, 다채널 위너 필터 는 다음과 같이 나타난다.
| $$\mathbf w(l,k)=\mathbf R_{yy}^{-1}(l,k){\mathbf R}_{xx}(l,k){\mathbf e}_1\boldsymbol\;\simeq\;\mathbf R_{yy}^{-1}(l,k)\left({\mathbf R}_{yy}(l,k)-{\mathbf R}_{nn}(l,k)\right){\mathbf e}_1,$$ | (7) |
여기서 은 첫 번째 원소만 1이고 나머지 원소들은 0인 M 차원 벡터이고, 은 다음 식들로 나타나는 상관 행렬들이다. Eq. (7)에서 음성과 잡음의 교차 상관 행렬인 는 음성 상관 행렬에 비해 무시할만한 수준이라고 가정하였다.
| $${\mathbf R}_{yy}(l,k)=E\left\{\mathbf y(l,k)\mathbf y^H(l,k)\right\},$$ | (8) |
| $${\mathbf R}_{xx}(l,k)=E\left\{\mathbf x(l,k)\mathbf x^H(l,k)\right\},$$ | (9) |
| $${\mathbf R}_{nn}(l,k)=E\left\{\mathbf n(l,k)\mathbf n^H(l,k)\right\}.$$ | (10) |
Eqs. (8) ~ (10)에서 는 통계적 기댓값을 나타낸다. 단일 음원으로부터 음성 신호가 전파된다는 가정 하에 신호의 주성분 벡터에서 필터를 구하기 위해 다음 식과 같이 와 을 동시에 대각 행렬로 만드는 동시 대각화를 적용하면 부공간에서 다채널 위너 필터를 구현할 수 있다. 동시 대각화는 일반화된 고유치 분해를 적용함으로써 실행될 수 있다.[11]
| $$\mathbf Q^{\mathbf H}(l,k){\mathbf R}_{\mathbf y\mathbf y}(l,k)\mathbf Q(l,k)={\mathbf Q}_{\mathbf y}(l,k),$$ | (11) |
| $$\mathbf Q^{\mathbf H}(l,k){\mathbf R}_{\mathbf n\mathbf n}(l,k)\mathbf Q(l,k)={\boldsymbol\Lambda}_{\mathbf n}(l,k).$$ | (12) |
여기서 은 고유치들을 대각 원소로 갖는 대각 행렬이고, 는 와 을 동시에 대각 행렬로 만드는 행렬이다. 는 고유 벡터들()로 이루어진 행렬이며 의 관계가 성립한다. 신호와 잡음 고유치 비는 순으로 정렬되며 여기서 가장 큰 고유치 비율에 해당하는 고유 벡터 즉, 의 원소들을 아래와 같이 정의한다.
| $${\overset{\boldsymbol{\mathit¯}}{\mathbf q}}_1(l,k)=\left[{\overline q}_{1,1}(l,k){\overline q}_{1,2}(l,k)\;\cdots\;{\overline q}_{1,M}(l,k)\right]^T.$$ | (15) |
Eq. (15)에 나타난 고유 벡터는 음성 신호의 주성분 벡터에 해당하며, 이는 또한 Eq. (1)에 표시된 단일 음원의 음성이 여러 마이크에 도달하는 음향 전달 함수와 같은 방향을 갖게 된다. Eqs. (11) ~ (15)에서 나타난 상관 행렬 분해를 바탕으로 음성 주성분 벡터 기반의 다채널 위터 필터를 구하면 Eq. (7)은 다음 식으로 표현될 수 있다.
| $$\mathbf w=\lambda_{n,1}\mathbf R_n^{-1}(l,k){\overline{\mathbf q}}_1(l,k)\left(\frac{\lambda_{y,1}-\lambda_{n,1}}{\lambda_{y,1}}\right)\overset{\mathit¯}{\mathbf q}_1^H(l,k){\mathbf e}_1.$$ | (16) |
III. 음성 존재 확률을 이용한 주성분 벡터 보정
Eq. (7)에서 음성 상관 행렬을 추정할 때 음성과 간섭 잡음 간에는 상관 관계가 무시할만하다고 가정하였다. 이러한 가정은 음성 신호의 세기가 간섭 잡음 신호보다 월등히 클 경우는 유효하나 간섭 잡음 신호의 세기가 커질 경우는 더 이상 유효하지 않게 되고 이로 인해 음성 상관 행렬 추정 오차가 증가하게 된다. 이러한 경우에 고유치 분해로 계산된 주성분 벡터[Eq. (15)]와 음성 신호의 음향 전달 함수 간의 편차는 커지게 된다.[1]
이러한 문제를 해결하고자 음원의 방향을 알고 있을 때, 음원의 방향 벡터를 이용하여 주성분 벡터를 보정하는 방법을 제안하고자 한다. 방향 벡터는 여러 개의 마이크로 신호를 취득하는 경우, 기준이 되는 마이크(예를 들어, 첫 번째 마이크)에 대한 다른 마이크 신호들의 위상 차이를 나타내는 벡터로서 신호의 공간 정보를 나타내는 벡터이다.[12] 앞에서 언급한 것과 같이 간섭 잡음이 커지게 됨에 따라 주성분 벡터와 방향 벡터 간의 편차가 증가하게 되며, 방향 벡터를 이용하여 주성분 벡터를 보정하고자 한다. 방향 벡터를 이용하여 주성분 벡터를 보정하기 위해서는 보정하는 정도를 결정해주어야 하는데, 보정량을 결정하기 위해서는 신호 대 간섭 잡음 비를 활용할 수 있다. 하지만 신호 대 간섭 잡음 비는 정규화된 수치가 아니라 보정량을 결정하기 어려운 문제가 있다. 따라서 본 논문에서는 신호 대 간섭 잡음 비를 사용하는 대신 음성 존재 확률을 이용하여 주성분 벡터를 보정하는 정도를 결정하는 방법을 제안하고자 한다. 음성 존재 확률은 신호 대 간섭 잡음 비와 밀접한 관계를 가지며, 확률값이므로 0과 1사이 값을 나타내므로 추가적인 정규화 과정없이 보정량을 결정하는데 사용할 수 있다.
음성 존재 확률은 음성이 존재한다는 가설(hypothesis) 과 음성이 존재하지 않는다는 가설 에 대해 다음 식과 같이 쓸 수 있다.
| $$H_0(l,k)\;:\;\mathbf y(l,k)=\mathbf n(l,k),$$ | (17) |
| $$H_1(l,k)\;:\;\mathbf y(l,k)=\mathbf x(l,k)\;+\mathbf n(l,k).$$ | (18) |
베이즈 규칙(Bayes’ rule)을 사용하면 음성 존재 확률은 다음과 같이 나타낼 수 있다.
여기서 는 사전(a priori) 음성 존재 확률()을 나타낸다. 다채널 신호에서 음성과 잡음이 가우시안 분포라고 가정하면 음성 존재 확률은 다음 식으로 나타난다.[7,8]
| $$p(l,k)=\left\{1+\frac{1-r(l,k)}{r(l,k)}\lbrack1+xi(l,k)\rbrack\exp\left[-\frac{\gamma(l,k)}{1+xi(l,k)}\right]\right\}_.^{-1}$$ | (20) |
| $$\gamma(l,k)=\mathbf y^H(l,k)\mathbf R_{nn}^{-1}(l,k){\mathbf R}_{yy}(l,k)\mathbf R_{nn}^{-1}(l,k)\mathbf y(l,k)-\mathbf y^H(l,k)\mathbf R_{nn}^{-1}(l,k)\mathbf y(l,k),$$ | (21) |
| $$\xi(l,k)=\mathrm{tr}\left\{\mathbf R_{nn}^{-1}(l,k){\mathbf R}_{yy}(l,k)\right\}-M.$$ | (22) |
는 다채널 사전 신호 대 잡음 비(multi-channel a priori signal-to-noise ratio)를 나타낸다. Eqs. (11) ~ (14)와 같은 부공간을 고려하면 와 을 다음 식들로 유도할 수 있다.
| $$\xi(l,k)=\mathrm{tr}\left(\mathbf Q(l,k)\boldsymbol\Lambda_n^{-1}(l,k)\boldsymbol\Lambda_n^{-1}(l,k){\boldsymbol\Lambda}_y(l,k)\mathbf Q^H(l,k)\right)-M.$$ | (24) |
단일 음원으로부터 음성이 마이크들에 도달할 경우 음성 상관 행렬 의 랭크는 이론적으로 1이 되고, 이 경우 의 고유 벡터 중 주성분 고유 벡터()만 고려하면 Eqs. (23)과 (24)로 나타난 와 는 아래와 같은 간단한 식으로 유도될 수 있다.
| $$\gamma(l,k)=\frac{\lambda_{y,1}(l,k)-\lambda_{n,1}(l,k)}{\lambda_{n,1}^2(l,k)}\left(\mathbf y^H(l,k){\mathbf q}_1(l,k)\right)^2,$$ | (25) |
| $$\xi(l,k)=\frac{\lambda_{y,1}(l,k)}{\lambda_{n,1}(l,k)}\parallel{\mathbf q}_1(l,k)\parallel^2.$$ | (26) |
방향 벡터를 이용하여 Eq. (15)에서 구한 주성분 벡터 를 보정하기 위해서는 와 방향 벡터 를 변형하는 과정이 필요하다. 먼저 을 와 같이 위상 정보만 갖도록 하기 위해서 다음 식과 같이 벡터의 각 원소들을 각각의 절대값으로 나누어준다.
방향 벡터의 첫 번째 원소 위상을 Eq. (27)의 위상과 동일하게 만들기 위해 다음 식과 같이 방향 벡터의 각 원소에 Eq. (27)에 나타난 벡터의 첫 번째 원소를 곱해준다.
| $$\mathbf v'(l,k)=\left[{\overline{\overline q}}_1(l,k)v_1(l,k)\;\;\cdots\;{\overline{\overline q}}_1(l,k)v_M(l,k)\right]^T.$$ | (28) |
는 의 첫 번째 원소이다.
Eqs. (20)과 (25), (26)으로 구한 음성 존재 확률과 Eqs. (27)과 (28)을 이용하여 다음 식과 같이 주성분 벡터를 보정할 수 있다.
| $$\overline{\overline{\mathbf q}}'(l,k)=p(l,k)\overline{\overline{\mathbf q}}(l,k)+\left(1-p(l,k)\right)\mathbf v'(l,k).$$ | (29) |
위 식에 나타난 것과 같이 음성 존재 확률이 1에 가까울 때는 보정이 거의 이루어지지 않게 되고, 음성 존재 확률이 0에 가까운 경우는 보정된 벡터는 방향 벡터에 가깝게 된다. 방향 벡터를 이용하여 주성분 벡터의 위상만 수정하고자 하므로 보정된 벡터 각 원소들의 절대값이 Eq. (15) 원소들의 절대값이 되도록 스케일링한다.
IV. 실험결과
실험을 위한 다채널 신호를 생성하기 위해 RWCP sound scene database에 포함되어 있는 임펄스 응답을 사용하였다.[13] 5.66 cm의 등간격을 이루는 7개의 선형 어레이 마이크의 정면에서 2 m 떨어진 곳에 음성 음원이 배치되어 있고 간섭 잡음은 음성의 방향과 40°를 이루는 방향에서 음성과 마찬가지로 2 m 떨어져서 입사하는 상황을 가정하였다. 샘플링 주파수는 16 kHz이고, 반향 시간은 300 ms이다. 이러한 임펄스 응답을 음성 신호 및 간섭 잡음 신호와 콘볼루션하고 신호 대 간섭 잡음 비(Signal to Interference Noise Ratio, SINR)에 따라 혼합하여 다채널 신호를 재현하였다. 간섭 잡음으로는 백색 잡음과 음성 간섭 잡음(competing speech)을 사용하였으며, 0 dB, 5 dB, 10 dB의 SINR이 되도록 다채널 신호를 생성하여 실험하였다.
잡음 제거 성능을 측정하기 위해 SINR gain, Mel- Frequency Cepstral Coefficient(MFCC) 거리를 사용하였다. 사전 음성 존재 확률 는 Reference [8]에서와 같이 0.4로 두고 실험하였다. 사전 음성 존재 확률값에 따라 음성 존재 확률이 영향을 받으나 Eq. (20)에서 확인할 수 있듯이 가 주된 영향을 미치게 되므로 사전 음성 존재 확률을 0이나 1에 가깝게 설정하지 않는 한 성능에 미치는 영향은 크지 않다. 실험 결과는 Fig. 1에 그래프로 표시하였다. Fig. 1에 PS로 표시된 것은 주성분 벡터를 이용한 다채널 위너 필터이고, PS_ANG는 주성분 벡터와 방향 벡터의 각도를 이용하여 주성분 벡터를 보정한 결과이며, PS_SPP는 본 논문에서 제안하는 음성 존재 확률을 이용하여 주성분 벡터를 보정한 다채널 위너 필터의 결과이다.
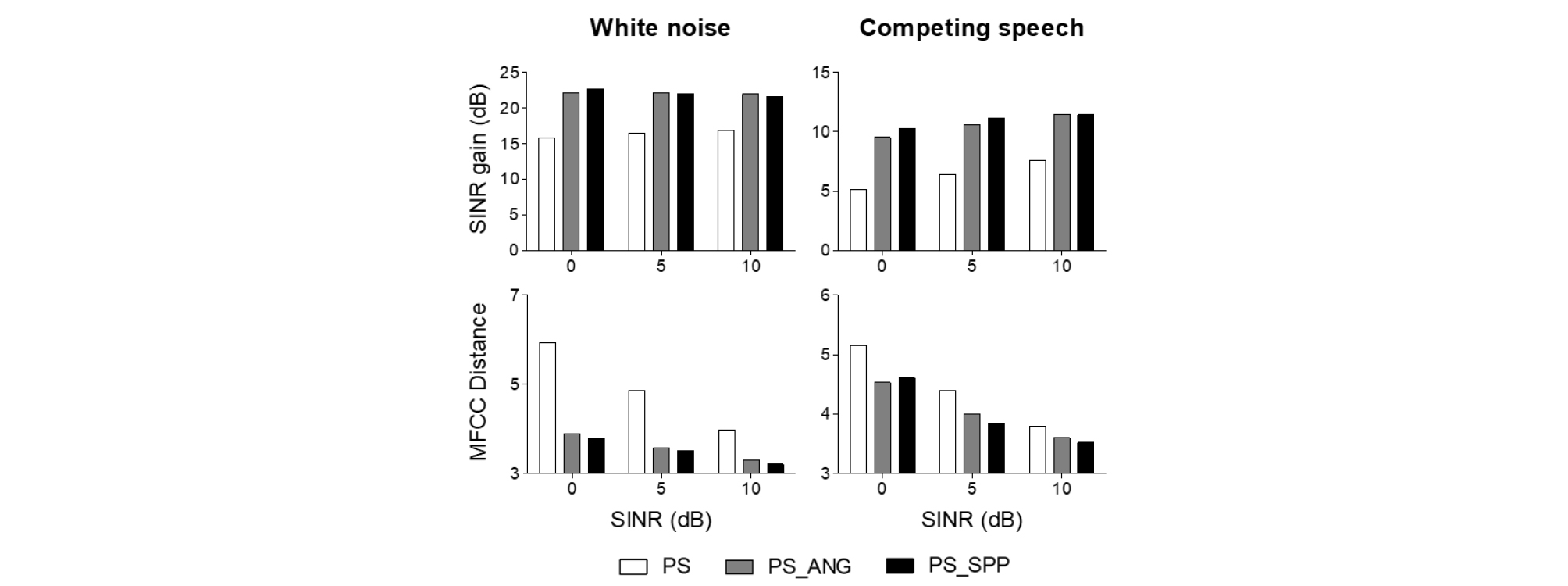
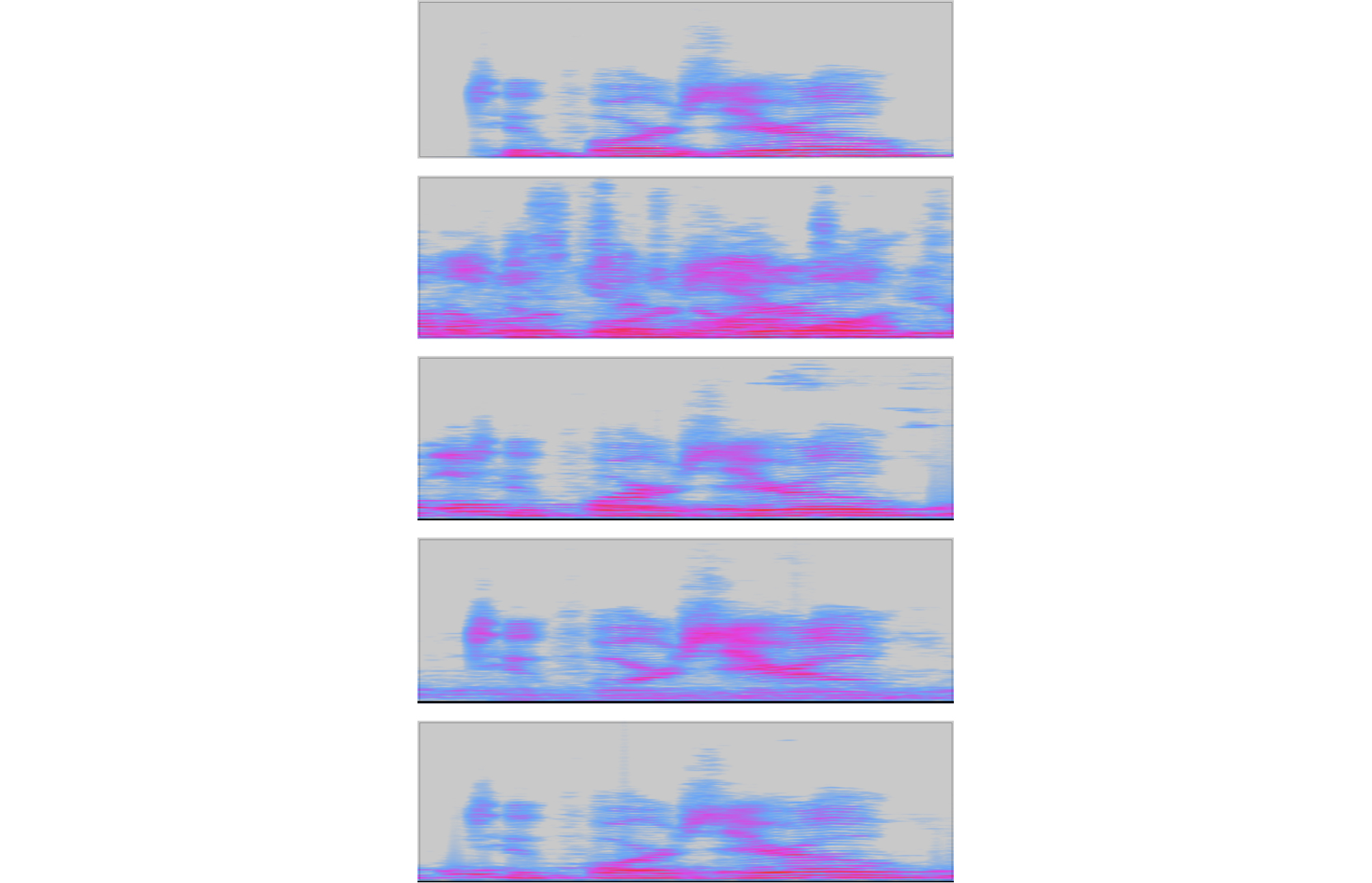
백색 잡음과 음성 간섭 잡음 두 경우 모두 주성분 다채널 위너 필터(Principal Subspace, PS)에 비해 주성분을 보정한 필터의 성능이 SINR gain과 MFCC 거리 측면에서 우수한 것으로 나타났다. 제안하는 보정 방법인 PS_SPP는 MFCC 거리 측면에서 음성 간섭 잡음 0 dB인 경우에는 PS_ANG보다 약간 성능이 떨어지는 것으로 나타나는데 이것은 낮은 SINR 환경 하에서 음성 존재 확률 추정이 저하된 결과로 추정할 수 있다. 나머지 경우는 제안하는 PS_SPP가 PS_ANG보다 우수함을 알 수 있다. Fig. 2에 음성 간섭 잡음, 0 dB SINR인 경우의 스펙트로그램을 나타내었다. 가로축은 시간을 나타내고 세로축은 0 kHz부터 8 kHz까지의 주파수를 나타낸다.